數據挖掘系列關聯規則FpGrowth算法
上一篇介紹了關聯規則挖掘的一些基本概念和經典的Apriori算法����,Aprori算法利用頻繁集的兩個特性��,過濾了很多無關的集合����,效率提高不少���,但是我們發現Apriori算法是一個候選消除算法�����,每一次消除都需要掃描一次所有數據記錄��,造成整個算法在面臨大數據集時顯得無能為力�����。今天我們介紹一個新的算法挖掘頻繁項集��,效率比Aprori算法高很多���。
FpGrowth算法通過構造一個樹結構來壓縮數據記錄���,使得挖掘頻繁項集只需要掃描兩次數據記錄���,而且該算法不需要生成候選集合���,所以效率會比較高��。我們還是以上一篇中用的數據集為例:
|
TID
|
Items
|
|
T1
|
{牛奶,面包}
|
|
T2
|
{面包,尿布,啤酒,雞蛋}
|
|
T3
|
{牛奶,尿布,啤酒,可樂}
|
|
T4
|
{面包,牛奶,尿布,啤酒}
|
|
T5
|
{面包,牛奶,尿布,可樂}
|
一��、構造FpTree
FpTree是一種樹結構�,樹結構定義如下:
樹的每一個結點代表一個項�����,這里我們先不著急看樹的結構��,我們演示一下FpTree的構造過程���,FpTree構造好后自然明白了樹的結構�。假設我們的最小絕對支持度是3���。
Step 1:掃描數據記錄�,生成一級頻繁項集�,并按出現次數由多到少排序��,如下所示:
|
Item
|
Count
|
|
牛奶
|
4
|
|
面包
|
4
|
|
尿布
|
4
|
|
啤酒
|
3
|
可以看到����,雞蛋和可樂沒有出現在上表中����,因為可樂只出現2次����,雞蛋只出現1次���,小于最小支持度�,因此不是頻繁項集�����,根據Apriori定理��,非頻繁項集的超集一定不是頻繁項集���,所以可樂和雞蛋不需要再考慮�����。
Step 2:再次掃描數據記錄��,對每條記錄中出現在Step 1產生的表中的項�,按表中的順序排序�����。初始時�����,新建一個根結點��,標記為null����;
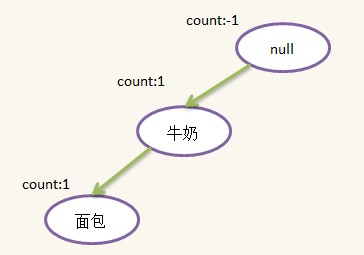
1)第一條記錄:{牛奶,面包}���,按Step 1表過濾排序得到依然為{牛奶,面包}��,新建一個結點��,idName為{牛奶}����,將其插入到根節點下�����,并設置count為1����,然后新建一個{面包}結點���,插入到{牛奶}結點下面�����,插入后如下所示:
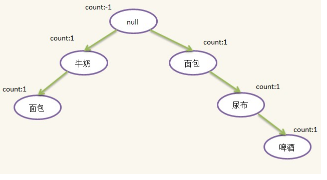
2)第二條記錄:{面包,尿布,啤酒,雞蛋}����,過濾并排序后為:{面包,尿布,啤酒}���,發現根結點沒有包含{面包}的兒子(有一個{面包}孫子但不是兒子)���,因此新建一個{面包}結點����,插在根結點下面�����,這樣根結點就有了兩個孩子����,隨后新建{尿布}結點插在{面包}結點下面����,新建{啤酒}結點插在{尿布}下面����,插入后如下所示:
3)第三條記錄:{牛奶,尿布,啤酒,可樂}��,過濾并排序后為:{牛奶,尿布,啤酒}���,這時候發現根結點有兒子{牛奶}����,因此不需要新建結點��,只需將原來的{牛奶}結點的count加1即可�����,往下發現{牛奶}結點有一個兒子{尿布}��,于是新建{尿布}結點����,并插入到{牛奶}結點下面�,隨后新建{啤酒}結點插入到{尿布}結點后面����。插入后如下圖所示:

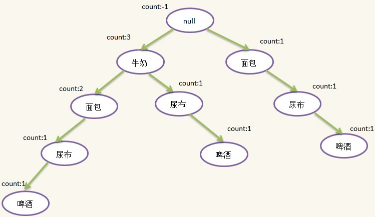
4)第四條記錄:{面包,牛奶,尿布,啤酒}�����,過濾并排序后為:{牛奶����,面包,尿布,啤酒}�,這時候發現根結點有兒子{牛奶}��,因此不需要新建結點��,只需將原來的{牛奶}結點的count加1即可����,往下發現{牛奶}結點有一個兒子{面包}��,于是也不需要新建{面包}結點����,只需將原來{面包}結點的count加1���,由于這個{面包}結點沒有兒子��,此時需新建{尿布}結點���,插在{面包}結點下面����,隨后新建{啤酒}結點�����,插在{尿布}結點下面���,插入后如下圖所示:
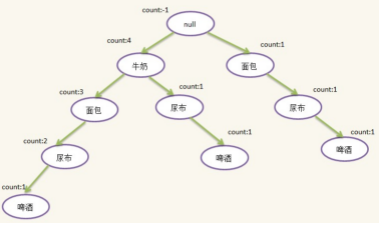
5)第五條記錄:{面包,牛奶,尿布,可樂}�����,過濾并排序后為:{牛奶�,面包,尿布}����,檢查發現根結點有{牛奶}兒子����,{牛奶}結點有{面包}兒子���,{面包}結點有{尿布}兒子��,本次插入不需要新建結點只需更新count即可����,示意圖如下:
按照上面的步驟���,我們已經基本構造了一棵FpTree(Frequent Pattern Tree)�,樹中每天路徑代表一個項集���,因為許多項集有公共項��,而且出現次數越多的項越可能是公公項��,因此按出現次數由多到少的順序可以節省空間���,實現壓縮存儲�,另外我們需要一個表頭和對每一個idName相同的結點做一個線索���,方便后面使用����,線索的構造也是在建樹過程形成的��,但為了簡化FpTree的生成過程����,我沒有在上面提到��,這個在代碼有體現的����,添加線索和表頭的Fptree如下:

