過擬合(over-fitting)是指機器學習模型或者是深度學習模型在訓練樣本中表現得過于優越�,導致在驗證數據集以及測試數據集中表現不佳����。也就是referstoa模型對于訓練數據擬合程度過高的情況����。
通過學習曲線來理解:
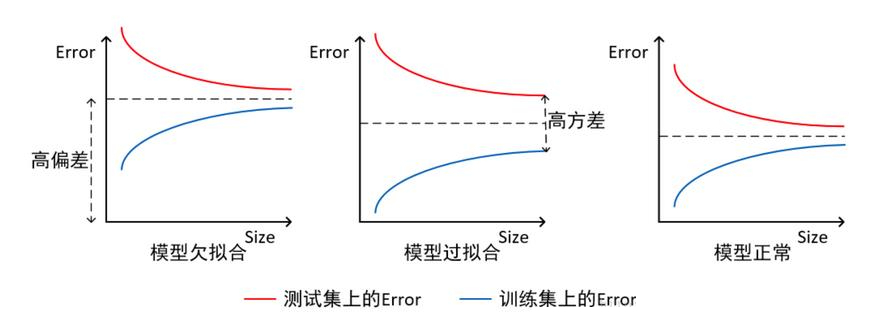
當某個模型對訓練數據中的細節和噪音學習過度之后�,會使得模型在新的數據上表現很不好����,這是就是過擬合·�。這種情況意味著模型把訓練數據中的噪音或者隨機波動也被當做概念學習了�����。但是這些概念不適用于新的數據�,從而導致模型泛化能力的越來越差�。
1.過擬合常見原因
1)根本的原因則是特征維度(或參數)過多����,導致擬合的函數完美的經過訓練集�����,但是對新數據的預測結果則較差�����。
2)建模樣本選取有誤�,如樣本數量太少�����,數量級要小于模型的復雜度�����,或者選樣方法錯誤�,樣本標簽錯誤等��,導致樣本數據不足以代表預定的分類規則;
3)樣本噪音干擾過大��,模型過分記住了噪音特征��,從而擾亂了預設的分類規則;
4)假設的模型無法合理存在����,或者說是假設成立的條件實際并不成立;
5)對于決策樹模型���,如果我們對于其生長沒有合理的限制�����,其自由生長有可能使節點只包含單純的事件數據(event)或非事件數據(no event)���,使其雖然可以完美匹配(擬合)訓練數據��,但是無法適應其他數據集�。
6)對于神經網絡模型:
a)對樣本數據可能存在分類決策面不唯一�����,隨著學習的進行,����,BP算法使權值可能收斂過于復雜的決策面;
b)權值學習迭代次數足夠多(Overtraining)����,擬合了訓練數據中的噪聲和訓練樣例中沒有代表性的特征����。
2.過擬合問題解決方法
1)重新清洗數據;
2)增大數據的訓練量;
3)采用正則化方法����,包括L0正則��、L1正則和L2正則;
4)減少特征數量;
5)降低模型的復雜度���;
6)使用Dropout(只適用于神經網絡中�����,將隱藏層的神經單元按一定比例去除�����,使神經網絡的結構簡單化)
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
