編者按:9月11日—9月12日����,由經管之家(原人大經濟論壇)主辦的“2015中國數據分析師行業峰會(CDA?Summit)”在北京舉行����。本文是英特爾中國研究院院長兼首席工程師吳甘沙在峰會上的演講全文����,吳甘沙演講的主題是“大數據分析師的卓越之道”����。他講道����,基礎設施已經改朝換代了�,我們分析師也應該與時俱進�,體現在三個:一個使思維方式要改變���,我們技術要提升�����,第三�����,我們分析的能力要豐富起來����。以下為吳甘沙演講全文:

親愛的各位同仁�����,各位同學���,早上好��。大家可能還有些納悶����,本來是吳恩達老師講人工智能�����,怎么換吳甘沙講���。幾個月前我剛剛跟吳老師在硅谷聊了一兩個小時�����,早知道今天這樣我多向他請教一下人工智能��,現在還是講一下我擅長的大數據���。講到大數據�,就要問數據分析師應該做什么����?所以我今天的標題是大數據分析師的卓越之道���。這里不一定講的對�,講的對的我也不一定懂�,所以請大家以批評式的方式去理解�。
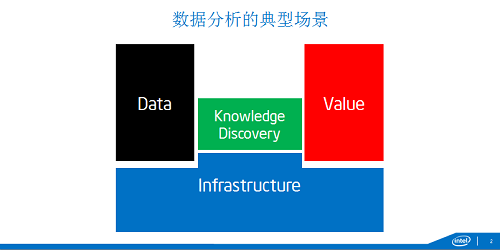
這是一個典型的數據分析的場景��,下面是基礎設施�,數據采集���、存儲到處理���,左邊是數據處理�,右邊價值輸出�����。連接數據和價值之間的就是這知識發現��,用專業詞匯講���,知識就是模型�,知識發現就是建模和學習的過程���。問題來了��,進入到大數據的時代��,這有什么變化呢�?首先對數據變的非常大�����,大家就開始說了��,數據是新的原材料����,是資產�,是石油�����,是貨幣���,所以大家的希望值也非常高����,這個價值也希望抬的非常高�。但是一旦大數據洪流過來����,我們原有基礎設施都被沖的七零八落��。所以過去十幾年事實上業界都在做大數據基礎設施�,我怎么做大規模水平擴展��,數據密集了怎么提高分布式操作性能��,怎么把磁盤山村化����,我們就有閃存內存化��,我們最近從密集型又到計算密集型���。所有這些都是基礎設施�����。
現在大家想基礎設施升級了����,我只是知識發現的過程是不是能自然升級�?我跟大家說天下沒有免費的午餐����。所以我想今天的主題是基礎設施已經改朝換代了�,我們分析師也應該與時俱進����,體現在三個:一個使思維方式要改變��,我們技術要提升���,第三���,我們分析的能力要豐富起來�����。
首先����,說一下思維方式�。說改變思維方式最重要的就是改變世界觀����,這個就是牛頓機械論世界�����。我們曾經聽說過一個叫拉夫拉絲惡魔的說法�。也就是說�,我如果在這個時刻與宇宙當中所有的原子的狀態都是可確定的話��,就可以推知過去任何一個時刻和未來任何一個時刻�,這就是牛頓的機械論����。所謂愛因斯坦發展了這個物理學�����,但是還是確定論��,決定論���,上帝不擲色子����。但是今天的世界事實上是什么樣的��?我們這個是說牛頓世界觀���,就是確定論����。事實上今天是不確定的�,基于概率的世界觀����。大家都看過所謂的(薛定論)的貓的思維的實驗��。這個貓在盒子里到底是死還是活的��,其實它可能同時是死的����,也同時是活的��。但是一旦打開這個盒子���,它就變成確定了�����,它要么就是真的變成死的��,要么就是真的變成活的��。也就是由我們現在所謂的好奇心害死貓���,就是你打開盒子有一半的概率把這個貓殺死�����。
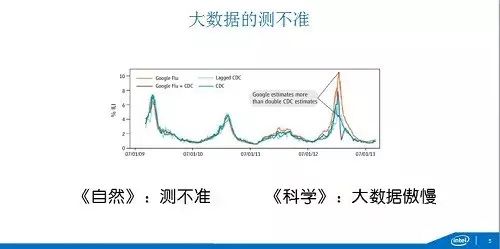
這個理念事實上反映的就是海森堡的不確定主義�����,就是你的行為會改變被觀測的現象����,在大數據事實上也有測不準的�,像Google流感的預測���,這是大家經常作為數據分析的經典案例��,具體細節不跟大家講了����,大家可以看在2013年1月份的階段�,橙色的線�,Google預計高于疾控中心它實際測到的流感的概率����。所以科學和自然就發話了�,自然是科學測不準����,科學說這是大數據的傲慢�����。在這個案例來�����,即使Google也拿不到全量的數據�,你雖然有疾控中心的數據和當中調整模型等等的����,但是還是不精確�����,你以為這種相關性就能解決問題����,但是健康的問題就是要究其原因�,要有因果性�。大家看這個預測的過量就導致了預感疫苗準備的過量����。

