一�、案例綜述
案例編號:102006
案例名稱:中英文垃圾短信過濾
作者姓名(或單位����、或來源):朱江
案例所屬行業:J631 電信
案例所用軟件:R
案例包含知識點:中英文文本數據處理 樸素貝葉斯分類
案例描述:
目前全球范圍內手機已經不成不可替代的生活必需品��,而短信和微信成為人們日常溝通的主要方式���,其中廣告商利用短信服務(SMS)文本信息���,以潛在消費者為目標�,給他們發送不需要的廣告信息�����。目前垃圾短信可以實現對固定區域內特定手機號碼段的用戶群發��,并且手機號信息泄露極其嚴重�。這些都導致手機用戶特別是老的手機用戶收到垃圾短信的頻率較高��,故垃圾短信和正常短信的分類不管是對于運營商還是對于客戶來說都是較為有利的工具�。
樸素貝葉斯已經成功的用于垃圾郵件的過濾��,所以它很有可能用于垃圾短信的過濾���。然而�,相對于垃圾郵件來說�,垃圾短信的自動過濾有額外的挑戰:由于短信文本數的限制��,所以一條短信是否是垃圾信息的文本量減少了����;短信的口語化導致文本可能極其不規整���,尤其是中文文本�,會帶來文本處理的難度�����;縮寫的形式在中英文文本中都較為普遍��,而且中文文本中新興詞匯的使用����,都會模糊合法信息和垃圾信息的界限��。
本案例包含已經添加好標簽的英文短信數據和中文短信數據�,英文數據有5559條����,可以進行全數據處理��,數據文件不是很大���。而中文短信有80萬條的信息���,信息量較大���,在處理過程中會生成130多G的稀疏矩陣����,遠超出R的內存限制�,且中文文本處理更為麻煩�����,故這里按照短信長度正常短信和垃圾短信分別取前1000條進行分類建模
本案例知識點沒有辦法細分���,因為文本處理過程中生成的文本文件都比較大�,會加大內存消耗����,且建模前的稀疏矩陣存儲讀取都需要轉格式較為繁瑣��,故這里我們英文短信分類作為一個知識點����,中文短信分類作為一個知識點��。
本案例共包含兩個個知識點
1英文短信文本讀取���、清洗����、詞云���、建模����、評估
2中文短信文本讀取�����、清洗��、詞云�����、建模�、評估
案例執行形式:
單人上機
二���、案例知識點
知識點1:
知識點名稱:英文短信文本讀取���、清洗���、詞云��、建模��、評估
知識點所屬工作角色:文本處理 文本挖掘 詞云 樸素貝葉斯分類 分類模型評估
知識點背景:英文文本挖掘過程中常見的文本預處理�����,樸素貝葉斯屬于一種比較簡單的分類模型�。
知識點描述:
涉及到英文文本處理中的去除無關字符�����、大小寫轉換�、去除停用詞�����、去除空白��、詞匯修剪(stem)
知識點關鍵詞:
文本處理 文本挖掘 詞云 樸素貝葉斯分類 分類模型評估
知識點所用軟件:
Rstudio
操作目的:
英文短信文本讀取����、清洗�����、詞云�����、建模�、評估
知識點素材(包括數據):
sms_spam.csv
操作步驟:
?讀取文件���,將其中的type列轉化為因子

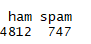
可見其中正常短信共有4812條�����,垃圾短信有747條����。
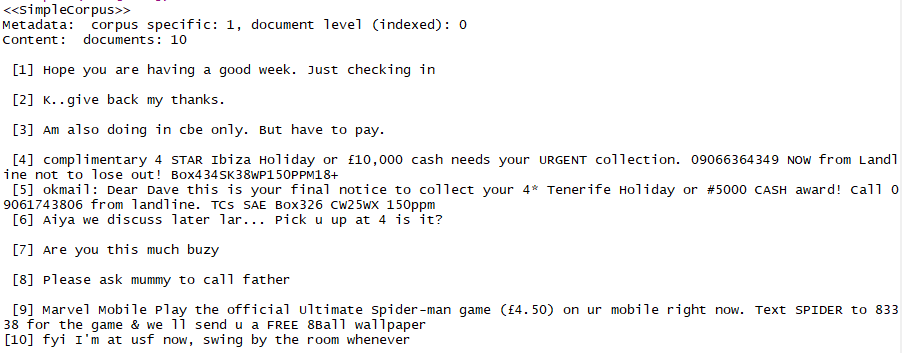
?將所有的文本信息構建成語料庫�����,并且打印出未經處理的前十條信息

