BeautifulSoup是一款靈活又便捷的HTML/XML的解析器��,通常被用來解析和提取 HTML/XML 數據�。BeautifulSoup處理速度快��,效率高����,而且支持多種解析器����,不用編寫正則表達式也能快速地實現網頁信息的提取�����。
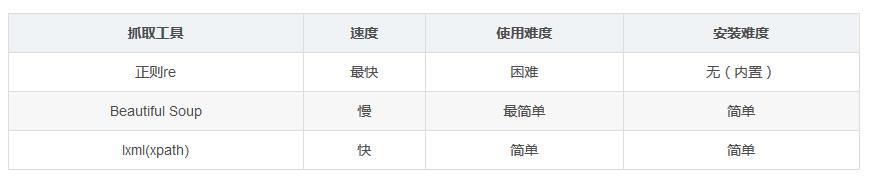
1��、BeautifulSoup與其他抓取工具的對比:
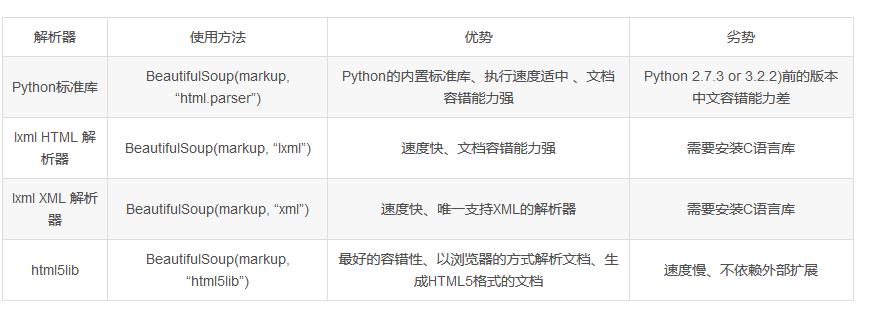
2���、解析庫
3��、安裝
(1)pip3 install beautifulsoup
(2)導入模塊:from bs4 import BeautifulSoup
(3) 創建BeautifulSoup對象
參數一:解析的文本內容
參數二:使用的解析器�����,一般為lxml(必須添加����,否則會發出警告)
(4)格式化輸出 soup 對象的內容
4�����、基本使用
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1"><!-- Elsie --></a>,
<a class="sister" id="link2">Lacie</a> and
<a class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')#傳入解析器:lxml
print(soup.prettify())#格式化代碼�,自動補全
print(soup.title.string)#得到title標簽里的內容
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