至此����,整個FpTree就構造好了�,在下面的挖掘過程中我們會看到表頭和線索的作用��。
二����、利用FpTree挖掘頻繁項集
FpTree建好后��,就可以進行頻繁項集的挖掘���,挖掘算法稱為FpGrowth(Frequent Pattern Growth)算法����,挖掘從表頭header的最后一個項開始�����。
1)此處即從{啤酒}開始�����,根據{啤酒}的線索鏈找到所有{啤酒}結點����,然后找出每個{啤酒}結點的分支:{牛奶����,面包�,尿布�,啤酒:1}�����,{牛奶�,尿布����,啤酒:1}��,{面包����,尿布�,啤酒:1}�����,其中的“1”表示出現1次����,注意�,雖然{牛奶}出現4次���,但{牛奶����,面包����,尿布����,啤酒}只同時出現1次��,因此分支的count是由后綴結點{啤酒}的count決定的��,除去{啤酒}�,我們得到對應的前綴路徑{牛奶����,面包���,尿布:1}���,{牛奶�,尿布:1}��,{面包�����,尿布:1}�,根據前綴路徑我們可以生成一顆條件FpTree���,構造方式跟之前一樣��,此處的數據記錄變為:
|
TID
|
Items
|
|
T1
|
{牛奶�����,面包�����,尿布}
|
|
T2
|
{牛奶���,尿布}
|
|
T3
|
{面包�����,尿布}
|
絕對支持度依然是3�����,構造得到的FpTree為:
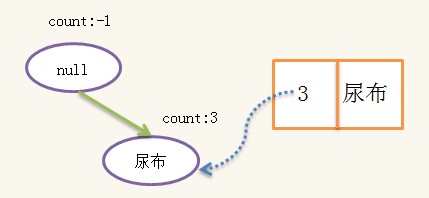
構造好條件樹后����,對條件樹進行遞歸挖掘����,當條件樹只有一條路徑時�,路徑的所有組合即為條件頻繁集���,假設{啤酒}的條件頻繁集為{S1,S2,S3}�,則{啤酒}的頻繁集為{S1+{啤酒},S2+{啤酒},S3+{啤酒}}��,即{啤酒}的頻繁集一定有相同的后綴{啤酒}��,此處的條件頻繁集為:{{}���,{尿布}}�����,于是{啤酒}的頻繁集為{{啤酒}{尿布�,啤酒}}�。
2)接下來找header表頭的倒數第二個項{尿布}的頻繁集��,同上可以得到{尿布}的前綴路徑為:{面包:1}�,{牛奶:1}��,{牛奶�����,面包:2}��,條件FpTree的數據集為:
|
TID
|
Items
|
|
T1
|
{面包}
|
|
T2
|
{牛奶}
|
|
T3
|
{牛奶�����,面包}
|
|
T4
|
{牛奶����,面包}
|
注意{牛奶�����,面包:2}����,即{牛奶�,面包}的count為2���,所以在{牛奶���,面包}重復了兩次�,這樣做的目的是可以利用之前構造FpTree的算法來構造條件Fptree���,不過這樣效率會降低�,試想如果{牛奶�,面包}的count為20000���,那么就需要展開成20000條記錄����,然后進行20000次count更新��,而事實上只需要對count更新一次到20000即可����。這是實現上的優化細節���,實踐中當注意���。構造的條件FpTree為:
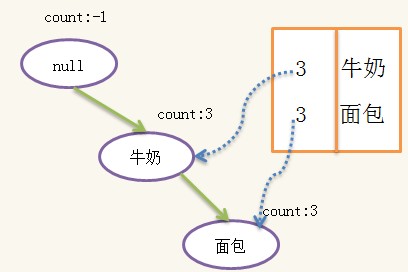
這顆條件樹已經是單一路徑�����,路徑上的所有組合即為條件頻繁集:{{}�����,{牛奶}�,{面包}��,{牛奶��,面包}}����,加上{尿布}后�,又得到一組頻繁項集{{尿布}�����,{牛奶�,尿布}�����,{面包�,尿布}����,{牛奶�,面包��,尿布}}���,這組頻繁項集一定包含一個相同的后綴:{尿布}��,并且不包含{啤酒}�,因此這一組頻繁項集與上一組不會重復�。
重復以上步驟�����,對header表頭的每個項進行挖掘��,即可得到整個頻繁項集����,可以證明(嚴謹的算法和證明可見參考文獻[1])�,頻繁項集即不重復也不遺漏���。
程序的實現代碼還是放在我的github上���,這里看一下運行結果:

另外我下載了一個購物籃的數據集���,數據量較大��,測試了一下FpGrowth的效率還是不錯的�����。FpGrowth算法的平均效率遠高于Apriori算法����,但是它并不能保證高效率�,它的效率依賴于數據集�����,當數據集中的頻繁項集的沒有公共項時�,所有的項集都掛在根結點上��,不能實現壓縮存儲��,而且Fptree還需要其他的開銷�,需要存儲空間更大��,使用FpGrowth算法前�,對數據分析一下����,看是否適合用FpGrowth算法��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;












 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
