文章來源:數據分析與統計學之美
作者:黃偉呢
1.概述

python字符串應該是python里面最重要的數據類型了�,因此學會怎么處理各種各樣的字符串����,顯得尤為重要�。
我們不僅要學會怎么處理單個字符串���,這個就需要學習“python字符串函數”�����,我們還要學會怎么處理二維表格中每一列每一格的字符串�����,這個就需要學習“pandas的str矢量化字符串函數”��。
今天我們采用對比的方式����,帶大家總結常用的字符串函數��,希望這篇文章能夠對大家起到很好的作用�。
在開始享用這篇文章之前����,請培養好自己的耐心����,本文確實干貨滿滿�,一定要看到最后你才知道收獲有多大���,尤其是后面的str屬性����,超有用�。
2.常用的python字符串函數
字符串中�����,空白符也算是真實存在的一個字符���。
1)python字符串函數大全
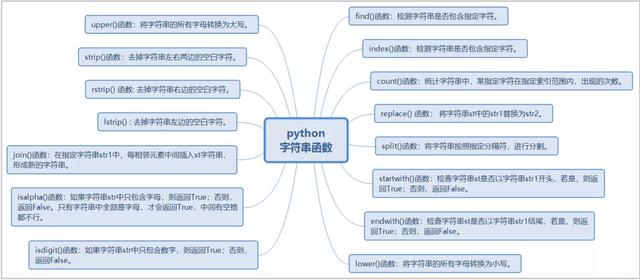
2)函數講解
① find()函數
功能 :檢測字符串是否包含指定字符���。如果包含指定字符�,則返回開始的索引;否則����,返回-1.
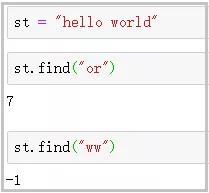
② index()函數
功能 :檢測字符串是否包含指定字符���。如果包含指定字符���,則返回開始的索引;否則��,提示ValueError錯誤���。
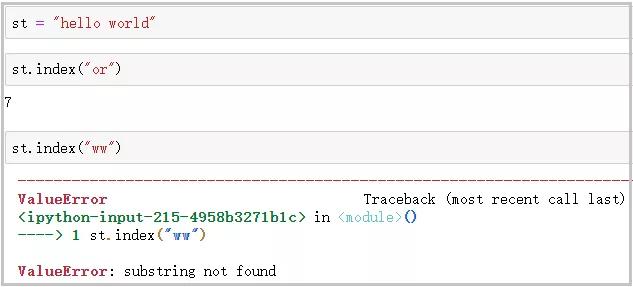
③ count()函數
功能 : 統計字符串中�����,某指定字符在指定索引范圍內����,出現的次數��。
索引范圍 :左閉右開區間�。
注意 :如果不指定索引范圍��,表示在整個字符串中����,搜索指定字符出現的次數���。
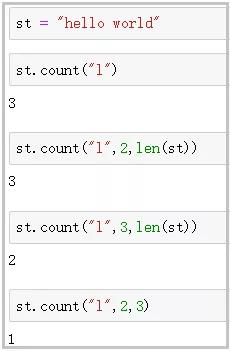
④ replace()函數
語法 :st.replace(str1.str2.count)�����。
功能 :將字符串st中的str1替換為str2.
注意 : 如果不指定count���,則表示整個替換;如果指定count=1.則表示只替換一次�,count=2.則表示只替換兩次���。

⑤ split()
語法 :st.split('分隔符', maxSplit)
功能 :將字符串按照指定分隔符����,進行分割���。
注意 :如果split中什么都不寫���,則默認按照空格進行分割;如果指定了分割符����,則按照指定分隔符�,進行分割�����。
maxSplit作用:不好敘述�,自己看下面的例子就明白�。