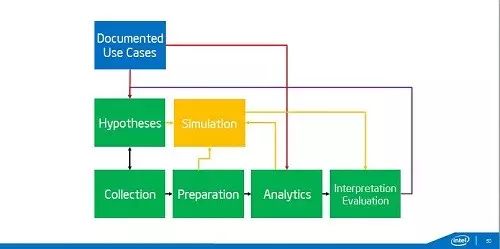
所以我們看數據的方法論我們需要升級�����。這是一個典型的數據分析的流程�����,可以先由假設采集數據��,也可以先采集了數據�����,然后從中發現假設�。有了數據以后下一步就要做數據的準備�����,數據準備往往是最花時間的����。然后分析����,分析完了要考慮怎么解釋這個結果���,大家知道做機器學習有兩種:一種是給機器看的�,比如說我精準營銷�;還有一種機器學習是給人看的�����,是要有可解釋性����。有時候為了可解釋性甚至愿意犧牲精確性���。大家知道Ficle�����,它就是理論參數����,非常簡單���,可解釋性非常強����。另外一個就是要驗證����,從我們傳統說的隨機對照實驗到現在AB測試��,我們要去驗證��。但是到了大數據時代這個方法論要怎么改變呢�����,首先我們說測不準���,還有不要相信看到的任何事��,所以需要加一個反饋循環�,我們不停的反復做這個���。這里雖然有很多噪聲���,但是這個是可以處理的��,還有一些是系統噪聲��,可能因為污染的數據源�����,這個就要特別處理�。我們要數據分析需要實時��、交互�����、要快�����,這樣才能趕得及世界的變化�����,所以這里需要很多很多的東西����。
我現在一個一個跟大家分析一下����。首先看假設�����。我們現在說大數據思維是說我們先有很多數據�����,然后通過機械的方法發現其中的相關性��,之后再找到假設�。有時候相關性確實太多了�,弱水三千只取一瓢飲�����,這里面就需要我們的直覺����。所謂的直覺就是不直覺���,但是在潛意識里在發生推理����。所以我一直強調要怎么訓練直覺��?就是讀���,像懸疑小說�,你經歷這么一個推理的過程��。如果說這樣的推理過程只是模型����,也還需要數據��,需要很多先驗的知識���。這個知識怎么來呢����?就是廣泛的閱讀���。第二個���,跨界思想的碰撞��,跟很多人聊���。這兩個是背景知識����,還有一個前景知識����,就是在這么上下游里融入到業務部門?��,F在我們企業的數據分析的組織���,我們希望把數據分析師放到業務部門�����,和它們融入到一起�,這才能防止數據和分析脫鉤����,這樣才能防止數據分析和業務應用的脫節����。
第二個���,數據采集�,這里我非?����?鋸埖氖菙祿?!數據�!數據�����!為什么���?因為大數據碰到的第一個問題就是數據饑渴癥�����。我們有一次跟阿里聊����,它們說也缺數據���,因為它們只有網上的銷售記錄����,而缺乏無線的數據��。所以我們強調全量數據����,我們盡量不采樣��。
同時現在我們企業已經從小數據到大數據��,有人說數據改變太困難了�,太貴了�����。其實它強調的是問題還沒存在的時候�����,你一開始就把數據定了�����。傳統的數據倉庫是�����,我先有一個問題��,然后你這個數據根據這個問題做好組織���,然后進來��。從現在的大數據來說��,你先把數據送進來��,然后再不斷的提問題��,這就是一種新的思維����。我們需要大量外部的數據源來查��,你要買數據拿來用�。而且你要從傳統的結構化數據到半結構化��、非結構化數據�。傳統結構化數據是什么�����,交易數據���。但是現在我們企業里面馬上就有兩個非結構化數據出現���。
說完感嘆號���,我開始要說問號�。是不是前面說的這些都是合理的��?比如說英特爾事實上是不可能采集到數據����,而有時候你采集不到全體數據�,你也不需要����。
比如說我給大家舉個例子�����,是不是數據更多就越好呢�?未必�。我們拿英特爾作為一個例子����,青海��、西藏�����、內蒙古占的面積是我們國土面積的一半��,我們采集這四個省的面積��,是不是都代表中國呢���?未必���,所以采集更多的數據有時候更重要�。第二個是“原始數據”是不是一個矛盾的概念��,因為原始數據可能并不原始�����,它受采集人的影響�。所以原始數據也未必是原始的�,數據里面當然有很多的信號�����。但是大數據里面的噪聲很多�����,但是有時候在數據里面信號就是以噪聲的方式變成的�。比如說現在我們這個世界要傾聽每一個個體的聲音�,有一些個體的聲音是非常少的���,在數據里面非常少�����,但是你不能忽略它��。采樣本身是有偏差的�,有一個經典的故事��,二戰的時候他們分析����,飛回來的時候有很多彈孔�����,到底是加固哪個地方好呢����?很多人說是機翼�����,很多人沒有想到你要加固座艙�,因為采樣是有偏差的���。尤其是大數據�,有一些子數據集�,每一個數據是按照不同的抽樣規范來獲得的���,這樣就有采樣偏差�����。
