一�����、欠擬合概念及理解
機器學習中欠擬合是一個常見的問題��,簡單來說就是模型在訓練和預測時表現都欠佳的情況���。一個欠擬合的機器學習模型不是一個良好的模型并且在訓練數據上表現不好這是顯而易見的��。
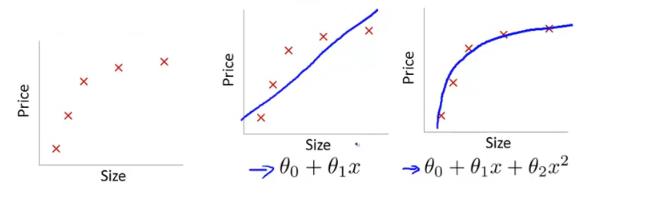
圖中左邊的表示size與prize關系的數據���,中間的是出現欠擬合的模型�����,可以看出模型不能夠很好地擬合數據���,但如果將一個二次項添加到此模型的后面��,就可以很好地擬合圖中的數據了���,就會有右側的效果��。
欠擬合問題�,根本的原因是特征維度過少�����,導致擬合的函數無法滿足訓練集��,誤差較大���。
二�、常用的解決欠擬合問題的方法:
1.模型復雜化
對同一個算法復雜化����。例如回歸模型添加更多的高次項�,增加決策樹的深度����,增加神經網絡的隱藏層數和隱藏單元數等
棄用原來的算法��,使用一個更加復雜的算法或模型����。例如用神經網絡來替代線性回歸����,用隨機森林來代替決策樹等
2.增加更多的特征��,使輸入數據具有更強的表達能力
特征挖掘十分重要�,質量高的強表達能力的特征����,抵得過大量弱表達能力的特征�����。但是挖掘強特���,還必須對數據本身以及具體應用場景的深刻理解����,這需要依賴于過往經驗��。
3.調整參數和超參數
超參數包括:
神經網絡中:學習率�����、學習衰減率�、隱藏層數����、隱藏層的單元數��、Adam優化算法中的β1β1和β2β2參數�����、batch_size數值等
其他算法中:隨機森林的樹數量�,k-means中的cluster數�,正則化參數λλ等
4.降低正則化約束
正則化約束是為了防止模型出現過擬合�����,現在模型的情況是欠擬合了�,就需要降低正則化參數λλ或者直接去除正則化項
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