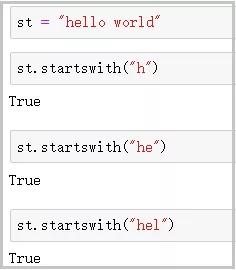
⑥ startswith()函數
語法 :st.startswith(str1)
功能 :檢查字符串st是否以字符串str1開頭��,若是����,則返回True;否則�,返回False���。
⑦ endswith()函數
語法 :st.endswith(str1)
功能 :檢查字符串st是否以字符串str1結尾�����,若是�����,則返回True;否則���,返回False�����。
⑧ lower()
語法 :st.lower()
功能 :將字符串的所有字母轉換為小寫����。
⑨ upper()
語法 :st.upper()
功能 :將字符串的所有字母轉換為大寫�。

⑩ strip()
語法 :st.strip()
功能 :去掉字符串左右兩邊的空白字符����。

注1:st.rstrip() : 去掉字符串右邊的空白字符����。
注2:st.lstrip() : 去掉字符串左邊的空白字符��。
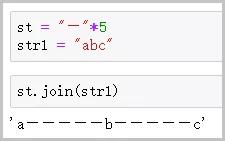
? join()函數
語法 :st.join(str1)
功能 :在指定字符串str1中�,每相鄰元素中間插入st字符串����,形成新的字符串�����。
注意 :是在str1中間插入st�,而不是在st中間插入str1.
? isalpha()
語法 :str.isalpha()
功能 :如果字符串str中只包含字母����,則返回True;否則�,返回False����。
注意 :只有字符串中全部是字母�,才會返回True����,中間有空格都不行��。

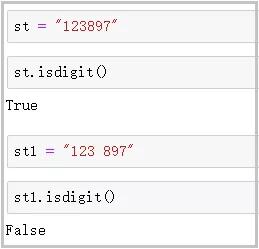
? isdigit()
語法 :str.isdigit()
功能 :如果字符串str中只包含數字��,則返回True;否則���,返回False��。
3.常用的str矢量化字符串函數
str矢量化操作:指的是循環迭代數組里面的某個元素�����,來完成某個操作�����。
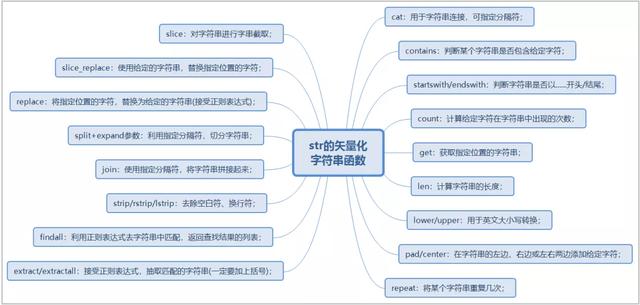
1)str矢量化字符串函數大全
2)構造一個DataFrame�����,用于測試函數
import pandas as pd
df ={'姓名':[' 黃同學','黃至尊','黃老邪 ','陳大美','孫尚香'],
'英文名':['Huang tong_xue','huang zhi_zun','Huang Lao_xie','Chen Da_mei','sun shang_xiang'],
'性別':['男','women','men','女','男'],
'身份證':['463895200003128433','429475199912122345','420934199110102311','431085200005230122','420953199509082345'],
'身高':['mid:175_good','low:165_bad','low:159_bad','high:180_verygood','low:172_bad'],
'家庭住址':['湖北廣水','河南信陽','廣西桂林','湖北孝感','廣東廣州'],
'電話號碼':['13434813546','19748672895','16728613064','14561586431','19384683910'],
'收入':['1.1萬','8.5千','0.9萬','6.5千','2.0萬']}
df = pd.DataFrame(df)
df
結果如下:
3)函數講解
① cat函數:用于字符串的拼接
df["姓名"].str.cat(df["家庭住址"],sep='-'*3)
結果如下:

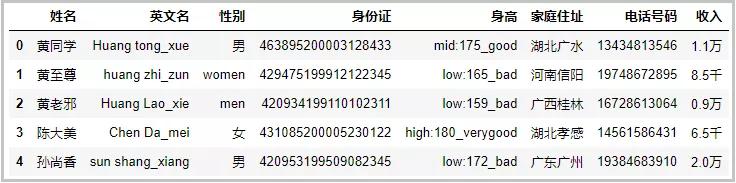
② contains:判斷某個字符串是否包含給定字符
df["家庭住址"].str.contains("廣")
結果如下:
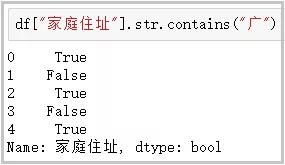
③ startswith/endswith:判斷某個字符串是否以...開頭/結尾
# 第一個行的“ 黃偉”是以空格開頭的
df["姓名"].str.startswith("黃")
df["英文名"].str.endswith("e")
結果如下:
④ count:計算給定字符在字符串中出現的次數
df["電話號碼"].str.count("3")
結果如下:

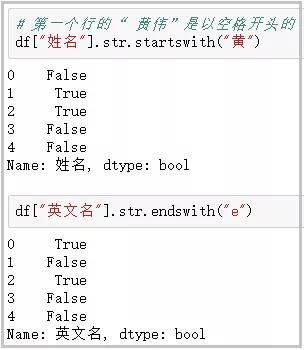
⑤ get:獲取指定位置的字符串
df["姓名"].str.get(-1)
df["身高"].str.split(":")
df["身高"].str.split(":").str.get(0)
結果如下:
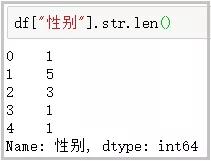
⑥ len:計算字符串長度
df["性別"].str.len()
結果如下:
⑦ upper/lower:英文大小寫轉換
df["英文名"].str.upper()
df["英文名"].str.lower()
結果如下:

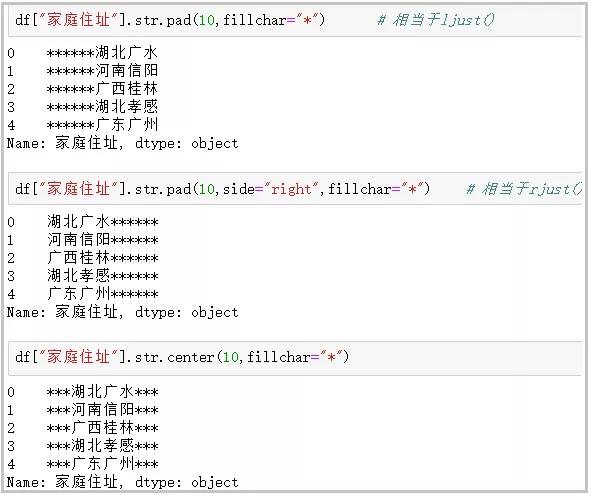
⑧ pad+side參數/center:在字符串的左邊�����、右邊或左右兩邊添加給定字符
df["家庭住址"].str.pad(10.fillchar="*") # 相當于ljust()
df["家庭住址"].str.pad(10.side="right",fillchar="*") # 相當于rjust()
df["家庭住址"].str.center(10.fillchar="*")
結果如下:
⑨ repeat:重復字符串幾次
df["性別"].str.repeat(3)
結果如下:

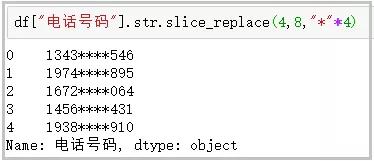
⑩ slice_replace:使用給定的字符串����,替換指定的位置的字符
df["電話號碼"].str.slice_replace(4.8."*"*4)
結果如下:
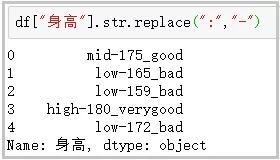
? replace:將指定位置的字符�,替換為給定的字符串
df["身高"].str.replace(":","-")
結果如下:
? replace:將指定位置的字符����,替換為給定的字符串(接受正則表達式)
replace中傳入正則表達式��,才叫好用;
先不要管下面這個案例有沒有用�����,你只需要知道�,使用正則做數據清洗多好用;
df["收入"].str.replace("\d+\.\d+","正則")
結果如下:

