SPSS分析技術:典型相關分析�����;化繁為簡�����,典型相關分析幫助分析者理清思路
之前介紹過的相關分析有兩個變量之間的線性相關關系���,用的是簡單相關系數r����;還有復相關系數�����,用來表示一個變量與多個變量組成的整體之間的線性相關關系����;很多人會問�,如果想研究兩組變量之間的相關關系��,該使用什么方法呢���?今天介紹的典型相關分析就是用于解決這個問題的分析方法���。
在實際生活當中�,關于兩組變量之間的相關關系研究很多�。例如���,某個城市的經濟發展水平(GDP�����、貨物周轉量�、生產建設投資等)與居民生活水平(居民人均年收入�、居民財產性收入�����、恩格爾系數等)間的相關關系����;大學生畢業時的成績(各種科目成績)和入學時成績的相關關系��;公司內不同職位與員工工作滿意度之間的相關關系�����;領導者的領導能力與情緒智力的相關關系等�����。典型相關分析在實證研究中有廣泛的運用���,常常被作為結構方程模型研究的基礎步驟�����。
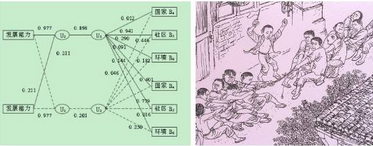
上方左圖是典型相關分析的結果展示圖��,這和右邊的拔河圖有異曲同工之處��。兩個環境中的每個參與者(變量)都是決定結果的因子����。
典型相關關系
學習過前面介紹的因子分析的朋友應該很容易想到:是否能夠從兩組變量中提取公因子�,然后用公因子之間的線性相關關系表示兩組變量之間的相關關系呢����?如果能想到這一點����,說明已經擁有知識點拓展和觸類旁通的數據分析能力��。典型相關分析就是借用了主成分分析的分析邏輯�,通過原始變量的線性組合����,找到一個或幾個綜合變量來替代原始變量�����,從而將兩組原始變量的相關關系研究轉換成少數幾對綜合變量的相關關系研究��。
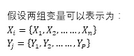
典型相關分析首先對兩組變量進行線性組合�����,找到一對綜合變量����,使這對綜合變量具有最大相關性�;然后再通過線性組合找出第二對綜合變量���,它們之間的相關關系會小于第一對綜合變量��;重復以上操作��,直到兩組變量的數據信息提取完成為止��。提取的綜合變量被稱為典型變量或典則變量���,它們之間的相關系數稱為典型相關系數�。與主成分分析相似�,只需提取少數幾對綜合變量就可以概括兩組變量的數據信息�。典型相關分析與因子分析雖然都是通過原始變量的線性組合實現數據信息的濃縮��,但是二者還是有不同的�,不同之處在于變量線性組合的標準不一樣�。
因子分析的目的是簡化分析局面��?��;谝唤M變量的相關關系��,用少數幾個公因子代替整個變量組的信息(數據的變異)�����,實現變量降維���,簡化數據分析局面����。因此����,因子分析在做原始變量線性組合時�����,尋找公因子的標準是數據變異或波動最大的方向��。而典型相關分析的目的是研究兩組變量之間的相關關系�����,因此在做原始變量的線性組合時(提取公因子)�,考慮的重點在于尋找相關關系最強的典型變量對����,簡化兩組變量之間錯綜復雜的相關關系網��。
案例分析
我們國家是個人口大國����,最近一次人口普查結果顯示我們國家的人口數達到13.3億人����,農村人口數達到50.32%��,因此提高農村居民的生活水平一直以來都是國家管理的重要內容����。農村居民的收入和支出能夠很好地反映農村居民的生活水平?����,F在有一份數據����,收集了全國30個省市自治區直轄市的農村居民收入和支出情況�����,包括四項收入數據和8項支出數據:分別是勞動收入(X1)�、經營收入(X2)�����、轉移收入(X3)����、財產收入(X4)�����;食品支出(Y1)��、衣著支出(Y2)����、居住支出(Y3)��、家庭設備和服務支出(Y4)��、醫療保健支出(Y5)�����、交通通訊支出(Y6)�、文教娛樂支出(Y7)��、其它支出(Y8)�����。SPSS數據如下圖所示:
操作須知
SPSS沒有為典型相關分析設置專門的操作菜單���,只提供了一份名為Canonical correlation.sps的宏程序文件��,這個文件存放在SPSS安裝文件夾Samples文件夾內��。只需在使用時調用����,并輸入參數語句即可調用輸出結果�����。
分析步驟
點擊菜單【文件】-【新建】-【數據】��,跳出語法編輯器窗口�����,輸入以下內容�。點擊確定����,輸出結果����。

