SPSS分析技術:典型判別分析����;由鳶(yuan)尾花分類發展而來的分析方法
前面介紹的因子分析和聚類分析都是圍繞變量進行的分析����,這里的變量不分因變量和自變量����。因子分析通過變量結構的研究���,達到降低維度的目的����,使數量很多的變量濃縮成少量的互相獨立的公因子�,簡化了后續的分析���;聚類分析通過研究個案(記錄)共有的屬性變量�,依據它們之間距離的遠近��,將數量眾多的個案(記錄)分成幾個類型���。
判別分析有很多類型���,今天介紹的是典型判別分析��,從分析原理來看�����,其與因子分析類似��;從模型結構來看����,則與前面介紹的邏輯回歸相似�。
典型判別分析原理
判別分析與因子分析和聚類分析不同�����,判別分析需要區分因變量和自變量����,其中因變量是分類型數據(定類或定序)�����,而自變量可以是任何尺度的數據�,只是分類型自變量需要以虛擬變量的形式進入判別模型���。以上這些和邏輯回歸模型是一致的���,不同之處在于判別分析的目的是建立原始變量的線性組合�,使得根據因變量劃分的不同類別之間差異最大�,而邏輯回歸模型的擬合方法是極大似然法��,它們在模型擬合方法上是完全不同的��。如果自變量中連續型變量較多���,那么判別分析更為準確�����,如果分類型變量較多�����,則邏輯回歸分析較為好用�����,大家可以根據實際分析結果來選擇�。
判別分析的能夠用于很多領域����,它可以根據已知樣本的分類情況來判斷未知待判樣本的類別歸屬����。例如��,客戶信用風險判別�����、客戶分類��、地層判斷����、模式識別等��,是應用相當廣泛的多元統計技術�����。
典型判別分析是基于方差分析的思想創造出來的��,它試圖找到一個由原始自變量組成的線性函數����,使得不同總體的組間差異與組內差異的比值最大�。如下方左圖所示����,在原始變量X1和X2組成的坐標系中����,兩個總體在兩個坐標軸上都有部分重合����;可喜的是�,通過將原始變量X1和X2線性組合��,可以得到一個新變量(判別函數)�,它可以把兩個總體區分開��。因此只需使用新判別函數代替兩個原始變量對兩個總體進行區別�,就能得到更好的結果�����,這就是典型判別分析的基本思想��。
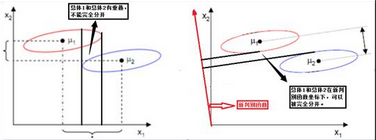
判別分析與因子分析
從上面介紹的典型判別分析原理來看�����,其與因子分析的原理有類似的地方�����,它們都是通過原始變量的線性組合得到新的變量�,從而實現分析目的�。它們的區別主要可以概括成以下兩個方面:
判別分析是因果模型����,研究自變量如何影響因變量���,而因子分析是相依模型��,沒有因變量和自變量之分�。
判別分析的原始變量線性組合的目的是找到新的維度(變量)����,使得因變量的不同類別之間的差異最大�。因子分析的原始變量線性組合的目的是找到新的維度�,減少原始變量的個數�����,避免原始變量的共線性關系影響后續分析��。
案例分析
判別分析最初是由費舍爾(Fisher)在植物分類研究中提出的��,英文簡寫為LDF/DF��,也就是線性判別分析(Linear DiscriminantAnalysis)�。今天案例所使用的數據就是費舍爾當初提出判別分析所用的鳶(yuan)尾花的植株尺寸數據��。

