調查數據的加權處理技術
很多人在進行統計分析和市場研究的時候�,都涉及到對數據進行加權的問題����,這是一個搞數據分析和從事市場研究的人都會碰到的問題����,需要大家正確理解并解釋����,并采用合理的操作技術和處理方法��。
什么是加權呢����? 簡單地說����,就是要“讓一些人變得比另一些人更重要���!”
要能夠比較好的理解加權���,首先你要了解抽樣設計��,特別是設計權數:每個樣本單位所代表的被調查總體的單位數����。設計權數由抽樣設計決定,用Wd表示��。
設計權數Wd=1/入樣概率�;
入樣概率:在抽樣設計中����,如果一個樣本的入樣概率=1/50���,那么該樣本的設計權數=50���。也就是說���,這個樣本代表了總體中的50個單位�。
關于自加權抽樣設計:如果所用樣本的設計權數是相等的�����,那么這樣的抽樣設計是自加權的��。也就是說����,總體中的每個單元被抽中的可能性相等��,具有等可能性����、具有相等的入樣概率��。如果是自加權的�����,在總體均值�����、比例估計時不用考慮設計權數�����,對總量的估計只要擴大樣本�。
滿足自加權的抽樣設計:等概率抽樣���、簡單隨機抽樣�����、系統抽樣��、分層抽樣—各層大小成比例�����,每層內簡單隨機抽樣����、多階段抽樣—最后階段等概率���,其它階段與單位大小成比例概率抽樣��。
不等概率抽樣往往不滿足自加權�����,對于不等概率抽樣�,正確使用設計權數就尤為重要了����!
下面我們看看如何進行加權處理��!
加權:通過對總體中的各個樣本設置不同的數值系數(即加權因子-權重)����,使樣本呈現希望的相對重要性程度��;
基本加權等于:設計加權=某個變量或指標的期望比例/該變量或指標的實際比例����;
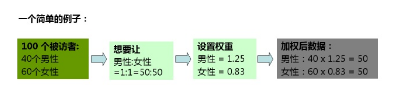
什么情況下要進行加權�?
情景1:我們在抽樣調查得到的樣本結構與總體人口統計結構狀況不相符����,我們可以通過加權來消除/還原這種結構差異�,達到糾偏的目的����;
例如����,在城市和農村各調查300樣本�����,城市與農村人口比例“城市:農村=1:2”(假設)�,在分析時我們希望將城市和農場看作一個整體�,這時候我們就可以賦予農村樣本一個2倍于城市樣本的權重��;
情景2:除了人口統計結構��,有時候我們在調查樣本的某些變量或指標上樣本的代表性可能也會相對總體的實際狀況過高/過低���,此時����,需要加權進行調整����;
這類不匹配大多是我們“故意”而為(通過“追加”樣本實現)�,比如在配額抽樣的時候�����,設置配額要求某類被訪者對某產品的使用者必須達到50%��,但實際情況是總體市場中實際使用者僅有10%����;
有時�����,則是“非情愿”的出現����,比如設置了能反映總體的配額比例����,但實際操作卻出現了比例偏高/偏低��;
情景3:在樣本組配額實驗設計中����,進行不同子總體對比檢驗���,也會通過加權來調整不同組間的樣本屬性不相匹配的情形(通常設有相同的配額�,但執行有可能會出現差異)��;通常�����,加權對結果產生的差異很小����,更多的是對結果從準確度上進行修飾�;
情景4:所測試樣本出現了較多的缺失值���,需要加權來糾正結果���;對于面向特定客戶的專項研究����,在調查前基本都協議有要完成的樣本量��,故這種情形較少����;
加權方法:
采用因子加權:對滿足特定變量或指標的所有樣本賦予一個權重�,通常用于提高樣本中具有某種特性的被訪者的重要性����;例如�,研究一種香煙的口味是否需要改變�,那么不同程度吸食者的觀點也應該有不同的重要性對待:例如:重度吸食者=3��,經常吸食者=2�,偶爾/不抽煙=1�,記?���。簩嶋H應用時候��,如果“經常/偶爾”的基數足夠大���,往往單獨分析��,不進行加權處理��;
采用目標加權:對某一特定樣本組賦權��,以達到們預期的特定目標�����;例如:我們想要:品牌A的20%使用者 = 品牌B的50%使用者�;或者品牌A的20%使用者 = 使用品牌A的80%非使用者���;
采用輪廓加權:多因素加權��,因子/目標加權不同(一維的)�����,輪廓加權應用于對調查樣本相互關系不明確的多個屬性加權����;面對多個需要賦權的屬性�,輪廓加權過程應該同時進行��,以盡可能少的對變量產生扭曲

我們應該知道�����,無論加權的動機是什么�����,但操作過程是一樣的:
依不同屬性變量/指標將樣本分為多個組(加權組)���,然后根據所希望各個組代表的個體規模賦予不同的權重�;即明確分析子集/樣本組���,通常����,經常以人口結構變量��、地域變量作為分類指標���;明確各個分析子集/樣本組中個體的代表性強弱(權重)�����;
加權是在數據收集結束后采取的數據“糾偏”行為����,但一定要清醒的知道:配額設置不合適�����、FW執行差或其他錯誤而造成的“不好”的原始數據收集�,即使加權也一定是“無效的”����;
“提前避免錯誤/失誤發生��,總好過事后的任何補救�!”
事后加權案例:
例如:我們為了研究��,得到某小公司職員吸煙習慣的信息���,進行了一項調查�。從N=78個人的目錄中抽出了一個n=25人的簡單隨機樣本����。在調查的設計階段��,并沒有可用于分層的輔助信息���。在收集關于吸煙習慣的信息的同時�,還收集了每個回答者的年齡和性別情況�?����?偣灿衝r=15個人作出了回答���。
由此得到樣本數據的下列分布:
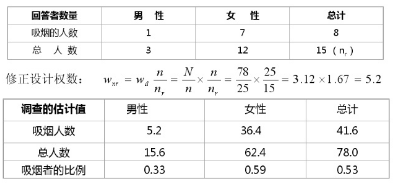
假設我們估計知道某公司約有16個男性職員和62個女性職員���,而且男女的吸煙比例不同����。經過加權后我們得到該公司吸煙的比例估計在53%���;
我們總是希望調查所得的估計值與已知的男性和女性數量比例相一致�����,當我們認為一個人是否吸煙與他的性別之間可能存在相關性��,因此他們認為����,使用事后分層能夠提高估計的精度�����。
然而實際上���,如果在調查的設計階段就已經獲得這些信息的話�����,就可以用性別來進行分層����。
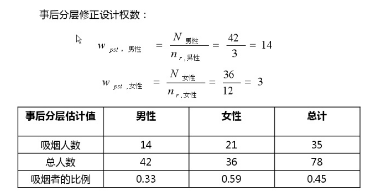
經過事后加權處理后����,我們得到的該公司吸煙者比例為45%����。也就是經過權重修訂后的估計結果�!
SPSS軟件進行加權處理:就是選擇或指定某個變量為權重���,你應該能夠在狀態欄看到Weight On��;
更復雜的加權����,例如可以采用標準差加權�、正態分布得分加權以及其它復雜數據變換后情況的處理加權�����!
如果數據有“加權”�,我們要明確地告訴客戶:
為什么加權����?
加權方案的實施過程��;
加權對數據的影響���,等等�����;
通常�����,我們應該:在數據報告過程中�����,在圖表上同時標明“未加權”和“加權”的基數���;在分析報告可靈活處理���,但也應有清晰的��、一致的標注�����;
記住一點:加權也是篡改數據的方法�!謹慎使用�!
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
