在SAS中如何解決中文亂碼問題
在日常的數據分析處理工作中��,不可避免的經常會和中文字符串打交道���。如果數據中有亂碼���,該如何處理��?...
煩人的問題
在日常工作中��,使用SAS進行數據處理是很正常的事情�,不可避免的經常會和中文字符串打交道�。不知道各位在使用EG的過程中�����,打開數據集查看數據的時候����,有沒有遇到過以下問題��?
(雖然我也只是偶爾遇到����,但已經被折磨好幾年?����。?
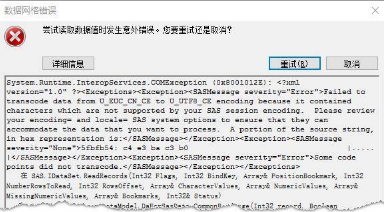
SAS Enterprise Guide 5.1
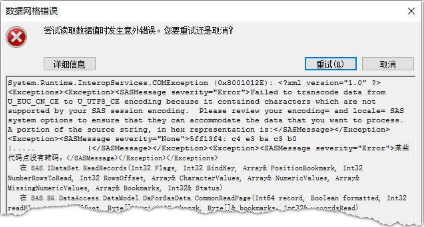
SAS Enterprise Guide 6.1
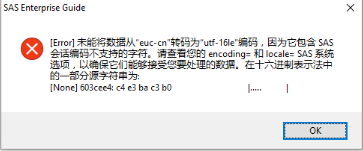
SAS Enterprise Guide 7.1
不同的版本提示的錯誤形式不完全一樣��,但出現的原因卻是一模一樣的(下面有情景再現的過程)��。仔細查看��,不難發現真正的錯誤信息都是一樣的�����,主要是:
“Failed to transcode data from U_EUC_CN_CE to U_UTF8_CE encoding because it contained characters wihch are not supported by your SAS session encoding. Please review your encoding= and locale= SAS system options to ensure that they can accommodate tje data that you want to process.”
這段話是什么意思呢����?其實就是上面EG 7.1版本的錯誤提示的中文描述��。簡而言之��,就是告訴你數據中有無法處理的編碼數據����。
問題的嚴重性
出現這個問題����,僅僅是不能打開查看數據嗎���?不是����!如果出現這個問題���,意味著你基本不能用這個數據進行后續的分析了�。只要進行的處理或者分析涉及到該有問題的字段就會提示上面的這個錯誤信息��,陰魂不散�,揮之不去����。
怎么辦
最簡單粗暴的辦法就是不用圖形化的工具EG����,用最經典的Base工具就沒有這個問題了�,一勞永逸�����。而有時候沒法不用EG的時候怎么辦����?比如我是用EG連著SAS服務器進行處理的��,該怎么辦�����?
至于為什么EG會出現這個問題�����,而Base界面沒有這個問題呢��?主要是因為軟件的底層設計而導致的���,這個編碼問題說大不大��,說小不?���?;忽略了就可以正常使用�,如果不忽略�,那么它就是一個問題���。下面會對這個問題進行再現���,剖析其原因���,你就明白了���。
問題重現
當我第一次遇到這個問題的時候��,想不明白���,就去google搜索錯誤信息�����,找到的文檔資料基本都是說編碼或者地區的設置問題�。意思就是說數據的編碼跟現有的SAS環境的編碼不一致����,也就是上面錯誤信息當中提示的�。要你通過option encoding= locale=; 修改到正確的編碼及地區�����,就可以解決問題了�����?��?墒俏业沫h境是沒有任何問題的��,數據也是同樣的環境生成的��。經過了幾次的研究��,最后搞清楚了�,這個問題是由于中文被截斷而導致的����。
(下文需要有一定的IT基礎知識���,不懂的童鞋���,可度娘有關數據存儲����、數據編碼方面的知識��;只要大概明白數據是怎么在計算機中存儲及還原的就OK了)
具體來說:在GBK編碼中(SAS中文的默認編碼方式)�����,一個漢字是占兩個字節�����。由于各種原因����,在存儲數據的時候某個漢字只存儲了其中的一個字節�����,另一個字節丟失了�。那么就導致這個字節沒法還原�����,不知道是什么東西(因為少一個字節的信息)���。所以才會有上面的錯誤提示:數據中包含當前SAS會話編碼不支持的編碼數據���。
我們可以用下面簡單的程序來再現這個問題(在EG中運行這段程序���,在Base中是可以正常查看數據的���,但只顯示“你好”�����。)
data test;
length str $ 5;
str="你好啊";
run;
當運行完這段程序�����,打開test數據集查看的時候�,就出現上面的錯誤信息:
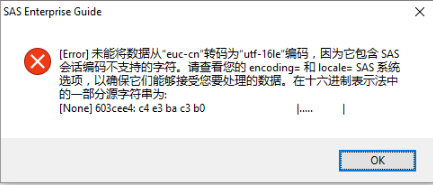
“你好啊”三個漢字需要6個字節去存儲�����,而str事先定義了長度為5個字節�,這就導致只存儲了2.5個漢字���;而存儲的這0.5個漢字信息由于沒法顯示��,所以才導致上面提示的編碼問題�����。
進一步來看看底層的信息(十六進制編碼):
data _null_;
length str1 $ 5 str2 $ 6;
str1="你好啊";
str2="你好啊";
put str1 $hex12.;
put str2 $hex12.;
run;
日志信息:

從上面的日志信息可以看到�����,就是因為少存儲了“A1”這個字節信息�,導致“B0”這個字節無法解碼��,無法正常顯示�。
額外補充(懂的人就此略過):
漢字“你”的GBK編碼�����,十進制為50403��,十六進制為C4E3
漢字“好”的GBK編碼���,十進制為47811�����,十六進制為BAC3
漢字“啊”的GBK編碼��,十進制為45217�����,十六進制為B0A1有人可能會想:英文字符就是一個字節存儲的�,一個字節也能顯示出來�;為什么這里的一個字節就出問題了��?
這就涉及到編碼范圍的問題了�,英文字符是ASCII編碼�。通過查看標準的ASCII碼表就可發現����,最大的編碼十進制為127��,十六進制為7F��;而B0是遠大于7F的���,超出了ASCII的編碼范圍����,因此無法顯示����。
如果你夠仔細���,你就會發現��,其實在EG的錯誤提示中��,就包含了這段出問題的十六進制編碼信息:c4 e3 ba c3 b0�����。
解決方案
問題的原因既然搞清楚了���,那么如何解決的思路就很清晰了��。說白了就是找出字符串中有中文截斷的地方����,然后將這半個漢字的信息直接刪除就沒問題了�����。
以前面生成的test數據為例�,str的最后一個字節包含了半個漢字信息�����,只要將最后一個字節刪掉就OK了�。
data test2;
set test;
code_before=put(str,$hex10.);
str=substr(str,1,4);
code_after=put(str,$hex10.);
run;
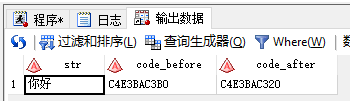
如上所示��,經過處理后�����,可以正常的顯示數據了��。
(注:code_after中最后一個字節“20”是空格的十六進制編碼�����。字符變量中多余的字節��,SAS默認用空格來填充�。因此“你好”兩個漢字占4個字節����,剩余一個字節就是空格����。)
雖然解決方法很清晰��,想起來也很簡單���,但要實現起來還不是那么容易����。上面的情況是特例��,我們明顯知道在哪個地方有問題�����,直接處理就OK��。
但通常情況下���,我們是不知道在字符串的具體哪個地方有截斷����,也不知道是哪些觀測有截斷的問題�����;而且每條觀測中被截斷的位置也不一定都一樣�,甚至也不知道截斷的數據后面有沒有其他字符數據�。面對這么多不確定����,該如何解決�����?
下面���,提供一種思路��,有興趣的童鞋可以自由發揮���,去解決這個問題���。
解決思路
首先����,GBK編碼方案中��,總體的編碼是有范圍的����,從8140~FEFE�����。其中首字節在81~FE之間�,尾字節在40~FE之間���,剔除xx7F一條線�;總計23940個碼位��,共收入21886個漢字和圖形符號��,其中漢字21003個�����,圖形符號883個���。
其次�,ASCII編碼的范圍是從00~7F�,共計128個碼位���,收入大小寫英文字母����、數字�����、符號��、及特殊控制字符����。其中可顯示的編碼范圍為20~7E�。
基于上面的這些信息����,就可以從十六進制編碼入手����,逐個去判斷識別����,進而找到存在截斷的位置����,然后將其處理掉�。記得要考慮以下多種情況:數據分析師培訓
截斷情況出現在字符串末尾
截斷情況出現在字符串中間���,且后面緊跟英文字母
截斷情況出現在字符串中間����,且后面緊跟完整的漢字
推薦學習書籍
《CDA一級教材》適合CDA一級考生備考���,也適合業務及數據分析崗位的從業者提升自我�。完整電子版已上線CDA網校��,累計已有10萬+在讀~

免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;













 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
