scrapy一個開源和協作的框架����,最初的設計目的為:頁面抓?����。ǜ鼫蚀_來說是網絡抓?�。?,因此scrapy能夠以簡便���、快捷·��、可擴展的方式從網站中提取所需的信息?����,F階段scrapy的應用十分廣泛��,能夠用于挖掘����、監測和自動化測試等許多領域�,也可以被用在API所返回的數據�����,就像:Amazon Associates Web Services�,或者通用的網絡爬蟲等方面���。 scrapy是基于twisted框架而開發出來的���,twisted是一個流行的事件驅動的python網絡框架�����,所以通過利用一種非阻塞(又被稱為異步)的代碼來實現并發��。
一����、scrapy架構
scrapy框架主要由以下·六大組件組成:調試器(Scheduler)��、下載器(Downloader)�����、爬蟲(Spider)���、中間件(Middleware)�����、實體管道(Item Pipeline)和Scrapy引擎(Scrapy Engine)
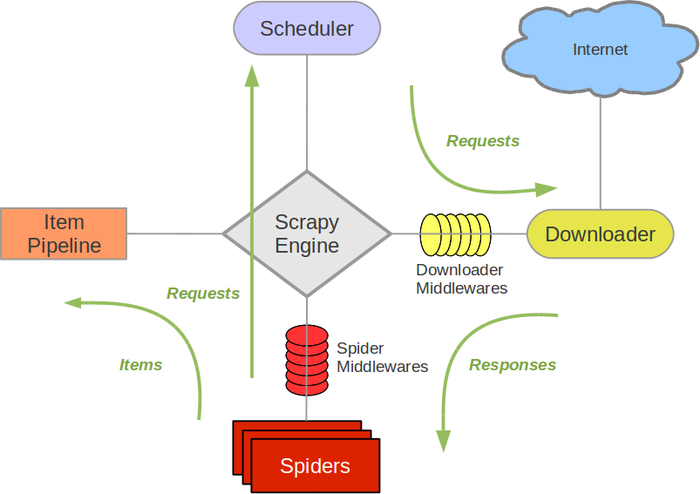
1���、Scrapy Engine(引擎): 主要負責控制所有組件間的數據流����,并在相應動作觸發事件時進行處理���。
2����、Scheduler(調度器): 調度器從引擎接受請求�����,并將這些請求放入隊列中����,并在之后返回給引擎��。
3����、Downloader(下載器): 下載器負責根據引擎的請求����,獲取頁面數據并反應給引擎�����,之后提供給spider��。
4���、Spider(爬蟲): 每一個spider負責處理一個(或一些)特定網站�,Spider發出請求�����,并對引擎返回給它下載器響應數據進行處理�,以items和規則內的數據請求(urls)返回給引擎�����。
5��、Item Pipeline(管道): Item Pipeline負責處理被spider提取出來的數據��,并將數據持久化�。
6�����、Downloader Middlewares(下載中間件): 下載器中間件是在引擎及下載器之間的交互組件�,也被稱為特定鉤子(specific hook)�,能夠代替接收請求����、處理數據的下載��, 并將結果提供給引擎�。
7�、Spider Middlewares(Spider中間件): Spider中間件是在引擎及Spider之間的特定鉤子(specific hook)����,處理spider的輸入(response)和輸出(items及requests)��。 其提供了一個簡便的機制�����,通過插入自定義代碼來擴展Scrapy功能�。
二���、scrapy安裝
windows環境配置
scrapy依賴包(或者到官網單獨下載各文件安裝):
1.lxml: pip install wheel
2.zope.interface:pip install zope.interface-4.3.3-cp35-cp35m-win_amd64.whl
3.pyOpenSSL:pip install pyOpenSSL
4.Twisted:pip install Twisted
5.Scrapy:pip install Scrapy
如果還沒安裝���,Anoconda+Pycharm+Scrapy Anaconda�����,先到http://www.continuum.io/downloads下載對應平臺的包安裝��。如果已經安裝��,直接通過conda命令安裝Scrapy��。conda install scrapy
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
