淺談數據挖掘中的關聯規則挖掘
數據挖掘是指以某種方式分析數據源�����,從中發現一些潛在的有用的信息��,所以數據挖掘又稱作知識發現���,而關聯規則挖掘則是數據挖掘中的一個很重要的課題����,顧名思義���,它是從數據背后發現事物之間可能存在的關聯或者聯系����。舉個最簡單的例子�����,比如通過調查商場里顧客買的東西發現�����,30%的顧客會同時購買床單和枕套�,而購買床單的人中有80%購買了枕套���,這里面就隱藏了一條關聯:床單—>枕套����,也就是說很大一部分顧客會同時購買床單和枕套��,那么對于商場來說�����,可以把床單和枕套放在同一個購物區����,那樣就方便顧客進行購物了����。下面來討論一下關聯規則中的一些重要概念以及如何從數據中挖掘出關聯規則�����。
一.關聯規則挖掘中的幾個概念
先看一個簡單的例子����,假如有下面數據集�����,每一組數據ti表示不同的顧客一次在商場購買的商品的集合:
假如有一條規則:牛肉—>雞肉��,那么同時購買牛肉和雞肉的顧客比例是3/7�,而購買牛肉的顧客當中也購買了雞肉的顧客比例是3/4�。這兩個比例參數是很重要的衡量指標��,它們在關聯規則中稱作支持度(support)和置信度(confidence)�。對于規則:牛肉—>雞肉����,它的支持度為3/7���,表示在所有顧客當中有3/7同時購買牛肉和雞肉��,其反應了同時購買牛肉和雞肉的顧客在所有顧客當中的覆蓋范圍����;它的置信度為3/4��,表示在買了牛肉的顧客當中有3/4的人買了雞肉�,其反應了可預測的程度����,即顧客買了牛肉的話有多大可能性買雞肉��。其實可以從統計學和集合的角度去看這個問題���, 假如看作是概率問題�����,則可以把“顧客買了牛肉之后又多大可能性買雞肉”看作是條件概率事件���,而從集合的角度去看��,可以看下面這幅圖:
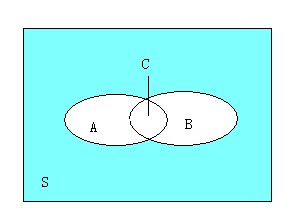
上面這副圖可以很好地描述這個問題����,S表示所有的顧客����,而A表示買了牛肉的顧客��,B表示買了雞肉的顧客����,C表示既買了牛肉又買了雞肉的顧客�。那么C.count/S.count=3/7���,C.count/A.count=3/4��。
在數據挖掘中��,例如上述例子中的所有商品集合I={牛肉��,雞肉�,牛奶��,奶酪���,靴子���,衣服}稱作項目集合�����,每位顧客一次購買的商品集合ti稱為一個事務��,所有的事務T={t1,t2,....t7}稱作事務集合�,并且滿足ti是I的真子集��。一條關聯規則是形如下面的蘊含式:
X—>Y�����,X�,Y滿足:X����,Y是I的真子集���,并且X和Y的交集為空集
其中X稱為前件�,Y稱為后件�。
對于規則X—>Y����,根據上面的例子可以知道它的支持度(support)=(X,Y).count/T.count����,置信度(confidence)=(X,Y).count/X.count ���。其中(X,Y).count表示T中同時包含X和Y的事務的個數��,X.count表示T中包含X的事務的個數�。
關聯規則挖掘則是從事務集合中挖掘出滿足支持度和置信度最低閾值要求的所有關聯規則��,這樣的關聯規則也稱強關聯規則��。
對于支持度和置信度�����,我們需要正確地去看待這兩個衡量指標�����。一條規則的支持度表示這條規則的可能性大小��,如果一個規則的支持度很小��,則表明它在事務集合中覆蓋范圍很小����,很有可能是偶然發生的�����;如果置信度很低���,則表明很難根據X推出Y�。根據條件概率公式P(Y|X)=P(X,Y)/P(X)�����,即P(X,Y)=P(Y|X)*P(X)
P(Y|X)代表著置信度�����,P(X,Y)代表著支持度�����,所以對于任何一條關聯規則置信度總是大于等于支持度的����。并且當支持度很高時��,此時的置信度肯定很高����,它所表達的意義就不是那么有用了����。這里要注意的是支持度和置信度只是兩個參考值而已����,并不是絕對的�����,也就是說假如一條關聯規則的支持度和置信度很高時�,不代表這個規則之間就一定存在某種關聯����。舉個最簡單的例子���,假如X和Y是最近的兩個比較熱門的商品�����,大家去商場都要買�,比如某款手機和某款衣服���,都是最新款的��,深受大家的喜愛�,那么這條關聯規則的支持度和置信度都很高���,但是它們之間沒有必然的聯系�。然而當置信度很高時��,支持度仍然具有參考價值�,因為當P(Y|X)很高時�����,可能P(X)很低�����,此時P(X,Y)也許會很低����。
二.關聯規則挖掘的原理和過程
從上面的分析可知�����,關聯規則挖掘是從事務集合中挖掘出這樣的關聯規則:它的支持度和置信度大于最低閾值(minsup,minconf)����,這個閾值是由用戶指定的���。根據支持度=(X,Y).count/T.count�����,置信度=(X,Y).count/X.count ����,要想找出滿足條件的關聯規則��,首先必須找出這樣的集合F=X U Y ����,它滿足F.count/T.count ≥ minsup���,其中F.count是T中包含F的事務的個數����,然后再從F中找出這樣的蘊含式X—>Y���,它滿足(X,Y).count/X.count ≥ minconf���,并且X=F-Y��。我們稱像F這樣的集合稱為頻繁項目集���,假如F中的元素個數為k���,我們稱這樣的頻繁項目集為k-頻繁項目集�,它是項目集合I的子集���。所以關聯規則挖掘可以大致分為兩步:
1)從事務集合中找出頻繁項目集��;
2)從頻繁項目集合中生成滿足最低置信度的關聯規則����。
最出名的關聯規則挖掘算法是Apriori算法�,它主要利用了向下封閉屬性:如果一個項集是頻繁項目集�����,那么它的非空子集必定是頻繁項目集�����。它先生成1-頻繁項目集����,再利用1-頻繁項目集生成2-頻繁項目集���。���。�。然后根據2-頻繁項目集生成3-頻繁項目集����。�����。����。依次類推���,直至生成所有的頻繁項目集�����,然后從頻繁項目集中找出符合條件的關聯規則�����。
下面來討論一下頻繁項目集的生成過程�����,它的原理是根據k-頻繁項目集生成(k+1)-頻繁項目集����。因此首先要做的是找出1-頻繁項目集����,這個很容易得到���,只要循環掃描一次事務集合統計出項目集合中每個元素的支持度�����,然后根據設定的支持度閾值進行篩選�����,即可得到1-頻繁項目集��。下面證明一下為何可以通過k-頻繁項目集生成(k+1)-頻繁項目集:
假設某個項目集S={s1��,s2...�����,sn}是頻繁項目集��,那么它的(n-1)非空子集{s1�����,s2�����,...sn-1}�����,{s1����,s2����,...sn-2����,sn}...{s2�����,s3��,...sn}必定都是頻繁項目集�����,通過觀察�,任何一個含有n個元素的集合A={a1�����,a2��,...an}����,它的(n-1)非空子集必行包含兩項{a1���,a2���,...an-2��,an-1}和 {a1��,a2��,...an-2���,an}���,對比這兩個子集可以發現�,它們的前(n-2)項是相同的�,它們的并集就是集合A����。對于2-頻繁項目集���,它的所有1非空子集也必定是頻繁項目集�����,那么根據上面的性質��,對于2-頻繁項目集中的任一個��,在1-頻繁項目集中必定存在2個集合的并集與它相同�。因此在所有的1-頻繁項目集中找出只有最后一項不同的集合�����,將其合并����,即可得到所有的包含2個元素的項目集�����,得到的這些包含2個元素的項目集不一定都是頻繁項目集�����,所以需要進行剪枝��。剪枝的辦法是看它的所有1非空子集是否在1-頻繁項目集中����,如果存在1非空子集不在1-頻繁項目集中��,則將該2項目集剔除���。經過該步驟之后�,剩下的則全是頻繁項目集���,即2-頻繁項目集�。依次類推����,可以生成3-頻繁項目集���。���。直至生成所有的頻繁項目集��。
得到頻繁項目集之后��,則需要從頻繁項目集中找出符合條件的關聯規則��。最簡單的辦法是:遍歷所有的頻繁項目集�����,然后從每個項目集中依次取1���、2��、...k個元素作為后件����,該項目集中的其他元素作為前件�����,計算該規則的置信度進行篩選即可�。這樣的窮舉效率顯然很低��。假如對于一個頻繁項目集f����,可以生成下面這樣的關聯規則:
(f-β)—>β
那么這條規則的置信度=f.count/(f-β).count
根據這個置信度計算公式可知��,對于一個頻繁項目集f.count是不變的�,而假設該規則是強關聯規則����,則(f-βsub)—>βsub也是強關聯規則�,其中βsub是β的子集���,因為(f-βsub).count肯定小于(f-β).count�。即給定一個頻繁項目集f���,如果一條強關聯規則的后件為β���,那么以β的非空子集為后件的關聯規則都是強關聯規則�����。所以可以先生成所有的1-后件(后件只有一項)強關聯規則�����,然后再生成2-后件強關聯規則�����,依次類推���,直至生成所有的強關聯規則�。
下面舉例說明Apiori算法的具體流程:
假如有項目集合I={1�����,2��,3����,4����,5}�,有事務集T:
1,2,3
1,2,4
1,3,4
1,2,3,5
1,3,5
2,4,5
1,2,3,4
設定minsup=3/7����,misconf=5/7���。
首先:生成頻繁項目集:
1-頻繁項目集:{1}�,{2}���,{3}����,{4}���,{5}
生成2-頻繁項目集:
根據1-頻繁項目集生成所有的包含2個元素的項目集:任意取兩個只有最后一個元素不同的1-頻繁項目集����,求其并集��,由于每個1-頻繁項目集元素只有一個�����,所以生成的項目集如下:
{1��,2}���,{1��,3}���,{1����,4}�,{1�����,5}
{2�����,3}����,{2��,4}����,{2���,5}
{3�,4}���,{3�����,5}
{4�,5}
計算它們的支持度�����,發現只有{1�����,2}�����,{1�,3}�,{1���,4}�����,{2��,3}����,{2�,4}����,{2����,5}的支持度滿足要求�����,因此求得2-頻繁項目集:
{1����,2}���,{1���,3}���,{1�,4}�,{2����,3}�,{2��,4}
生成3-頻繁項目集:
