python的正則表達式re模塊的常用方法
Python的re模塊(Regular Expression 正則表達式)提供各種正則表達式的匹配操作����,在文本解析���、復雜字符串分析和信息提取時是一個非常有用的工具���,下面我主要總結了re的常用方法
1.re的簡介
使用python的re模塊����,盡管不能滿足所有復雜的匹配情況����,但足夠在絕大多數情況下能夠有效地實現對復雜字符串的分析并提取出相關信息���。python 會將正則表達式轉化為字節碼���,利用 C 語言的匹配引擎進行深度優先的匹配���。
代碼如下:
import re
print re.__doc__
可以查詢re模塊的功能信息�����,下面會結合幾個例子說明�。
2.re的正則表達式語法
正則表達式語法表如下:
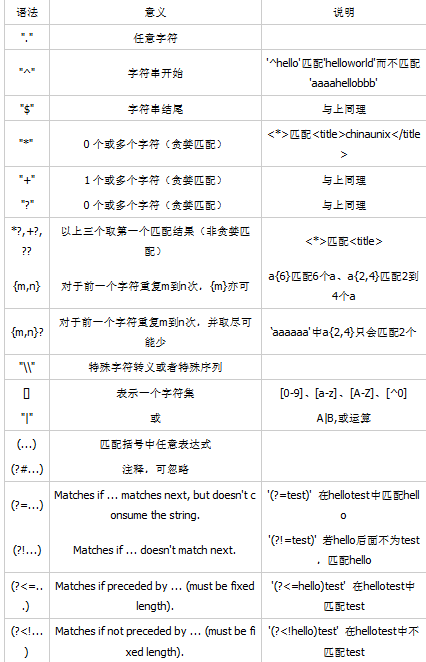
正則表達式特殊序列表如下:
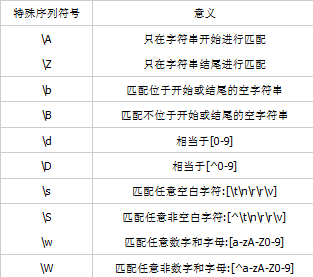
3.re的主要功能函數
常用的功能函數包括:compile�、search�、match����、split����、findall(finditer)�、sub(subn)
compile
re.compile(pattern[, flags])
作用:把正則表達式語法轉化成正則表達式對象
flags定義包括:
re.I:忽略大小寫
re.L:表示特殊字符集 \w, \W, \b, \B, \s, \S 依賴于當前環境
re.M:多行模式
re.S:' . '并且包括換行符在內的任意字符(注意:' . '不包括換行符)
re.U: 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依賴于 Unicode 字符屬性數據庫
search
re.search(pattern, string[, flags])
search (string[, pos[, endpos]])
作用:在字符串中查找匹配正則表達式模式的位置��,返回 MatchObject 的實例����,如果沒有找到匹配的位置�����,則返回 None�。
match
re.match(pattern, string[, flags])
match(string[, pos[, endpos]])
作用:match() 函數只在字符串的開始位置嘗試匹配正則表達式�����,也就是只報告從位置 0 開始的匹配情況�,而 search() 函數是掃描整個字符串來查找匹配����。如果想要搜索整個字符串來尋找匹配�,應當用 search()�����。
下面是幾個例子:
例:最基本的用法��,通過re.RegexObject對象調用
復制代碼 代碼如下:
#!/usr/bin/env python
import re
r1 = re.compile(r'world')
if r1.match('helloworld'):
print 'match succeeds'
else:
print 'match fails'
if r1.search('helloworld'):
print 'search succeeds'
else:
print 'search fails'
說明一下:r是raw(原始)的意思��。因為在表示字符串中有一些轉義符�,如表示回車'\n'�����。如果要表示\表需要寫為'\\'����。但如果我就是需要表示一個'\'+'n'���,不用r方式要寫為:'\\n'�����。但使用r方式則為r'\n'這樣清晰多了�。
例:設置flag
復制代碼 代碼如下:
#r2 = re.compile(r'n$', re.S)
#r2 = re.compile('\n$', re.S)
r2 = re.compile('World$', re.I)
if r2.search('helloworld\n'):
print 'search succeeds'
else:
print 'search fails'
例:直接調用
代碼如下:
if re.search(r'abc','helloaaabcdworldn'):
print 'search succeeds'
else:
print 'search fails'
split
re.split(pattern, string[, maxsplit=0, flags=0])
split(string[, maxsplit=0])
作用:可以將字符串匹配正則表達式的部分割開并返回一個列表
例:簡單分析ip
代碼如下:
#!/usr/bin/env python
import re
r1 = re.compile('W+')
print r1.split('192.168.1.1')
print re.split('(W+)', '192.168.1.1')
print re.split('(W+)', '192.168.1.1', 1)
結果如下:
['192', '168', '1', '1']
['192', '.', '168', '.', '1', '.', '1']
['192', '.', '168.1.1']
findall
re.findall(pattern, string[, flags])
findall(string[, pos[, endpos]])
作用:在字符串中找到正則表達式所匹配的所有子串���,并組成一個列表返回
例:查找[]包括的內容(貪婪和非貪婪查找)
代碼如下:
#!/usr/bin/env python
import re
r1 = re.compile('([.*])')
print re.findall(r1, "hello[hi]heldfsdsf[iwonder]lo")
r1 = re.compile('([.*?])')
print re.findall(r1, "hello[hi]heldfsdsf[iwonder]lo")
print re.findall('[0-9]{2}',"fdskfj1323jfkdj")
print re.findall('([0-9][a-z])',"fdskfj1323jfkdj")
print re.findall('(?=www)',"afdsfwwwfkdjfsdfsdwww")
print re.findall('(?<=www)',"afdsfwwwfkdjfsdfsdwww")
finditer
re.finditer(pattern, string[, flags])
finditer(string[, pos[, endpos]])
說明:和 findall 類似��,在字符串中找到正則表達式所匹配的所有子串����,并組成一個迭代器返回��。同樣 RegexObject 有:
sub
re.sub(pattern, repl, string[, count, flags])
sub(repl, string[, count=0])
說明:在字符串 string 中找到匹配正則表達式 pattern 的所有子串����,用另一個字符串 repl 進行替換��。如果沒有找到匹配 pattern 的串��,則返回未被修改的 string��。Repl 既可以是字符串也可以是一個函數����。
例:
代碼如下:
#!/usr/bin/env python
import re
p = re.compile('(one|two|three)')
print p.sub('num', 'one word two words three words apple', 2)
subn
re.subn(pattern, repl, string[, count, flags])
subn(repl, string[, count=0])
說明:該函數的功能和 sub() 相同���,但它還返回新的字符串以及替換的次數����。同樣 RegexObject 有:
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
