層次聚類�����,即Hierarchical Clustering��,是一種聚類算法���,通過對不同類別數據點間的相似度的計算����,從而創建一棵有層次的嵌套聚類樹��。
一�����、層次聚類算法原理
在聚類樹中�����,樹的最底層是不同類別的原始數據點�,樹的頂層則是一個聚類的根節點��。層次聚類算法按照層次分解的順序可分為:自下向上也�����,就是凝聚的層次聚類算法����,以及自上向下即分裂的層次聚類算法(agglomerative和divisive)�����,又可以被稱為自下而上法(bottom-up)和自上而下法(top-down)���。自下而上法簡單理解為:一開始每一個個體(object)都是一個類���,然后再根據linkage尋找同類����,最后合并���,形成一個“類”�����。自上而下法與自下而上法相反����,是開始所有個體都歸屬于一個“類”��,然后通過linkage排除異類��,最后每一個個體都成為一個“類”���。

在層次聚類算法中, 最關鍵的在于計算兩個聚類間的距離�����,根據計算兩個聚類之間距離的算法的不同��,能夠分為以下四種聚類算法:
Single Linkage:兩個數據集間的最小距離
Complete Linkage:兩個數據集間的最大距離
以上兩種方法很容易受到極端值的影響�,計算大樣本集效率較高����。
Average Linkage:任意兩個數據集的距離之和的平均值�。這種方法雖然計算量比較大��,但是這種度量方法更合理�。
Ward:最小化簇內方差�。假設聚類A的中心點為a��,聚類B的中心點為b����,A���、B合并后的聚類為C�,其中心點為c���,則聚類A��、B的距離為:
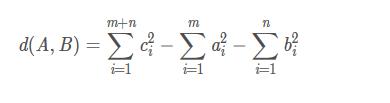
二�、層次聚類的優缺點
優點:
1.距離和規則的相似度比較容易定義�,限制很少;
2.不需要預先制定聚類數;
3.能夠發現類的層次關系;
4.能夠聚類成其它形狀
缺點:
1.計算的復雜度很高;
2.即使是奇異值也會產生很大影響;
3.算法很可能會聚類成鏈狀
三��、sklearn中的層次聚類
##導入庫
from sklearn.cluster import AgglomerativeClustering
##建模���,并指定聚類個數
ward = AgglomerativeClustering(n_clusters=3)
##擬合并預測數據
ward_pred = ward.fit_predict(data)
繪制系統樹:
from scipy.cluster.hierarchy import linkage,dendrogram
import matplotlib.pyplot as plt
#指定連接類型為離差平方和法
linkage_type = ‘ward’
#擬合數據���,并得到關聯矩陣
linkage_matrix = linkage(X, linkage_type)
#創建窗口
plt.figure(figsize=(22.18))
#將關聯矩陣輸送到系統方法
dendrogram(linkage_matrix)
#顯示
plt.show()
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