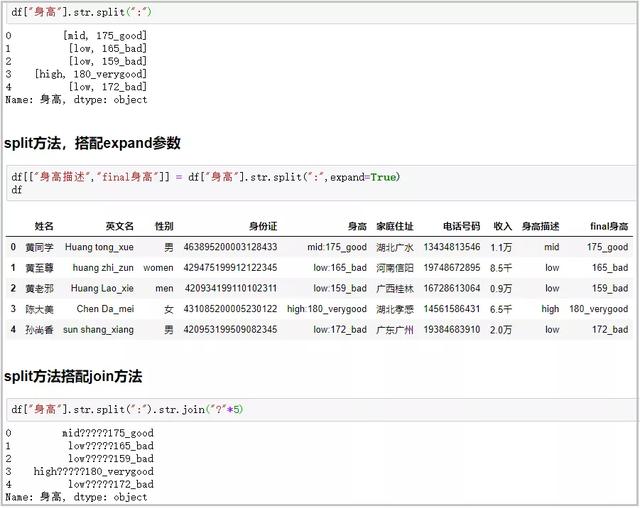
? split方法+expand參數:搭配join方法功能很強大
# 普通用法
df["身高"].str.split(":")
# split方法�����,搭配expand參數
df[["身高描述","final身高"]] = df["身高"].str.split(":",expand=True)
df
# split方法搭配join方法
df["身高"].str.split(":").str.join("?"*5)
結果如下:
? strip/rstrip/lstrip:去除空白符���、換行符
df["姓名"].str.len()
df["姓名"] = df["姓名"].str.strip()
df["姓名"].str.len()
結果如下:

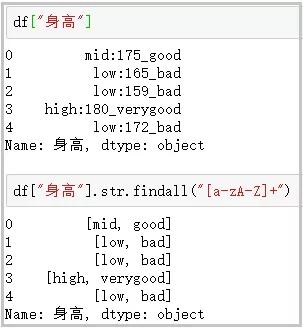
? findall:利用正則表達式���,去字符串中匹配�����,返回查找結果的列表
findall使用正則表達式��,做數據清洗��,真的很香!
df["身高"]
df["身高"].str.findall("[a-zA-Z]+")
結果如下:
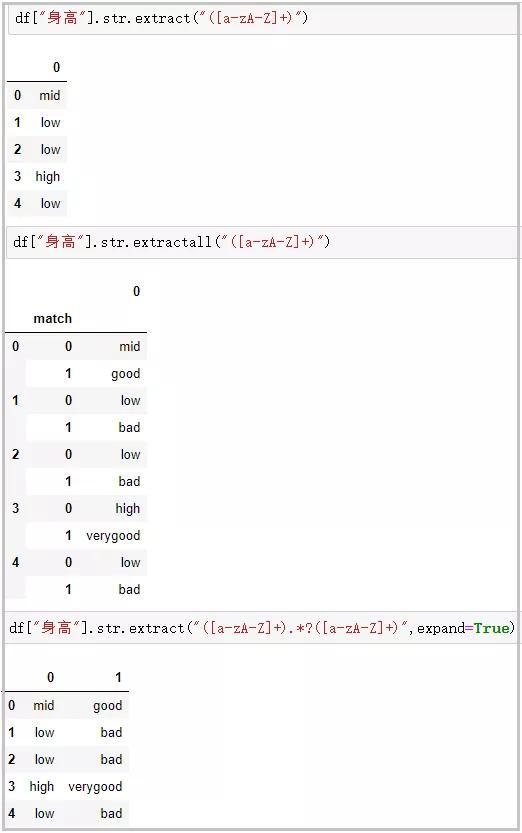
? extract/extractall:接受正則表達式����,抽取匹配的字符串(一定要加上括號)
df["身高"].str.extract("([a-zA-Z]+)")
# extractall提取得到復合索引
df["身高"].str.extractall("([a-zA-Z]+)")
# extract搭配expand參數
df["身高"].str.extract("([a-zA-Z]+).*?([a-zA-Z]+)",expand=True)
結果如下:
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
