數據挖掘系列使用weka做關聯規則挖掘
前面幾篇介紹了關聯規則的一些基本概念和兩個基本算法����,但實際在商業應用中�,寫算法反而比較少�,理解數據��,把握數據��,利用工具才是重要的�����,前面的基礎篇是對算法的理解�����,這篇將介紹開源利用數據挖掘工具weka進行管理規則挖掘��。
weka數據集格式arff
arff標準數據集簡介
weka的數據文件后綴為arff(Attribute-Relation File Format�,即屬性關系文件格式)�����,arff文件分為注釋���、關系名��、屬性名����、數據域幾大部分���,注釋用百分號開頭%�,關系名用@relation申明��,屬性用@attribute什么��,數據域用@data開頭��,看這個示例數據集(安裝weka后���,可在weka的安裝目錄/data下找到weather.numeric.arff):
%weather dataset
@relation weather
@attribute outlook {sunny, overcast, rainy}
@attribute temperature numeric
@attribute humidity numeric
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
@data
sunny,85,85,FALSE,no
sunny,80,90,TRUE,no
overcast,83,86,FALSE,yes
rainy,70,96,FALSE,yes
rainy,68,80,FALSE,yes
rainy,65,70,TRUE,no
overcast,64,65,TRUE,yes
sunny,72,95,FALSE,no
sunny,69,70,FALSE,yes
rainy,75,80,FALSE,yes
sunny,75,70,TRUE,yes
overcast,72,90,TRUE,yes
overcast,81,75,FALSE,yes
rainy,71,91,TRUE,no
當數據是數值型�����,在屬性名的后面加numeric�,如果是離散值(枚舉值)���,就用一個大括號將值域列出來����。@data下一行后為數據記錄��,數據為矩陣形式����,即每一個的數據元素個數相等��,若有缺失值��,就用問號?表示�。
arff稀疏數據集
我們做關聯規則挖掘���,比如購物籃分析����,我們的購物清單數據肯定是相當稀疏的���,超市的商品種類有上10000種�����,而每個人買東西只會買幾種商品�����,這樣如果用矩陣形式表示數據顯然浪費了很多的存儲空間�����,我們需要用稀疏數據表示�,看我們的購物清單示例(basket.txt):
數據集的每一行表示一個去重后的購物清單�,進行關聯規則挖掘時��,我們可以先把商品名字映射為id號�,挖掘的過程只有id號就是了����,到規則挖掘出來之后再轉回商品名就是了����,retail.txt是一個轉化為id號的零售數據集��,數據集的前面幾行如下:
這個數據集的商品有16469個�,一個購物的商品數目遠少于商品中數目���,因此要用稀疏數據表����,weka支持稀疏數據表示���,但我在運用apriori算法時有問題��,先看一下weka的稀疏數據要求:稀疏數據和標準數據的其他部分都一樣�����,唯一不同就是@data后的數據記錄�����,示例如下(basket.arff):
可以看到
表示為了:
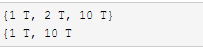
稀疏數據的表示格式為:{<屬性列號><空格><值>,...,<屬性列號><空格><值>}����,注意每條記錄要用大括號��,屬性列號不是id號�,屬性列號是從0開始的�,即第一個@attribute 后面的屬性是第0個屬性��,T表示數據存在���。
規則挖取
我們先用標準數據集normalBasket.arff[1]試一下���,weka的apriori算法和FPGrowth算法�。
1����、安裝好weka后�����,打開選擇Explorer
2���、打開文件
3�、選擇關聯規則挖掘���,選擇算法
4��、設置參數
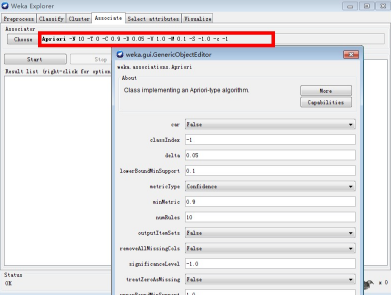
參數主要是選擇支持度(lowerBoundMinSupport)��,規則評價機制metriType(見上一篇)及對應的最小值���,參數設置說明如下[2]:
1. car 如果設為真��,則會挖掘類關聯規則而不是全局關聯規則�����。
2. classindex 類屬性索引����。如果設置為-1�,最后的屬性被當做類屬性����。
3. delta 以此數值為迭代遞減單位�����。不斷減小支持度直至達到最小支持度或產生了滿足數量要求的規則�����。
4. lowerBoundMinSupport 最小支持度下界���。
5. metricType 度量類型���。設置對規則進行排序的度量依據�����?��?梢允牵褐眯哦龋?a href='/map/guanlianguize/' style='color:#000;font-size:inherit;'>關聯規則只能用置信度挖掘)��,提升度(lift)���,杠桿率(leverage)��,確信度(conviction)�����。
在 Weka中設置了幾個類似置信度(confidence)的度量來衡量規則的關聯程度���,它們分別是:
a) Lift : P(A,B)/(P(A)P(B)) Lift=1時表示A和B獨立��。這個數越大(>1)��,越表明A和B存在于一個購物籃中不是偶然現象,有較強的關聯度.
b) Leverage :P(A,B)-P(A)P(B)Leverage=0時A和B獨立���,Leverage越大A和B的關系越密切
c) Conviction:P(A)P(!B)/P(A,!B) (!B表示B沒有發生) Conviction也是用來衡量A和B的獨立性���。從它和lift的關系(對B取反����,代入Lift公式后求倒數)可以看出�����,這個值越大, A����、B越關聯�。
6. minMtric 度量的最小值�����。
7. numRules 要發現的規則數���。
8. outputItemSets 如果設置為真���,會在結果中輸出項集���。
9. removeAllMissingCols 移除全部為缺省值的列�����。
10. significanceLevel 重要程度���。重要性測試(僅用于置信度)���。
11. upperBoundMinSupport 最小支持度上界�����。 從這個值開始迭代減小最小支持度�。
12. verbose 如果設置為真�����,則算法會以冗余模式運行����。
設置好參數后點擊start運行可以看到Apriori的運行結果:
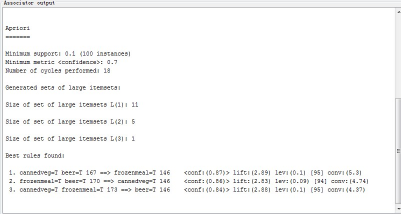
FPGrowth運行的結果是一樣的:
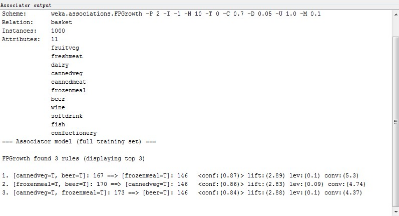
每條規則都帶有出現次數����、自信度����、相關度等數值��。
下面測一個大一點的數據集retail.arff[1](retail.arff是由retail.txt轉化而來��,為了不造成誤解��,我在id好前加了一個"I"���,比如2變為I2)�,這個數據用的稀疏數據表示方法�,數據記錄有88162條�,用Apriori算法在我的2G電腦上跑不出來�����,直接內存100%��,用FPGrowth可以輕松求出��,看一下運行結果:
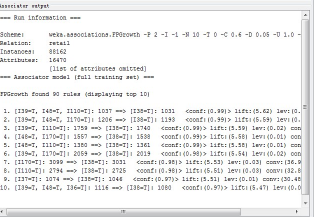
其他參數可以自己調整比較�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;














 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