?構建去除非子母類字符的函數�,用空格替換

?使用大寫變小寫����、去除停用詞��、去除多余空格以及上面構建的函數轉換語料庫���,并且觀察轉換后的前十條信息
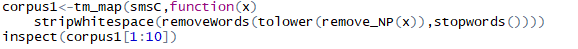

?將原數據分為訓練集和測試集����,其中訓練集占75%����,測試集占25%��。
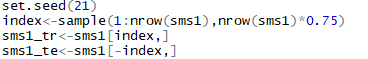
?查看訓練集和測試集中垃圾信息占比是否近似
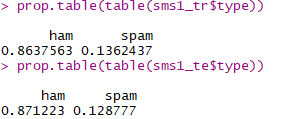
可見占比都在13%左右
?將語料庫同樣分為訓練集測試集�,方便后面構建文檔詞矩陣使用
?分別對所有訓練集�,訓練集中垃圾信息��,訓練集中正常信息創建詞云
所有訓練集信息的詞云:


訓練集中的垃圾信息的詞云:


訓練集中正常信息的詞云:

?篩選出現在大于等于5條短信中的詞��,由訓練語料庫和測試語料庫生成文檔詞矩陣(稀疏矩陣)�����,根據篩選出的詞篩選稀疏矩陣的列

將文檔詞矩陣中所有大于0的數字替換為“yes”�����,0替換為“no”�,得到訓練矩陣train和測試矩陣test

?使用樸素貝葉斯對訓練矩陣建模��,通過測試矩陣預測出分類�����,然后評估模型的性能

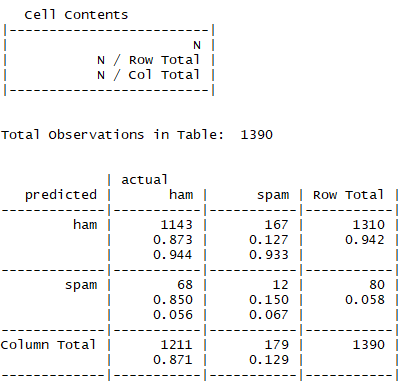
得到的結果中����,正常短信中錯誤的將垃圾信息預測為正常信息的占比為12.7%��,垃圾短信中錯誤的將正常信息預測為垃圾信息的占比為85%�����,可見模型性能一般�����,需要更多的初期工作�����,例如更多的數據采集�,詞匯處理上更多的選擇等等
操作結果:
得到訓練集中不同類型短信的詞云���;將測試集的短信分類��。
知識點小結:
本知識點顯示了英文文本清洗及轉換為文檔詞矩陣的全套流程�����,以及使用樸素貝葉斯進行分類和評估的全套流程���。
知識點2:
知識點名稱:中文短信文本讀取�����、清洗�、詞云�、建模���、評估
知識點所屬工作角色:
文本處理 文本挖掘 詞云 樸素貝葉斯分類 分類模型評估
知識點背景:
中文文本挖掘過程中常見的文本預處理�,樸素貝葉斯屬于一種比較簡單的分類模型����。
知識點描述
涉及到中文文本處理中的去除無關字符�����、去除停用詞�����、去除空白���、分詞
知識點關鍵詞:
文本處理 文本挖掘 詞云 樸素貝葉斯分類 分類模型評估
知識點所用軟件:
Rstudio
操作目的:
中文短信文本讀取���、清洗��、詞云����、建模��、評估
知識點素材(包括數據):
sms_labelled.txt stop.txt
操作步驟:
操作步驟:
?讀取文件��,用readLines按行讀取
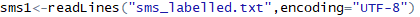
?抽取每行文本中的標簽信息���、短信信息�、計算短信長度��、合并成一個表格

