機器學習從入門到放棄之決策樹算法
決策樹故名思意是用于基于條件來做決策的���,而它運行的邏輯相比一些復雜的算法更容易理解��,只需按條件遍歷樹就可以了���,需要花點心思的是理解如何建立決策樹�。
舉個例子�����,就好像女兒回家����,做媽媽的給女兒介紹對象����,于是就有了以下對話:
媽媽:女啊�����,明天有沒有時間����,媽媽給你介紹個對象
女兒:有啊����,對方多大了��。
媽媽:年齡和你相仿
女兒:帥不帥啊
媽媽: 帥
女兒:那我明天去看看
媽媽和女兒對話的這個過程中�,女兒的決策過程可以用下圖表示:
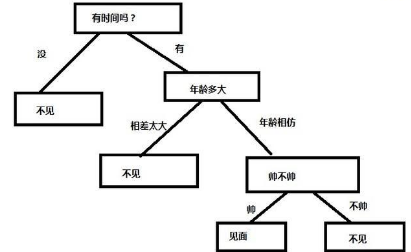
你可能會認為���,這個決策的過程本質上就是對數據集的每一個做if--else的判斷�����,這不很簡單嗎����?那為什么還要專門弄一個算法出來呢��?
不妨可以考慮兩點�����,假如訓練數據集中存在無關項��,比如以下的例子:
10-1 #表示第一項特征是1�,第二項特征是0���,最后推出的結果是1����,以下同理
12-1
05-0
09-0
17-1
……
顯然的���,最后結果和第二個特征無關�����,如果仍要做判斷就會增加了損耗�。所以在建立決策樹的過程中�����,我們就希望把這些無關項扔掉�。
第二點�����,回到媽媽給女兒介紹對象的這個例子����,上圖是為了方面讀者理解���,所以按照順序畫出����,但事實上�����,有一個嚴重的問題�,比如說女兒可能不能容忍某個缺點��,而一旦對方的性格中具有這個缺點�����,那么其他一切都不用考慮�。也就是說����,有一個特征跟最后的結果相關度極高��,這時我們就希望這個數據出現在根節點上��,如果核心條件不滿足那就結束遍歷這棵樹了�,避免無謂的損耗����。
總言言之�,決策樹第一個是需要從大量的已存在的樣本中推出可供做決策的規則����,同時��,這個規則應該避免做無謂的損耗�����。
算法原理
構造決策樹的關鍵步驟是分裂屬性���。分裂屬性值得就是在某個節點處按照某一特征屬性的不同劃分構造不同的分支��,其目標是讓各個分裂子集盡可能地“純”�����。盡可能“純”就是盡量讓一個分裂子集中待分類項屬于同一類別��。這時分裂屬性可能會遇到三種不同的情況:
對離散值生成非二叉決策樹�。此時用屬性的每一個劃分作為一個分支�。
對離散值生成二叉決策樹�。此時使用屬性劃分的一個子集進行測試���,按照“屬于此子集”和“不屬于此子集”分成兩個分支���。
屬性是連續值�����。確定一個split_point���,按照>split_point和<=split_point轉成成離散����,分別建立兩個分支
構造決策樹的關鍵性內容是進行屬性選擇度量����,屬性選擇度量是一種選擇分裂準則�,是將給定的類標記的訓練集合的數據劃分D“最好”地分成個體類的啟發式方法����,它決定了拓撲結構及分裂點split_point的選擇�。
在這里僅介紹比較常用的ID3算法��。
從信息論知識中我們直到����,期望信息越小����,信息增益越大���,從而純度越高��。所以ID3算法的核心思想就是以信息增益度量屬性選擇����,選擇分裂后信息增益最大的屬性進行分裂���。
循序本系列的從工程角度理解算法��,而非數學角度理解算法的原則����,因此這里只給出信息增益度量的計算方式����,如果需要深入了解其數學原理�����,請查閱專業資料�����。
設D為用類別對訓練元組進行的劃分����,則D的熵計算方法為:
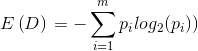
其中pi表示第i個類別在整個訓練集中出現的概率���。
當按照特征A分割后����,其期望信息為:
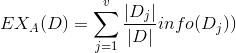
其中Di/D表示每一個D在整體訓練集占的比例�����。
而信息增益即為兩者的差值:

其中當gain(A)達到最大時�����,該特征便是最佳的劃分特征�����,選中最佳特征作為當前的節點����,隨后對劃分后的子集進行迭代操作��。
算法實現
github
在本專欄的前面的文章描述了基于決策樹的五子棋游戲�,算是一個基于決策樹的應用了���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
