數據挖掘算法之關聯規則挖掘(一)apriori算法
關聯規則挖掘算法在生活中的應用處處可見�����,幾乎在各個電子商務網站上都可以看到其應用
舉個簡單的例子
如當當網�,在你瀏覽一本書的時候��,可以在頁面中看到一些套餐推薦����,本書+有關系的書1+有關系的書2+...+其他物品=多少¥
而這些套餐就很有可能符合你的胃口�����,原本只想買一本書的你可能會因為這個推薦而買了整個套餐
這與userCF和itemCF不同的是�����,前兩種是推薦類似的�,或者你可能喜歡的商品列表
而關聯規則挖掘的是n個商品是不是經常一起被購買����,如果是�,那個n個商品之中�,有一個商品正在被瀏覽(有被購買的意向)����,那么這時候系統是不是就能適當的將其他n-1個商品推薦給這個用戶�����,因為其他很多用戶在購買這個商品的時候會一起購買其他n-1的商品����,將這n個商品做成一個套餐優惠�,是不是能促進消費呢
這n個商品之間的關系(經常被用戶一起購買)就是一個關聯規則
下面介紹一個比較簡單的關聯規則算法---apriori
首先介紹幾個專業名詞
挖掘數據集:就是待挖掘的數據集合��。這個好理解
頻繁模式:頻繁的出現在挖掘數據集中的模式����,例如項集���,子結構��,子序列等���。這個怎么理解呢��,簡單的說就是挖掘數據集中��,頻繁出現的一些子集數據
關聯規則:例如�����,牛奶=>雞蛋{支持度=2%���,置信度=60%}����。關聯規則表示了a物品和b物品之間的關系�,通過支持度和置信度來表示(當然不只是兩個物品之間���,也有可能是n個物品之間的關系)����,支持度和置信度定義的值的大小會影響到整個算法的性能
支持度:如上例子中��,支持度表示�����,在所有用戶中�����,一起購買了牛奶和雞蛋的用戶所占的比例是多少����。支持度有一個預定義的初值(如上例中的2%)���,如果最終的支持度小于這個初值�����,那么這個牛奶和雞蛋就不能成為一個頻繁模式
置信度:如上例子中�,置信度表示�����,在所有購買了牛奶的用戶中�,同時購買了雞蛋的用戶所占的比例是多少�。和支持度一樣���,置信度也會有一個初值(上例中的60%�,表示購買了牛奶的用戶中60%還購買了雞蛋)�����,如果最終的置信度小于這個初值�����,那么牛奶和雞蛋也不能成為一個頻繁模式
支持度和置信度也可以用具體的數據來表示�,而不一定是一個百分比
apriori算法的基本思想就是:在一個有n項的頻繁模式中�,它的所有子集也是頻繁模式
下面來看一個購物車數據的例子

TID表示購物車的編號�,每行表示購物車中對應的商品列表����,商品為i1,i2,i3,i4,i5�,D代表整個數據表
apriori算法的工作過程如下圖:
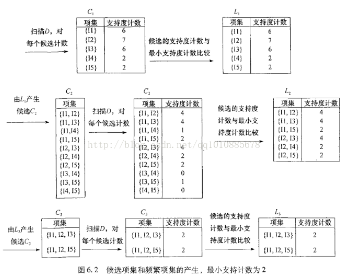
(1)首先掃描整個數據表D���,計算每個商品的支持度(出現的次數)����,得到候選C1表�。這里將每個獨立的商品都看成一個頻繁模式來處理���,計算它的支持度
(2)將每個商品的支持度和最小支持度作對比(最小支持度為2)����,小于2的商品將被過濾�,得到L1���。這里每個商品的支持度都大于2���,所以全部保留
(3)將L1和自身進行自然連接操作�����,得到候選C2表�����。也就是進行L1*L1操作���,將L1進行全排列����,去掉重復的行得到候選C2(如�,{i1,i1},{i2,i2}等)�,C2中的每個項都是由兩個商品組成的
(4)再次掃描整個表D���, 計算C2中每行的支持度�����。這里將C2中的每行(兩個商品)都當做一個頻繁模式計算支持度
(5)將C2中的每項支持度和最小支持度2作比較���,過濾����,得到L2�����。
(6)在將L2和自身做自然連接得到候選C3���。L2*L2的結果為:{i1,i2,i3},{i1,i2,i5}{i1.i3,i5}{i2,i3,i4}{i2,i3,i5}{i2,i4,i5}��,{i1,i2}和{i1,i3}的結果為{i1,i2,i3}���,計算方式為:前n-1個項必須是一致的(就是i1)�����,結果就是前n-1項+各自的第n項(i2����,i3)�����。那么為什么產生的C3中只有{i1,i2,i3},{i1,i2,i5}呢��,回頭看看apriori算法的基本思想�,如果第三個{i1,i3,i5}也是頻繁模式的話��,那么它的所有子集也應該是頻繁模式�,而在L2中無法找到{i3,i5}這個項����,所以{i1.i3,i5}不是一個頻繁模式���,過濾����。最終結果就是C3
(7)再次掃描整個表D����,計算C3中每行的支持度��。這里將C3中的每行(三個商品)都當做一個頻繁模式計算支持度
(8)將C3中的每項支持度和最小支持度2作比較����,過濾��,得到L3
由于整個表D最多的項是4��,而且只出現一次���,所以它不可能是頻繁模式��,故計算到三項的頻繁模式就可以結束了
算法的輸出結果應該是;1�����,L2����,L3集合���,其中每個項都是一個頻繁模式
例如我們得到一個頻繁模式{i1,i2,i3}���,能夠提取哪些關聯規則�����?
{i1,i2}=>i3�����,表示購買了i1����,i2的用戶中還購買了i3的用戶所占的比例��。{i1,i2,i3}的出現次數為2���,{i1,i2}的出現次數為4�,故置信度為2/4=50%
類似的可以算出
{i1,i3}=>i2���,confidence=50%
{i2,i3}=>i1�,confidence=50%
i1=>{i2,i3}�����,confidence=33%
i2=>{i1,i3}�����,confidence=28%
i3=>{i1,i2}�����,confidence=33%
也就是說����,當一個用戶購買了i1�,i3的時候系統可以將i2一起當做一個套餐推薦給用戶�����,因為這三個商品頻繁的被一起購買
但是��,通過對算法整個過程的描述��,我們可以看到��,apriori算法在計算上面的簡單例子中�,進行了3次全表掃描�,而且在進行L1自然連接的時候���,如果購物車項的數據是很大(比如100)����,這時候進行自然連接操作的計算量是巨大的���,內存無法加載如此巨大的數據
所以apriori算法現在已經很少使用了�����,但是通過了解apriori算法可以讓我們對關聯規則挖掘進一步了解�����,并且可以作為一個比較基礎�����,和其他關聯規則算法做對比�,從而得知哪個算法性能好����,好在哪里��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