因為{1�����,2}�����,{1����,3}�����,{1��,4}除了最后一個元素以外都相同���,所以求{1���,2}�����,{1����,3}的并集得到{1����,2��,3}����, {1�����,2}和{1�,4}的并集得到{1��,2�,4}����,{1���,3}和{1�,4}的并集得到{1���,3�����,4}��。但是由于{1����,3��,4}的子集{3����,4}不在2-頻繁項目集中���,所以需要把{1���,3�,4}剔除掉�。然后再來計算{1�����,2���,3}和{1����,2����,4}的支持度�,發現{1�,2�,3}的支持度為3/7 ����,{1����,2����,4}的支持度為2/7���,所以需要把{1��,2�����,4}剔除��。同理可以對{2����,3}���,{2����,4}求并集得到{2���,3��,4} ����,但是{2�,3����,4}的支持度不滿足要求��,所以需要剔除掉����。
因此得到3-頻繁項目集:{1���,2��,3}�。
到此頻繁項目集生成過程結束��。注意生成頻繁項目集的時候���,頻繁項目集中的元素個數最大值為事務集中事務中含有的最大元素個數�,即若事務集中事務包含的最大元素個數為k����,那么最多能生成k-頻繁項目集�����,這個原因很簡單��,因為事務集合中的所有事務都不包含(k+1)個元素�����,所以不可能存在(k+1)-頻繁項目集�����。在生成過程中�����,若得到的頻繁項目集個數小于2���,生成過程也可以結束了���。
現在需要生成強關聯規則:
這里只說明3-頻繁項目集生成關聯規則的過程:
對于集合{1�,2��,3}
先生成1-后件的關聯規則:
(1��,2)—>3����, 置信度=3/4
(1���,3)—>2�����, 置信度=3/5
(2�����,3)—>1 置信度=3/3
(1��,3)—>2的置信度不滿足要求����,所以剔除掉��。因此得到1后件的集合{1}�����,{3}�,然后再以{1���,3}作為后件
2—>1�����,3 置信度=3/5不滿足要求����,所以對于3-頻繁項目集生成的強關聯規則為:(1�����,2)—>3和(2��,3)—>1��。
算法實現:
/*Apriori算法 2012.10.31*/
#include <iostream>
#include <vector>
#include <map>
#include <string>
#include <algorithm>
#include <cmath>
using namespace std;
vector<string> T; //保存初始輸入的事務集
double minSup,minConf; //用戶設定的最小支持度和置信度
map<string,int> mp; //保存項目集中每個元素在事務集中出現的次數
vector< vector<string> > F; //存放頻繁項目集
vector<string> R; //存放關聯規則
void initTransactionSet() //獲取事務集
{
int n;
cout<<"請輸入事務集的個數:"<<endl;
cin>>n;
getchar();
cout<<"請輸入事務集:"<<endl;
while(n--)
{
string str;
getline(cin,str); //輸入的事務集中每個元素以空格隔開,并且只能輸入數字
T.push_back(str);
}
cout<<"請輸入最小支持度和置信度:"<<endl; //支持度和置信度為小數表示形式
cin>>minSup>>minConf;
}
vector<string> split(string str,char ch)
{
vector<string> v;
int i,j;
i=0;
while(i<str.size())
{
if(str[i]==ch)
i++;
else
{
j=i;
while(j<str.size())
{
if(str[j]!=ch)
j++;
else
break;
}
string temp=str.substr(i,j-i);
v.push_back(temp);
i=j+1;
}
}
return v;
}
void genarateOneFrequenceSet() //生成1-頻繁項目集
{
int i,j;
vector<string> f; //存儲1-頻繁項目集
for(i=0;i<T.size();i++)
{
string t = T[i];
vector<string> v=split(t,' '); //將輸入的事務集進行切分����,如輸入1 2 3�,切分得到"1","2","3"
for(j=0;j<v.size();j++) //統計每個元素出現的次數����,注意map默認按照key的升序排序
{
mp[v[j]]++;
}
}
for(map<string,int>::iterator it=mp.begin();it!=mp.end();it++) //剔除不滿足最小支持度要求的項集
{
if( (*it).second >= minSup*T.size())
{
f.push_back((*it).first);
}
}
F.push_back(T); //方便用F[1]表示1-頻繁項目集
if(f.size()!=0)
{