該數據包含剛毛鳶尾花�、變色鳶尾花��、佛吉尼亞鳶尾花的花萼長���、花萼寬�����、花瓣長和花瓣寬數據�����,希望能夠使用這四個變量建立判別不同類型鳶尾花的模型����。數據如下圖所示:
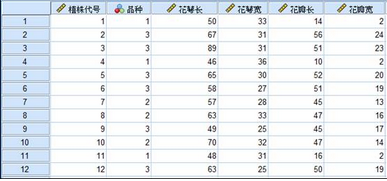
分析步驟
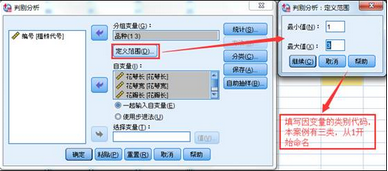
1���、選擇菜單【分析】-【分類】-【判別式】�����。將品種選入分組變量�;將鳶尾花的四個尺寸變量選為自變量��。自變量進入方式選擇一起進入��。如果需要對自變量進行篩選�,也可以選擇步進法�,選中步進法后【方法】按鈕將亮起�,可以選擇距離計算方式��。點擊【定義范圍】����,因為本案例鳶尾花的三個品種代碼分別為1,2,3��,所以最小值填寫1���,最大值填寫3�。
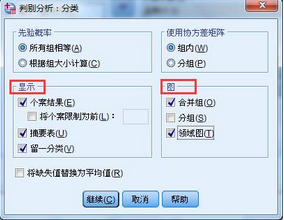
2��、點擊【分類】按鈕�,按照如下方式選擇��。顯示框中的內容是判別分析得結果表格�����。重點強調留一分類�,表示按照數據的順序����,間隔一個記錄選擇進入判別分析模型����,最終一半記錄用于模型分析��,另一半記錄用于模型效果驗證�����。圖框內可供選擇的圖形有三種�,合并圖和分組圖區別在于因變量的三個類型是放入一張圖還是分成三張圖顯示��。
3�、點擊【保存】按鈕�����,將所有三個選項選中����,分析結束后�����,會在數據中新生成三個變量���。
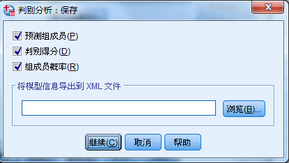
4����、點擊確定�,輸出結果����。
結果解釋
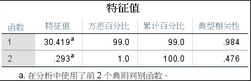
1�����、判別函數特征值���;前面介紹過�����,判別分析與因子分析的原理類似���,判別函數的提取方式和因子分析是一樣的�,通過原始變量的線性組合�����,因此下表的解讀也一樣���。特征根代表攜帶原始變量的信息量大小��,從特征根計算得到方差解釋度(方差百分比)�。本案例只提取兩個判別函數�,第一個判別函數能夠解釋99%的原始變量信息����。
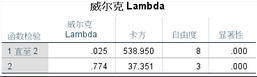
2�����、特征根顯著性檢驗���;原假設是各分組的均值向量相等����,也就是不同分組之間的重心完全重合�,無法進行判別區分�。從結果可知�����,三種鳶尾花的尺寸重心在判別函數1和判別函數2的坐標軸上沒有重合�����,因此兩個判別函數都有意義��。
3����、標準化系數表格��;
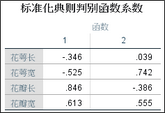
上表顯示兩個判別函數由各個變量組成的標準化系數�,由此可以了解變量對判別函數的影響大小�����。同時可以寫出標準化的判別函數式���。

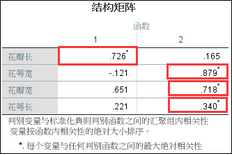
4����、結構矩陣����;判別得分與自變量間的相關系數��。結果中用星號標出與兩個判別函數相關性更大的自變量����。有結果可知����,判別函數1主要與花瓣長變量相關��,花萼長�、花萼寬和花瓣寬則與判別函數2相關性更大��。由前面的特征根知道���,判別函數1攜帶99%的自變量信息����,因此可以推斷花瓣長變量在判別分析中起了最主要的作用����。
5����、判別得分計算公式�����;
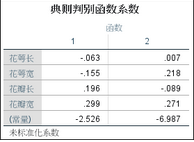
根據上表可以寫出兩個判別得分的計算公式����,這里所用的變量數據為原始數據:

6�、三個鳶尾花品種在兩個判別函數坐標系內的坐標��。
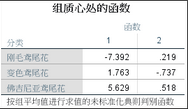
前面的判別函數檢驗就是檢驗三個品種在兩個判別函數上的取值是否相等����。在獲得三個品種的重心后�,只需比較每個個案離哪個重心距離近��,就將該個案判別為哪個類別��。
7����、領域圖���;兩個判別函數分別構成了圖形的兩個坐標軸�,而三個品種的重心用星號表示����,整個平面被兩條分界線分開�。每個個案的判別得分處于哪個部分���,就屬于哪個品種�����。
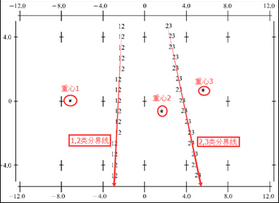
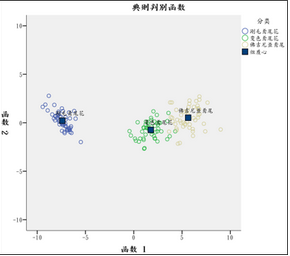
8���、典型判別函數散點圖�����;從散點圖看����,三個品種的鳶尾花在兩個判別函數坐標系內被區分的很開��,效果很不錯�。
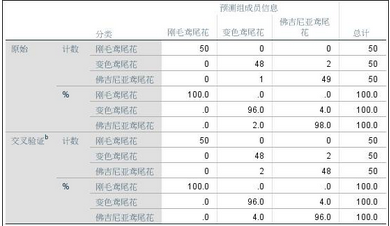
9�、判別結果�����;從結果可知���,150個個案有147個被正確分類�����。而使用“留一分類”方法(一半個案用于判別函數擬合�,另一半用于驗證)得到的結果是146個個案被正確判斷�����,準確率都很高��,說明該判別分析結果可以用于預測����。
推薦學習書籍
《**CDA一級教材**》適合CDA一級考生備考���,也適合業務及數據分析崗位的從業者提升自我����。完整電子版已上線CDA網校���,累計已有10萬+在讀~

免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