這里面是不是可以做�,你還要考慮數據權利的問題�,這些數據是屬于誰的�����?有沒有隱私問題�����?許可是不是有范圍�����?我是不是按照許可的范圍做了��?我能不能審計�?這些都是數據的權利����。未來數據交易的話還要解決數據的定價問題��,這是非常困難的�����。
當我有了數據以后�,需要生命周期的管理�,大數據生命周期管理非常重要�。一是出處或者是來源�,即是大數據的家族譜系��,它最早是哪里來的�,它又移動到什么地方����,經過什么樣的處理�,又產生了什么樣新的子后代?����,F在我們強調數據采集�����,是不是有這個必要�����?我們發現其實很多數據沒用以后���,你就應該刪除�。
有一個案例���,互聯網公司采集了很多鼠標移動的數據����。大家知道用Cookies來采集鼠標在什么地方�����,可以了解用戶的瀏覽行為�。但是過一段時間網頁都變化了�,這些數據還有什么用呢�����?所以就刪除掉�。并不是說數據越多越好���,并不是說數據永遠都要保存����,這是數據的采集���。
下面講數據的準備��,剛才說大數據有很多噪聲�,大數據的質量非常重要��。剛才我們說的它的混雜性����,它的精確性有問題����。一個非常著名的研究機構做了統計�����,說你們這些大數據分析師�,一方面數據大����,是不是你的問題�,另外一方面數據質量是不是你的問題���,選擇后者是前者的兩倍����。大數據本身它就是一個有噪聲的���,有偏差的����,也是有污染的數據源�。你的目標定在建立一個模型�,要對噪聲建模��,同時還要是信號不能太復雜���,模型不能太復雜的�。
一般處理的是數據清洗和數據驗證�,還有一種說法是有����,前者關注數據是錯的���,數據有些是丟失的或者有些數據是相互矛盾的��。我通過清洗�����、驗證的方式把它做出來�。大數據非常大怎么辦��,有沒有從一小部分數據開始做清洗��,有沒有可能把整個過程自動化��,這是研究的前沿�。另外一個前沿就是數據的清洗能不能跟可視化結合起來����,通過可視化一下子發現了這些不正常的地方�。通過機器學習的方式來推理這些不正常的地方是因為什么地方���。
我覺得現在最熱的研究課題是����,你怎么能夠通過學習的方式來發現非結構化數據當中的結構����。你怎么能夠把哪些看似不同的數據挑出來���,比如說有些地方叫國際商業機器公司����,有些地方叫藍色巨人�����,你最終能夠把這些數據的表示使得它馬上就可以分析����。我首先考慮怎么能夠降低計算通訊的代價����。
大家看我們大數據經常是稀疏的��,大數據太大了我們有沒有可能壓縮�����。大家知道我們原來的數據倉庫�,最大的問題���,最麻煩的問題就是我要給這個表增加列�,增加列特別痛苦?,F在我發現通過增加列的方式變得非常簡單�����,我通過數據壓縮樹立的話更有局部性�。
另外就是近似的數據�,它就是一種通過降低它的時空復雜性�����,使得它誤差稍微增加幾個百分點����,但是它的計算量下降幾個數量級���。大家也應該聽說過很多方式都是做這個的���。
怎么能夠降低統計的復雜性��,其實大家知道大數據就是高緯���,怎么辦�����?降下來����,我通過降緯的方式能夠降低它的復雜性����。我們還是需要采樣的��,大家知道要么是隨機性采樣��,并不代表用一個均衡的概率采樣�,我用不同的組采樣�����。比如說有些人你不知道他屬于哪個組��,比如說他是吸毒的�����,他不會說或者說他有特殊的技能�,他也沒有類似的標簽��,你可能需要一種新的采樣的方式�����,比如說雪球采樣�,你先找一個種子然后再慢慢的擴大��。即使你壓縮了很多�����,但是你還是可以恢復原始數據的��。