結果解釋
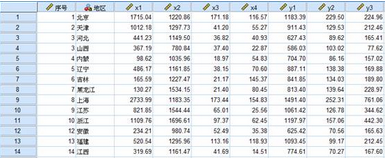
1��、相關系數矩陣�;結果輸出了三個相關系數矩陣�����,分別是第一組變量����、第二組變量�����、第一組與第二組之間的相關系數矩陣����。變量線性組合的基礎就是相關系數矩陣�����。從前兩個相關系數矩陣可以發現��,兩組變量內部�����,變量之間的相關系數都非常大����,說明它們反映的收入和支出因素是類似的��,所以不能很好的反映影響農民收入和支出水平的整體情況�。
2����、線性相關系數及顯著性檢驗�����。本案例中提取了4對典型變量(每組變量提取4個公因子)��,這四對變量之間的相關系數依次降低�,從0.980減少到0.561�。顯著性檢驗結果顯示只有前面兩對典型變量的相關系數有統計學意義�。
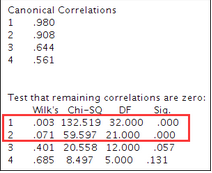
3�、典型變量系數����;下面有四個表格�����,第一行的兩個表是第一組變量抽取典型變量的結果�,作圖使用標準化的原始變量數據����,右圖直接使用原始變量數據���;第二行的兩個表格則是第二組變量抽取典型變量的結果���。根據這些表格的數據可以寫出典型變量的計算公式����。
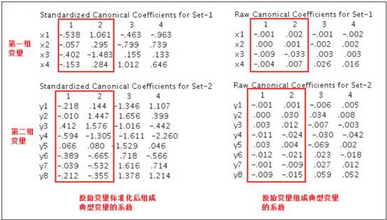
第二步的典型變量相關系數的檢驗結果顯示���,只有前面兩對典型變量的相關系數有統計學意義����,U1與V1的相關系數為0.980����,U2與V2的相關系數為0.908�����,因此下面只寫出這兩對典型變量由標準化數據組成的計算公式:

可以發現�,因為兩組變量的系數很多都是負的���,所以這兩對典型變量的現實含義不好解釋���,原因就在于前面提到的兩組變量內部的相關關系太強����,無法表示農村居民收入的綜合情況�。本案例數據建立的典型相關模型的效果很差�����,應該重新選擇能夠充分反映農村居民收入水平的變量�。
4�����、相關系數結果����;下圖四個表是相關系數表���,第一列是本組變量與本組產生的典型變量的相關系數��;第二列是本組變量與另一組變量產生的典型變量之間的相關系數�。
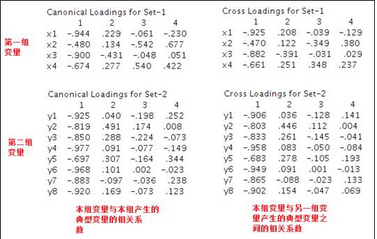
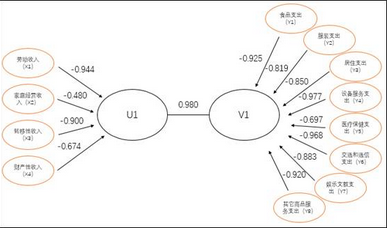
根據相關系數數據���,可以做出兩對典型變量的相關系數結構圖�����,由于作圖的方式是一樣的��,因此用第一對典型變量為例進行說明��。從結構圖同樣可以知道�,四個收入變量與公因子U1的相關系數都是負數���,而8個支出變量與公因子V1的相關系數也都為負數���,同樣說明了本案例的典型相關模型效果很差���,不能用現實含義來解釋�。
推薦學習書籍
《CDA一級教材》適合CDA一級考生備考���,也適合業務及數據分析崗位的從業者提升自我����。完整電子版已上線CDA網校���,累計已有10萬+在讀~

免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
