數據清洗經驗分享:什么是數據清洗 如何做好數據清洗
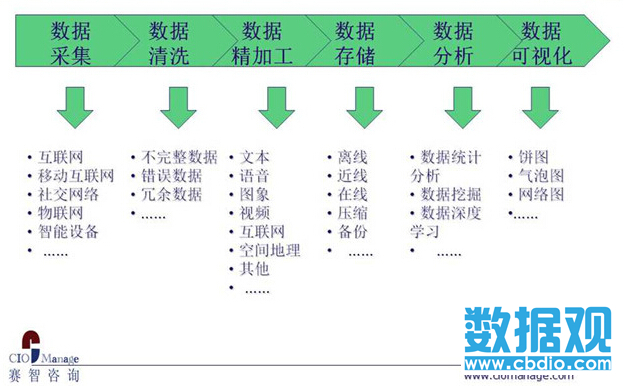
大數據本身是一座金礦��、一種資源����,沉睡的資源是很難創造價值的�����,它必須經過清洗��、分析��、建模�����、可視化等過程加工處理之后���,才真正產生價值����。
數據加工�、清洗的過程與機械加工的流水線生產過程相似���。例如����,從各個渠道采集到的數據質量很差���,于是就需要對數據進行“脫敏”以及“包裝”���,最終呈現在用戶面前時是一個個數據產品�,這樣才能提供給消費者���,進行數據交易���。
數據清洗的目的——發現并糾正數據文件
數據清洗是發現并糾正數據文件中可識別錯誤的一道程序�����,該步驟針對數據審查過程中發現的明顯錯誤值����、缺失值��、異常值�、可疑數據���,選用適當方法進行“清理”���,使“臟”數據變為“干凈”數據�����,有利于后續的統計分析得出可靠的結論�。當然�,數據清理還包括對重復記錄進行刪除�、檢查數據一致性�����。如何對數據進行有效的清理和轉換使之成為符合數據挖掘要求的數據源是影響數據挖掘準確性的關鍵因素.
 趙剛博士:中國數據加工清洗產業趨勢分析 附:
趙剛博士:中國數據加工清洗產業趨勢分析 附:
數據清洗經驗分享
數據分析的第一步是洗數據�,原始數據可能有各種不同的來源�����,包括:
1��、Web服務器的日志
2�����、某種科學儀器的輸出結果
3�、在線調查問卷的導出結果
4���、1970s的政府數據
5����、企業顧問準備的報告
這些來源的共同點是:你絕對料想不到他們的各種怪異的格式��。數據給你了��,那就要處理��,但這些數據可能經常是:
1���、不完整的(某些記錄的某些字段缺失)
2����、前后不一致(字段名和結構前后不一)
3���、數據損壞(有些記錄可能會因為種種原因被破壞)
因此���,你必須經常維護你的清洗程序來清洗這些原始數據�,把他們轉化成易于分析的格式����,通常稱為data wrangling�。接下來會介紹一些關于如何有效清洗數據����,所有介紹的內容都可以由任意編程語言實現����。
使用斷言
這是最重要的一點經驗:使用斷言(Assertions)揪出代碼中的bug�����。用斷言的形式寫下你對代碼格式的假設�,如果一旦發現有數據跟你的斷言相悖�,就修改這些斷言��。
記錄是有序的�����?如果是����,斷言之���!每一條記錄都是有7個字段么����?如果是����,斷言之���。每一個字段都是0-26之間的奇數么���?如果是�,斷言之�����!總之��,能斷言的都斷言��!