我想請大家注意�,數據分析師并不是考慮數據表象的問題�����,并不是考慮數據模型的問題�。最終還是要考慮計算是怎么做的��,所以我們要選擇最好的表示�。比如說數據并行的計算就用表或者是矩陣�,如果是圖并行����,我就要選擇網絡的格式�����。
最后���,我想請大家注意UIMN��,這個能夠幫助你來保存各種各樣數據表示����,以及跟數據分析落對接���。這個東西大家沒聽說過的話�,大家一定聽過Worse在人機競賽中的電腦����,它就是用這個表示的�。
最后����,查詢�����。很早數據就是查詢�����,慢慢說要統計學��,慢慢又要機器學習了�����,所以我們說數據挖掘是對三個學科的交叉�,而這些學習又是從人工智能脫胎出來����。慢慢的從這兒又包了一層ABB�����,現在又有最新的內腦計算�,分布學習��。所有這些大家不能忘記�����,這些工具都要跟相關的計算的模型給對接起來��。所以這是非常困難的東西�。
我們數據分析師還是有些裝備的��,這個是現在最流行的四種分析的語言�,Saas����,R����,SQL��,還有python�����。有人說我不是這里的���,那可能還需要學習JAVA這樣的語言�����。這個可能還不夠���,還需要JAVASrcit��,所以需要來更新我們的裝備���。但是有人說了這些裝備都是為傳統的數據分析師準備的����,大家不要擔心�,因為在這些語言下面都已經有了大數據的基礎設施�����,比如SQL���,可以使你以前的語言平滑的遷移到大數據基礎上���。這些解決了大問題����,因為原來的程序��,數據量大一些就可以放在這個大數據的基礎設施上�����。更方便的是現在所有做基礎設施的人都在考慮一個詞�,ML Pipeliine����,而且現在更多的東西都可以放到云里做了�����。大家看到現在所有這些大數據的基礎設施我們都叫做動物園了��,因為很多都是以動物的圖標來展示的����,現在都可以放到云里去����,所以這給我們帶來了很多方便����。
這里要強調的是��,這是一個統計學的大師說的��,就是所有模型都是錯的�����,但是有些是有用的�,關鍵是選擇什么樣的模型���。有一種人是一招鮮吃遍天�,還有一種是一把鑰匙開一把鎖����,我是開放的����,我根據我的問題來進行選擇�。模型的復雜度必須與問題匹配的���。這里就是有各種各樣模型都能解決的時候��,就選擇最簡單的一個��。
我們現在做數據分析碰到兩個問題:一個是過載��,還有一個是數據量大了以后���,模型沒辦法提升��。這里就有一個很著名的人�,叫彼特����,他是寫《人工智能現代方法》的作者���,他說�,簡單模型加上大數據��,比復雜模型加小數據更好���,這個對不對����,這個在很多情況下是對的�����,但是并不完全對����。而且有時候模型簡單參數很多��,場景不同參數不同�����,假設場景是文本處理����,可能每個單詞就是一個特征��,這個模型就會非常復雜���,所以大數據是有用的�����。還有一種解決數據過多的方式�����,就是通過另外一種方式?���,F在線性模型針對小數據�����,我現在代參模型針對小數據�,我甚至可以混合起來用����,這樣又能夠提升分析的效率�,又能夠解決數據的計算量的問題��。
我剛才講到長尾信號非常非常重要���,我們現在不能忽略長尾信號���,那怎么辦�����?我們傳統的分析很多都是基于指數的假設�,這個就是割尾巴���,到后面就是沒尾巴���,這樣就把長尾信號都過濾掉了���,我可能是需要一些基于神經網絡的方式����。分析要快����,第一���,我們一直強調傳統的是送進去的���,我60秒完成跟6分鐘完成是不是一樣的呢�?或者說它們的效率差一點點或者差幾倍����?未必����,等待時間拉長��,分析師的耐心會降低�。像針對時空的數據����,現在機器學習強調的在線學習���、增量的學習��、流逝的學習����,一邊進來一邊學習��、一邊更改模型���,這個就很重要��。最后當你的數據又大��,又需要快的時候�,你不懂系統是不行的���,你必須懂系統����,你必須懂數據并行�����,任務并行���,必須做系統調優的東西��。