F.push_back(f);
}
}
bool judgeItem(vector<string> v1,vector<string> v2) //判斷v1和v2是否只有最后一項不同
{
int i,j;
i=0;
j=0;
while(i<v1.size()-1&&j<v2.size()-1)
{
if(v1[i]!=v2[j])
return false;
i++;
j++;
}
return true;
}
bool judgeSubset(vector<string> v,vector<string> f) //判斷v的所有k-1子集是否在f中
{
int i,j;
bool flag=true;
for(i=0;i<v.size();i++)
{
string str;
for(j=0;j<v.size();j++)
{
if(j!=i)
str+=v[j]+" ";
}
str=str.substr(0,str.size()-1);
vector<string>::iterator it=find(f.begin(),f.end(),str);
if(it==f.end())
flag=false;
}
return flag;
}
int calculateSupportCount(vector<string> v) //計算支持度計數
{
int i,j;
int count=0;
for(i=0;i<T.size();i++)
{
vector<string> t=split(T[i],' ');
for(j=0;j<v.size();j++)
{
vector<string>::iterator it=find(t.begin(),t.end(),v[j]);
if(it==t.end())
break;
}
if(j==v.size())
count++;
}
return count;
}
bool judgeSupport(vector<string> v) //判斷一個項集的支持度是否滿足要求
{
int count=calculateSupportCount(v);
if(count >= ceil(minSup*T.size()))
return true;
return false;
}
void generateKFrequenceSet() //生成k-頻繁項目集
{
int k;
for(k=2;k<=mp.size();k++)
{
if(F.size()< k) //如果Fk-1為空���,則退出
break;
else //根據Fk-1生成Ck候選項集
{
int i,j;
vector<string> c;
vector<string> f=F[k-1];
for(i=0;i<f.size()-1;i++)
{
vector<string> v1=split(f[i],' ');
for(j=i+1;j<f.size();j++)
{
vector<string> v2=split(f[j],' ');
if(judgeItem(v1,v2)) //如果v1和v2只有最后一項不同����,則進行連接
{
vector<string> tempVector=v1;
tempVector.push_back(v2[v2.size()-1]);
sort(tempVector.begin(),tempVector.end()); //對元素排序��,方便判斷是否進行連接
//剪枝的過程
//判斷 v1的(k-1)的子集是否都在Fk-1中以及是否滿足最低支持度
if(judgeSubset(tempVector,f)&&judgeSupport(tempVector))
{
int p;
string tempStr;
for(p=0;p<tempVector.size()-1;p++)
tempStr+=tempVector[p]+" ";
tempStr+=tempVector[p];
c.push_back(tempStr);
}
}
}
}
if(c.size()!=0)
F.push_back(c);
}
}
}
vector<string> removeItemFromSet(vector<string> v1,vector<string> v2) //從v1中剔除v2
{
int i;
vector<string> result=v1;
for(i=0;i<v2.size();i++)
{
vector<string>::iterator it= find(result.begin(),result.end(),v2[i]);
if(it!=result.end())
result.erase(it);
}
return result;
}
string getStr(vector<string> v1,vector<string> v2) //根據前件和后件得到規則
{
int i;
string rStr;
for(i=0;i<v1.size();i++)
rStr+=v1[i]+" ";
rStr=rStr.substr(0,rStr.size()-1);
rStr+="->";
for(i=0;i<v2.size();i++)
rStr+=v2[i]+" ";
rStr=rStr.substr(0,rStr.size()-1);
return rStr;
}