在理想世界中�����,所有記錄都應該是整整齊齊的格式�����,并且遵循某種簡潔的內在結構�����。但是實際當中可不是這樣��。寫斷言寫到你眼出血�����,即便是出血還得再寫��。
洗數據的程序肯定會經常崩潰����。這很好��,因為每一次崩潰都意味著你這些糟糕的數據又跟你最初的假設相悖了�����。反復的改進你的斷言直到能成功的走通��。但一定要盡可能讓他們保持嚴格����,不要太寬松�,要不然可能達不到你要的效果�。最壞的情況不是程序走不通����,而是走出來不是你要的結果�。
不要默默的跳過記錄
原始數據中有些記錄是不完整或者損壞的��,所以洗數據的程序只能跳過�。默默的跳過這些記錄不是最好的辦法�,因為你不知道什么數據遺漏了���。因此��,這樣做更好:
1��、打印出warning提示信息��,這樣你就能夠過后再去尋找什么地方出錯了
2���、記錄總共跳過了多少記錄����,成功清洗了多少記錄����。這樣做能夠讓你對原始數據的質量有個大致的感覺����,比如�����,如果只跳過了0.5%��,這還說的過去�。但是如果跳過了35%��,那就該看看這些數據或者代碼存在什么問題了�。
使用Set或者Counter把變量的類別以及類別出現的頻次存儲起來
數據中經常有些字段是枚舉類型的�����。例如���,血型只能是A���、B���、AB或者O��。用斷言來限定血型只能是這4種之一雖然挺好����,但是如果某個類別包含多種可能的值�,尤其是當有的值你可能始料未及的話�����,就不能用斷言了���。這時候�����,采用counter這種數據結構來存儲就會比較好用���。這樣做你就可以:
1����、對于某個類別���,假如碰到了始料未及的新取值時����,就能夠打印一條消息提醒你一下��。
2����、洗完數據之后供你反過頭來檢查��。例如���,假如有人把血型誤填成C����,那回過頭來就能輕松發現了���。
斷點清洗
如果你有大量的原始數據需要清洗��,要一次清洗完可能需要很久�,有可能是5分鐘�,10分鐘���,一小時��,甚至是幾天���。實際當中����,經常在洗到一半的時候突然崩潰了����。
假設你有100萬條記錄���,你的清洗程序在第325392條因為某些異常崩潰了�,你修改了這個bug��,然后重新清洗�,這樣的話��,程序就得重新從1清洗到325391�,這是在做無用功��。其實可以這么做:1. 讓你的清洗程序打印出來當前在清洗第幾條�����,這樣�����,如果崩潰了����,你就能知道處理到哪條時崩潰了�����。2. 讓你的程序支持在斷點處開始清洗����,這樣當重新清洗時��,你就能從325392直接開始�����。重洗的代碼有可能會再次崩潰���,你只要再次修正bug然后從再次崩潰的記錄開始就行了��。
當所有記錄都清洗結束之后�,再重新清洗一遍�,因為后來修改bug后的代碼可能會對之前的記錄的清洗帶來一些變化���,兩次清洗保證萬無一失�����。但總的來說�,設置斷點能夠節省很多時間�,尤其是當你在debug的時候���。
在一部分數據上進行測試
不要嘗試一次性清洗所有數據�����。當你剛開始寫清洗代碼和debug的時候�����,在一個規模較小的子集上進行測試�����,然后擴大測試的這個子集再測試���。這樣做的目的是能夠讓你的清洗程序很快的完成測試集上的清洗�����,例如幾秒�����,這樣會節省你反復測試的時間����。
但是要注意��,這樣做的話�,用于測試的子集往往不能涵蓋到一些奇葩記錄�,因為奇葩總是比較少見的嘛��。
把清洗日志打印到文件中
當運行清洗程序時��,把清洗日志和錯誤提示都打印到文件當中���,這樣就能輕松的使用文本編輯器來查看他們了��。
可選:把原始數據一并存儲下來
當你不用擔心存儲空間的時候這一條經驗還是很有用的���。這樣做能夠讓原始數據作為一個字段保存在清洗后的數據當中�,在清洗完之后����,如果你發現哪條記錄不對勁了��,就能夠直接看到原始數據長什么樣子�����,方便你debug���。
不過�����,這樣做的壞處就是需要消耗雙倍的存儲空間�,并且讓某些清洗操作變得更慢����。所以這一條只適用于效率允許的情況下����。
最后一點��,驗證清洗后的數據
記得寫一個驗證程序來驗證你清洗后得到的干凈數據是否跟你預期的格式一致��。你不能控制原始數據的格式�,但是你能夠控制干凈數據的格式�����。所以����,一定要確保干凈數據的格式是符合你預期的格式的�。
這一點其實是非常重要的�,因為你完成了數據清洗之后�����,接下來就會直接在這些干凈數據上進行下一步工作了����。如非萬不得已���,你甚至再也不會碰那些原始數據了�����。因此�,在你開始數據分析之前要確保數據是足夠干凈的��。要不然的話�����,你可能會得到錯誤的分析結果�����,到那時候�,就很難再發現很久之前的數據清洗過程中犯的錯了�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