我前兩天跟一個朋友聊�����,他說現在要做到所有分析數據的調優做到隨機的訪問都在CPU緩存里�����,到磁盤上的訪問都是串行的訪問����,這樣才能做到系統調優做到最佳�。從語音識別���,到圖像理解�,到自然語言理解��。上面都是人們做的認知任務��,深度學習下一步會進入非認知任務���,像百度用來做搜索廣告�����,包括做要務的發現���,我現在也在做機器人��,機器人很多需要深度學習����,我們現在把深度學習放進去也非常好�����。大家的福音就在于現在深度學習很多的代碼都是開源的�,去年花了很多力氣去做各種各樣的模型��,現在所有模型全部都開源����,所以下一步大家注意���,我們的科學是開放的����。你有大量的開源的軟件����,而且現在不但你論文放在ICup上���,你的數據代碼可能放在Dcup上���,所有都是開放的�����。

大家還沒有學Sparse coding的話大家可以看一下��,還有在標注下的學習�����,這張PPT是吳恩達的��,大家看����,橙色的都是標注數據���,你要有大象和犀牛的數據�����,就是左面的是標出的�,我可以結合一些非標注的東西學習��,然后可以引入其他的標注數據����,像羚羊的數據也可以幫助我們學習�,最后到拿一些完全不相關的數據跟它們進行學習�����。
人類角色在變化���,前一段時間有人提出來���,人的角色���,因為數據分析師要懂機器�����,懂工具����,我們要跟工具更好的配合���,因為我們的角色一直在跟機器替代它們�。機器學習最重要的就是特征學習�,現在無監督的���,它可以幫助你學習特征����,而且很多工具開始自動化了��,那么你怎么跟它工作搭配����,能夠獲得最好呢�����,就是你一邊在利用工具獲得一些數據�����,然后提出問題是一個循環的過程?��,F在就是大規模的人跟人���,人跟機器協同配合�,因為很多機器可以外包�,你可以眾包����,你大量數據通過眾標方式進行標注����。包括協作�����,現在開放數據��,光開放還不行����,還要在這個數據上進行多人協作分析�����,你要對數據進行版本的管理�,還有現在所謂的人類計算�����,像大家都在上面學習英語��,在學習英語的過程是對互聯網進行翻譯的過程�。
最后�,就是解釋和驗證����。今天的大會標題是要懂技術����,懂藝術��。這里一個很重要的就是講故事����,你有了分析之后怎么講出來��。比如說啤酒加尿布�����,它就符合了講故事的3D:戲劇性��、細節����、參與這個對話的過程���。啤酒加尿布��,這個案例我給大家說這是編出來的����,但是它符合了這個過程�,所以它就馬上傳播出去了��,變成大家都愿意去支持數據分析的這么一個案例����。包括魔球(電影Money ball)也是這樣����,非常強調數據分析怎么來改變棒球運動的��,但是事實上它也沒有說出來的是���,這里很多工作是通過裁判去做的�����,有些人非客觀的因素�,像意志力����,像抗壓力�����。還有像Facebook做控制情緒的實驗�,還有Uber分析一夜情����。我還是想強調好的講故事能夠使分析事半功倍���。

我們希望現在能夠把大量的運力能document��,這樣可以進行學習����,還有就是通過模擬預測未來���。所以這就是最后的總結���,現在我們的大數據的基礎設施已經改朝換代了�����,我們的數據分析師����,我們怎么來改變我們的思維方式��,怎么來提高我們的技術�,怎么來豐富我們的分析能力�?謝謝大家�。
主持人:謝謝吳院長���。我們說了這么多專業的東西�,其實我想跟院長聊聊其他的��,我記得院長是一個非常平易近人���,和藹的人���,包括他在之前回答記者的問題的時候����,調侃說自己是跑龍套的�����。所以我今天聽院長演講也是非常的激動���,為什么院長當時會這么說呢�?
吳甘沙:我想每個人都是從跑龍套開始的�����。但是我想還是學習能力����,你有學習能力的話很快就會蛻變�。
主持人:這個轉變也是意料之中的��,因為吳院長一直這么努力�。
吳甘沙:這塊不是不確定�����,這塊是確定的��。
主持人:好�,掌聲再次送給吳院長��。
PPT下載鏈接:http://bbs.pinggu.org/a-1874950.html
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
