SPSS:多個樣本率的卡方檢驗及兩兩比較
1�、問題與數據
某醫生擬探討藥物以外的其他方法是否可降低患者的膽固醇濃度�����,如增強體育鍛煉���、減少體重及改善飲食習慣等�。
該醫生招募了150位高膽固醇����、生活習慣差的受試者���,并將其隨機分成3組��。其中一組給予降膽固醇藥物���,一組給予飲食干預�����,另一組給予運動干預����。經過6個月的試驗后����,該醫生重新測量受試者的膽固醇濃度�,分為高和正常兩類��。
該醫生收集了受試者接受的干預方法(intervention)和試驗結束時膽固醇的風險程度(risk_level)等變量信息���,并按照分類匯總整理�����,部分數據如下:
注釋:本研究將膽固醇濃度分為“高”和“正?��!眱深?��,只是為了分析的方便�����,并不代表臨床診斷結果��。
2���、對問題的分析
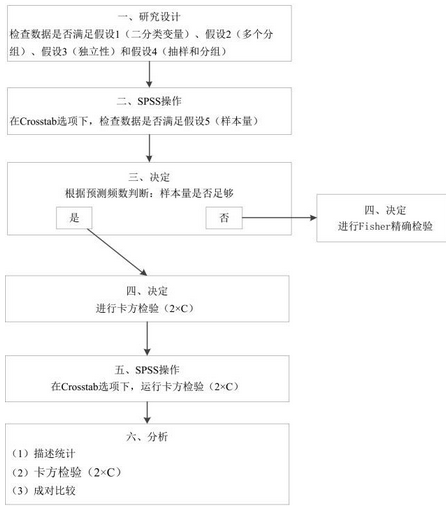
研究者想判斷干預后多個分組情況的不同�����。如本研究中經過降膽固醇藥物�、飲食和運動干預后����,比較各組膽固醇濃度的變化情況���。針對這種情況��,我們建議使用卡方檢驗(2×C)�����,但需要先滿足5項假設:
假設1:觀測變量是二分類變量���,如本研究中試驗結束時膽固醇的風險程度變量是二分類變量����。
假設2:存在多個分組(>2個)����,如本研究有3個不同的干預組����。
假設3:具有相互獨立的觀測值�,如本研究中各位受試者的信息都是獨立的�����,不會相互干擾���。
假設4:研究設計必須滿足:(a) 樣本具有代表性���,如本研究在高膽固醇�����、生活習慣差的人群中隨機抽取150位受試者����;(b) 目的分組���,可以是前瞻性的�����,也可以是回顧性的���,如本研究中將受試者隨機分成3組�,分別給予降膽固醇藥物�����、飲食和運動干預����。
假設5:樣本量足夠大�����,最小的樣本量要求為分析中的任一預測頻數大于5�。
經分析����,本研究數據符合假設1-4�,那么應該如何檢驗假設5���,并進行卡方檢驗(2×C)呢����?
3�����、思維導圖
4�����、SPSS操作
4.1 數據加權
在進行正式操作之前�,我們需要先對數據加權����,如下:
(1)在主頁面點擊Data→Weight Cases
彈出下圖:
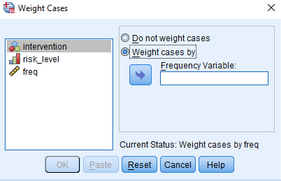
(2)點擊Weight cases by���,激活Frequency Variable窗口
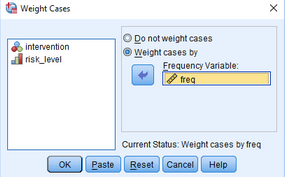
(3)將freq變量放入Frequency Variable欄
(4)點擊OK
4.2 檢驗假設5
數據加權之后�,我們要判斷研究數據是否滿足樣本量要求����,如下:
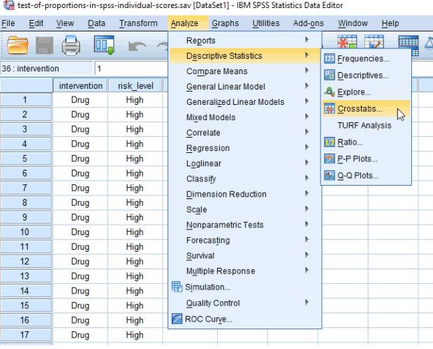
(1)在主頁面點擊Analyze→Descriptive Statistics→Crosstabs
