前面小編給大家簡單介紹過擬合和欠擬合時��,提到了一個概念:學習曲線���,我們通過學習曲線能夠很清晰的判別出模型現在說出的狀態是欠擬合還是過擬合���,下面小編具體整理了學習曲線的相關內容�����,希望對大家有所幫助����。
學習曲線(learning curve)是不同訓練集大小����,模型在訓練集和驗證集上的得分變化曲線��。橫坐標為·樣本數�,縱坐標為訓練和交叉驗證集上的得分(如準確率)���。
模型在新數據上的表現如何��,都能清晰地在展現在學習去線上��,我們也能通過這些表現�,進而判斷模型是否方差偏高或者偏差過高����,以及增大訓練集是否可以減小過擬合�����。
如圖所示:
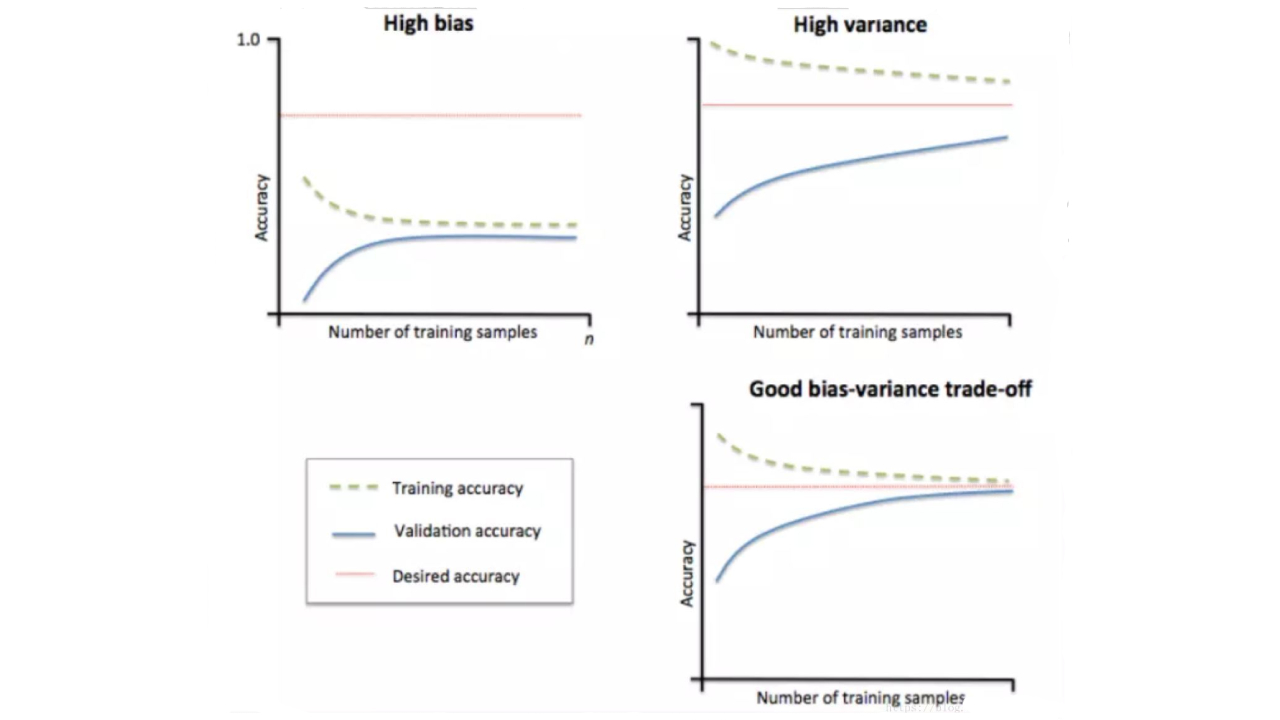
(1)當訓練集和測試集的誤差收斂但卻很高時�,為高偏差�����。
左上圖中訓練集和驗證集上的曲線能夠收斂���,但偏差很高���,訓練集和驗證集上準確率相差很大����,卻都很差���。這種情況下模型對已知數據和未知數據都不能進行準確的預測�����,很可能是欠擬合���。
方法:
增加模型參數���,采用更復雜的模型�,減小正則項�。
注意:此時通過增加數據量是不起作用的�。
(2)當訓練集和測試集上誤差之間有大的差距時�����,為高方差�����。
當訓練集的準確率比其他獨立數據集上的測試結果的準確率要高時����,一般都是過擬合����。
右上圖中��,訓練集和驗證集的準確率差距很大���,這種情況下���,模型能夠很好的擬合已知數據�����,但是泛化能力不足��,屬于高方差���,很可能是過擬合���。
方法:
增大訓練集����,降低模型復雜度��,增大正則項�,或者通過特征選擇減少特征數���。
(3)右下方圖�����,也是最理想情況:找到偏差和方差都很小的狀態����,就是收斂而且誤差較小����。
學習曲線的具體操作:
len(X_train) 個訓練樣本�����,訓練出 len(X_train) 個模型��,第一次使用一個樣本訓練出第一個模型�,第二次使用兩個樣本訓練出第二個模型�,… �,第 len(X_train) 次使用 len(X_train) 個樣本訓練出最后一個模型;
每個模型對于訓練這個模型所使用的部分訓練數據集的預測值:y_train_predict = 模型.predict(X_train[ : i ]);
每個模型對于訓練這個模型所使用的部分訓練數據集的均方誤差:mean_squared_error(y_train[ : i ], y_train_predict);
每個模型對于整個測試數據集的預測值:y_test_predict = 模型.predict(X_test)
每個模型對于整個測試數據集的預測的均方誤差:mean_squared_error(y_test, y_test_predict);
繪制每次訓練模型所用的樣本數量與該模型對應的部分訓練數據集的均方誤差的平方根的關系曲線:plt.plot([i for i in range(1. len(X_train)+1)],np.sqrt(train_score), label=“train”)
繪制每次訓練模型所用的樣本數量與該模型對應的測試數據集的預測的均方誤差的關系曲線:plt.plot([i for i in range(1. len(X_train)+1)],np.sqrt(test_score), label=“test”)
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