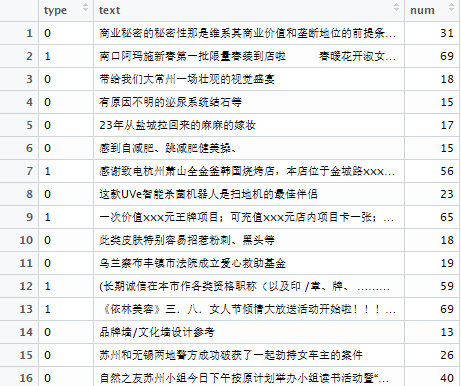
可見其中第一列是標簽����,0表示正常信息�,1表示垃圾信息
?按文本長度由長到短排列所有信息�����,選取正常信息和垃圾信息中的前一千條

將標簽變量type0重新命名為“ham”和“spam”

?去除每條短信中的非中文字符
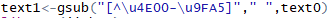 ?使用結巴分詞進行分詞����,去除停用詞
?使用結巴分詞進行分詞����,去除停用詞
 ?去掉長度小于等于1的詞
?去掉長度小于等于1的詞
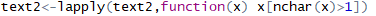 ?將短信向量轉化為語料庫�����,并且去掉常見詞“我們”
?將短信向量轉化為語料庫�����,并且去掉常見詞“我們”
 得到的前十條信息如下:
得到的前十條信息如下:
 ?將語料庫分為訓練語料庫和測試語料庫�,其中訓練集占90%�����,測試集占10%�。
?將語料庫分為訓練語料庫和測試語料庫�,其中訓練集占90%�����,測試集占10%�。
 ?分別對所有訓練語料庫����,訓練語料庫中垃圾信息����,訓練語料庫中正常信息創建詞云
訓練語料庫所有信息的詞云:
?分別對所有訓練語料庫����,訓練語料庫中垃圾信息����,訓練語料庫中正常信息創建詞云
訓練語料庫所有信息的詞云:


訓練集中的垃圾信息的詞云:
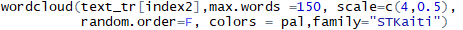

訓練集中正常信息的詞云:
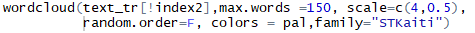

?篩選出現在大于等于5條短信中的詞����,由訓練語料庫和測試語料庫生成文檔詞矩陣(稀疏矩陣)�,根據篩選出的詞篩選稀疏矩陣的列

將文檔詞矩陣中所有大于0的數字替換為“yes”��,0替換為“no”���,得到訓練矩陣train和測試矩陣test

?使用樸素貝葉斯對訓練矩陣建模���,通過測試矩陣預測出分類�,然后評估模型的性能
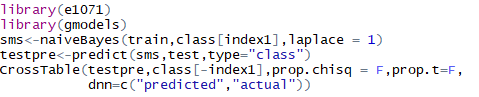

得到的結果中�,雖然只有200條短信�����,正常短信中錯誤的將垃圾信息預測為正常信息的占比為25%���,垃圾短信中錯誤的將正常信息預測為垃圾信息的占比為15.5%��,可見模型性能較英文模型有了不錯的提升
操作結果:
得到訓練集中不同類型短信的詞云���;將測試集的短信分類����。
知識點小結:
本知識點顯示了中文文本清洗及轉換為文檔詞矩陣的全套流程�����,以及使用樸素貝葉斯進行分類和評估的全套流程���。
在詞云中觀察到有亂碼�����,可能是由于txt存儲類型不是UTF-8編碼����,可以打開txt源文件另存為指定編碼來處理��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