void ap_generateRules(string fs)
{
int i,j,k;
vector<string> v=split(fs,' ');
vector<string> h;
vector< vector<string> > H; //存放所有的后件
int fCount=calculateSupportCount(v); //f的支持度計數
for(i=0;i<v.size();i++) //先生成1-后件關聯規則
{
vector<string> temp=v;
temp.erase(temp.begin()+i);
int aCount=calculateSupportCount(temp);
if( fCount >= ceil(aCount*minConf)) //如果滿足置信度要求
{
h.push_back(v[i]);
string tempStr;
for(j=0;j<v.size();j++)
{
if(j!=i)
tempStr+=v[j]+" ";
}
tempStr=tempStr.substr(0,tempStr.size()-1);
tempStr+="->"+v[i];
R.push_back((tempStr));
}
}
H.push_back(v);
if(h.size()!=0)
H.push_back(h);
for(k=2;k<v.size();k++) //生成k-后件關聯規則
{
h=H[k-1];
vector<string> addH;
for(i=0;i<h.size()-1;i++)
{
vector<string> v1=split(h[i],' ');
for(j=i+1;j<h.size();j++)
{
vector<string> v2=split(h[j],' ');
if(judgeItem(v1,v2))
{
vector<string> tempVector=v1;
tempVector.push_back(v2[v2.size()-1]); //得到后件集合
sort(tempVector.begin(),tempVector.end());
vector<string> filterV=removeItemFromSet(v,tempVector); //得到前件集合
int aCount=calculateSupportCount(filterV); //計算前件支持度計數
if(fCount >= ceil(aCount*minConf)) //如果滿足置信度要求
{
string rStr=getStr(filterV,tempVector); //根據前件和后件得到規則
string hStr;
for(int s=0;s<tempVector.size();s++)
hStr+=tempVector[s]+" ";
hStr=hStr.substr(0,hStr.size()-1);
addH.push_back(hStr); //得到一個新的后件集合
R.push_back(rStr);
}
}
}
}
if(addH.size()!=0) //將所有的k-后件集合加入到H中
H.push_back(addH);
}
}
void generateRules() //生成關聯規則
{
int i,j,k;
for(k=2;k<F.size();k++)
{
vector<string> f=F[k];
for(i=0;i<f.size();i++)
{
string str=f[i];
ap_generateRules(str);
}
}
}
void outputFrequenceSet() //輸出頻繁項目集
{
int i,k;
if(F.size()==1)
{
cout<<"無頻繁項目集!"<<endl;
return;
}
for(k=1;k<F.size();k++)
{
cout<<k<<"-頻繁項目集:"<<endl;
vector<string> f=F[k];
for(i=0;i<f.size();i++)
cout<<f[i]<<endl;
}
}
void outputRules() //輸出關聯規則
{
int i;
cout<<"關聯規則:"<<endl;
for(i=0;i<R.size();i++)
{
cout<<R[i]<<endl;
}
}
void Apriori()
{
initTransactionSet();
genarateOneFrequenceSet();
generateKFrequenceSet();
outputFrequenceSet();
generateRules();
outputRules();
}
int main(int argc, char *argv[])
{
Apriori();
return 0;
}
測試數據:
7
1 2 3
1 4
4 5
1 2 4
1 2 6 4 3
2 6 3
2 3 6
0.3 0.8
運行結果:
1-頻繁項目集:
1
2
3
4
6
2-頻繁項目集:
1 2
1 4
2 3
2 6
3 6
3-頻繁項目集:
2 3 6
關聯規則:
3->2
2->3
6->2
6->3
3 6->2
2 6->3
6->2 3
請按任意鍵繼續. . .
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