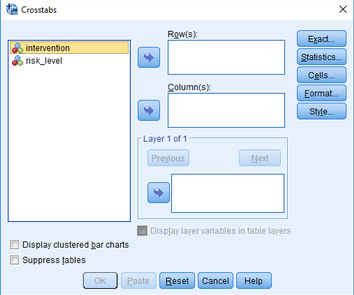
彈出下圖:
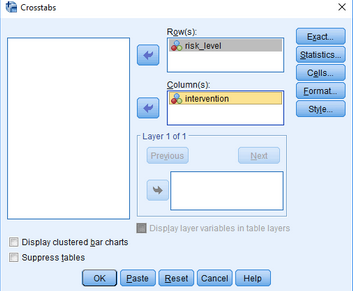
(2)將變量intervention和risk_level分別放入Row(s)欄和Column(s)欄
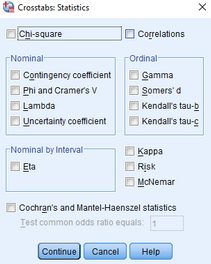
(3)點擊Statistics��,彈出下圖:
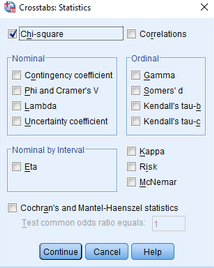
(4)點擊Chi-square
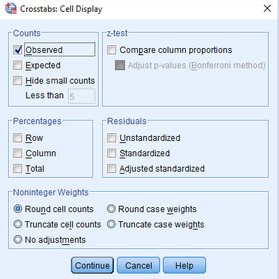
(5)點擊Continue→Cells
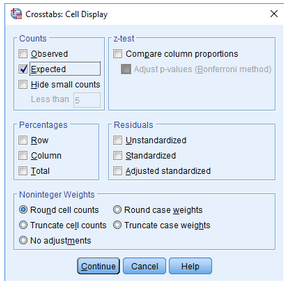
(6)點擊Counts欄中的Expected選項
(7)點擊Continue→OK
經上述操作�����,SPSS輸出預期頻數結果如下:
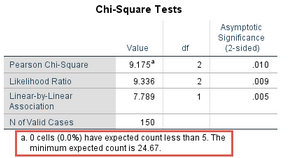
該表顯示����,本研究最小的預測頻數是24.7���,大于5�����,滿足假設5�,具有足夠的樣本量����。Chi-Square Tests 表格也對該結果做出提示���,如下標注部分:
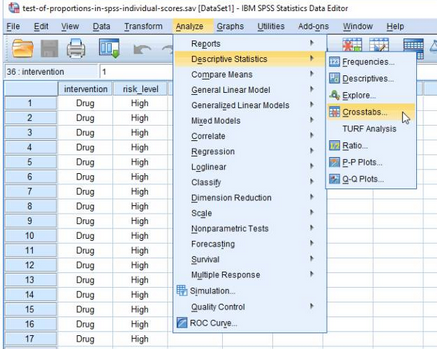
即在本研究中��,沒有小于5的預測頻數�����,可以直接進行卡方檢驗(2×C)��。那么��,如果存在預測頻數小于5的情況�����,我們應該怎么辦呢�?一般來說���,如果預測頻數小于5��,就需要進行Fisher精確檢驗(2×C)���,我們將在后面推送的內容中向大家詳細介紹���。
4.3 方檢驗(2×C)的SPSS操作
(1)在主頁面點擊Analyze→Descriptive Statistics→Crosstabs
彈出下圖:
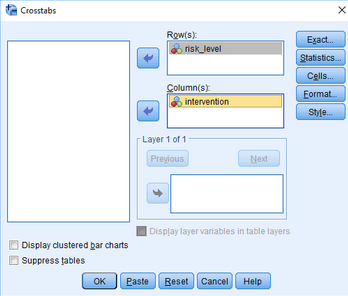
(2)點擊Statistics�����,彈出下圖:
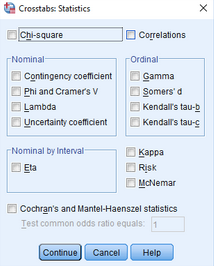
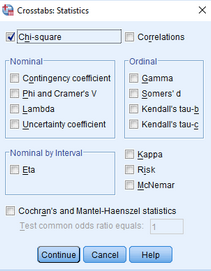
(3)點擊Chi-square
(4)點擊Continue→Cells
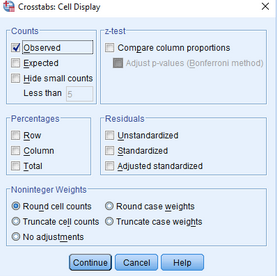
(5)點擊Percentage欄中的Column選項
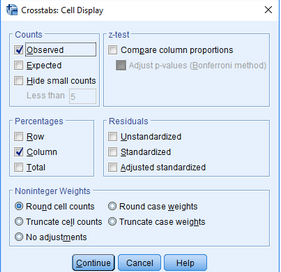
(6)點擊Continue→OK
4.4 組間比較
(1)在主頁面點擊Analyze→Descriptive Statistics→Crosstabs
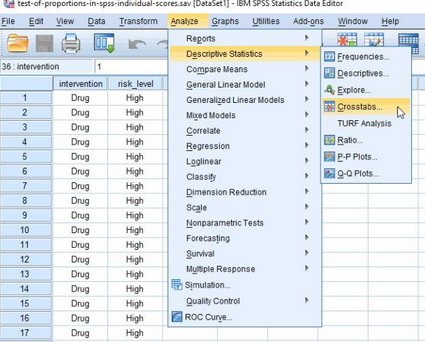
彈出下圖:
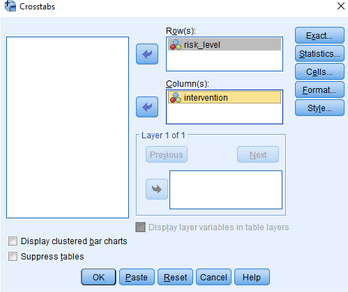
(2)點擊Cells�����,彈出下圖:
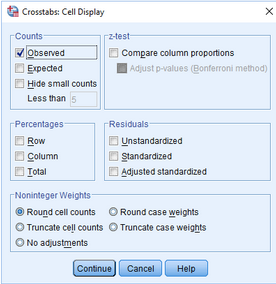
(3)點擊z-test欄中的Compare column proportions和Adjust p-values (Bonferroni method)選項
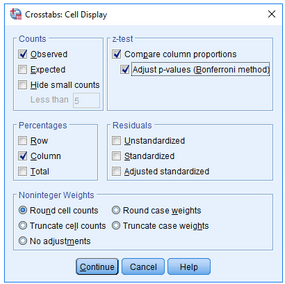
(4)點擊Continue→OK
5��、結果解釋
5.1 統計描述
在進行卡方檢驗(2×C)的結果分析之前����,我們需要先對研究數據有個基本的了解���。SPSS輸出結果如下:
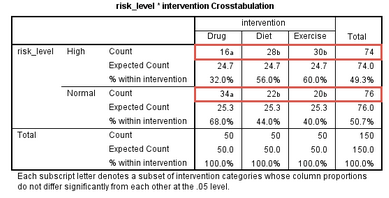
該表提示��,本研究共有150位受試者��,根據干預方式均分為3組�����。在試驗結束時��,藥物干預組的50位受試者中有16位膽固醇濃度高��,飲食干預組的50位受試者中有28位膽固醇濃度高��,而運動干預組的50位受試者中有30位膽固醇濃度高����,如下標注部分:
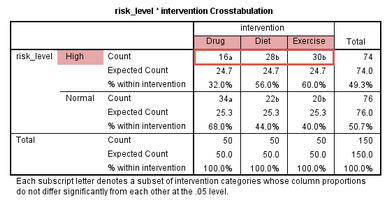
由此可見�����,藥物干預比飲食或運動干預的療效更好�。同時�,該表也提示���,藥物干預組的50位受試者中有34位膽固醇濃度下降��,飲食干預組的50位受試者中有22位膽固醇濃度下降��,而運動干預組的50位受試者中只有20位膽固醇濃度下降���,如下標注部分:
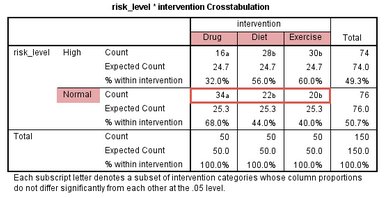
但是�����,當各組樣本量不同時���,頻數會誤導人們對數據的理解�。因此���,我們推薦使用頻率來分析結果����,如下標注部分:
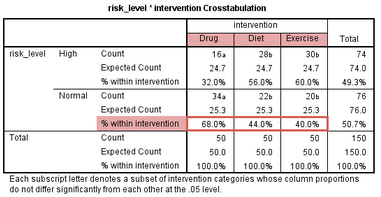
該表提示���,藥物干預組的50位受試者中68%膽固醇濃度下降����,飲食干預組的50位受試者中44%膽固醇濃度下降����,而運動干預組的50位受試者中只有40%膽固醇濃度下降�,提示藥物干預比飲食和運動干預更有效����。但是這種直接的數據比較可能受到抽樣誤差的影響����,可信性不強���,我們還需要進行統計學檢驗��。
5.2 卡方檢驗(2×C)結果
本研究中任一預測頻數均大于5���,所以根據Chi-Square Tests表格分析各組的差別���。SPSS輸出檢驗結果如下:
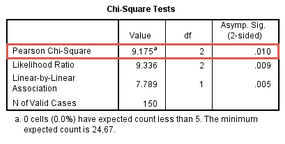
卡方檢驗(2×C)結果顯示χ2=9.175����,P= 0.010����,說明本研究中各組之間率的差值與0的差異具有統計學意義�,提示藥物干預與飲食���、運動干預在降低受試者膽固醇濃度的作用上存在不同����。如果P>0.05���,那么就說明各組之間率的差值與0的差異沒有統計學意義����,即不認為各組之間存在差異��。
5.3 卡方檢驗(2×C)中的成對比較分析
如果卡方檢驗(2×C)的P<0.05�����,說明至少有兩組之間的差異存在統計學意義���。SPSS輸出的risk_level * intervention Crosstabulation表格通過數字標記提示了兩兩比較的結果��,如下標注部分:
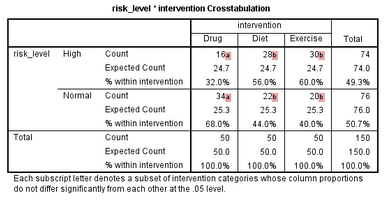
大家可能會注意到����,每組數據的標記相同(即上下兩行的標記相同)��,那么我們只要知道組間標記的作用即可�。
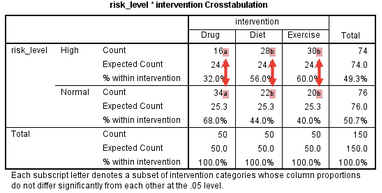
那么����,risk_level * intervention Cross tabulation表格的標記是什么意思呢���?第一種情況�,各組間無差異���,如下:
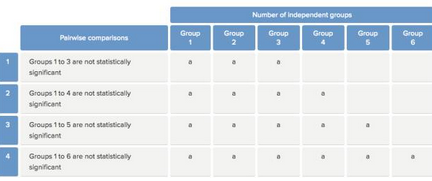
如上圖���,各組間標記一致�,說明各組之間無差異����。第二種情況�,任意兩組之間均存在差異�,如下:
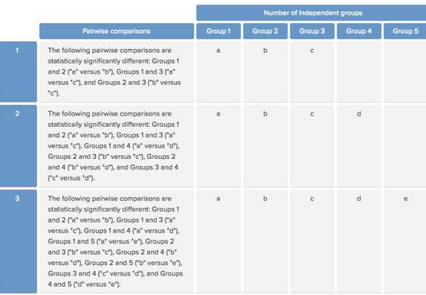
即每組標記字母均不相同��,說明任意兩組之間的差異均存在統計學意義�。第三種情況�,有些組之間存在差異���,而另一些組之間的差異沒有統計學意義����,如下:
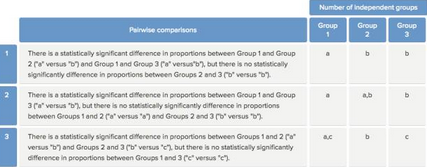
如果任兩組之間標記字母相同�,說明這兩組之間的差異沒有統計學意義�����;如果兩組標記字母不同�,說明這兩組之間的差異存在統計學意義���。
根據這一原則��,分析本研究結果如下:
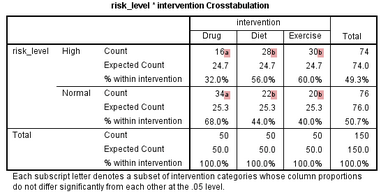
該表說明�����,在本研究中�����,藥物干預的降膽固醇作用(“a”)與飲食干預的降膽固醇作用(“b”)的差異存在統計學意義(P<0.05)�����,藥物干預的降膽固醇作用(“a”)也與運動干預的降膽固醇作用(“b”)的差異存在統計學意義(P<0.05)�,而飲食干預(“b”)與運動干預(“b”)在降膽固醇的作用上沒有差異�。
6�、撰寫結論
6.1 若卡方檢驗(2×C)的P<0.05
本研究招募150位高膽固醇���、生活習慣差的受試者���,隨機分組后分別給予藥物��、飲食和運動干預����。試驗結束時����,藥物干預組有34位(68%)膽固醇濃度下降�����,飲食干預組有22位(44%)膽固醇濃度下降���,而運動干預組有20位(40%)膽固醇濃度下降����,三組差異具有統計學意義(P=0.010)�。
成對比較結果提示��,藥物干預的降膽固醇效果好于飲食或運動干預(P<0.05)�����,而飲食與運動干預在降低膽固醇濃度上的作用無差異(P>0.05)����。
6.2 若卡方檢驗(2×C)的P≥0.05
本研究招募150位高膽固醇�����、生活習慣差的受試者����,隨機分組后分別給予藥物���、飲食和運動干預��。試驗結束時��,藥物干預組有24位(48%)膽固醇濃度下降�,飲食干預組有22位(44%)膽固醇濃度下降��,而運動干預組有20位(40%)膽固醇濃度下降�����,三組結果的差異沒有統計學意義(P=0.620)����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
