關于Kafka��,相信大家都不陌生�,一個消息流的處理平臺�,目前很多開發人員都把它當做一個生產&消費的中間件����。今天小編就跟大家系統介紹一下Kafka�,希望對大家有所幫助���。
一��、Kafka概念
Kafka是一個消息系統����,用作LinkedIn的活動流(Activity Stream)和運營數據處理管道(Pipeline)的基礎�。Kafka是由LinkedIn開發出來的���,一個分布式基于發布/訂閱的消息系統�,使用Scala進行編寫����。 Kafka具有更高的吞吐量�,內置的分區也使得kafka具有更好的容錯和伸縮性���,這些特性使得 Kafka應用廣泛��,是大型消息處理應用的首選之策����。
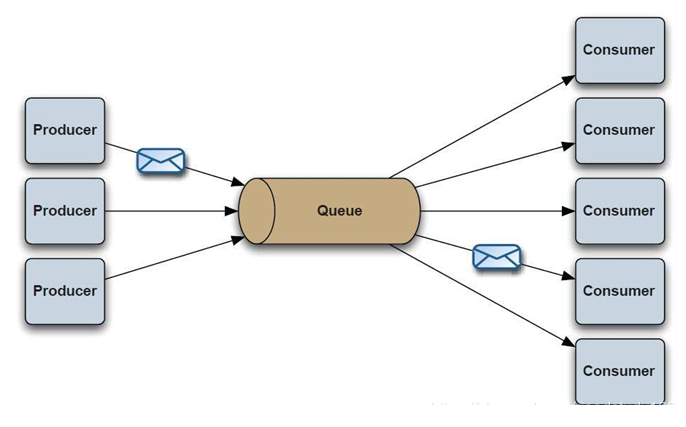
Kafka是一種高吞吐量的分布式發布訂閱消息系統���,它可以處理消費者規模的網站中的所有動作流數據����。簡單來理解����,Kafka就像是一個郵箱�,生產者可以當做發送郵件的人���,消費者就是收郵件的人��,Kafka是用來存東西的平臺����,只不過Kafka提供了一些處理郵件的機制��。
二���、Kafka基本架構
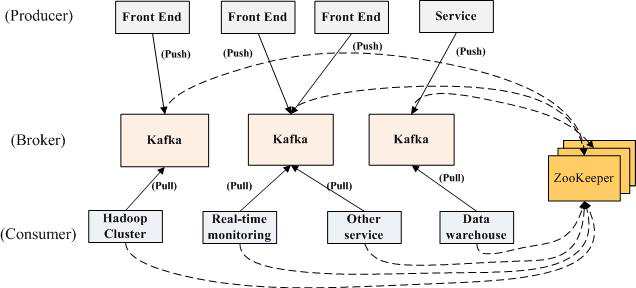
Broker:Kafka節點����,一個Kafka節點就是一個broker�����,多個broker能夠組成一個Kafka集群
Topic:一類消息�����,消息存放的目錄也就是主題�,比兔page view日志���、click日志等���,都能夠以topic的形式存在�,Kafka集群可以同時負責多個topic的分發
massage: Kafka中最基本的傳遞對象�����。
Partition:topic物理上的分組�,每個topic包含partition��,每個partition是一個有序的隊列
Segment:partition物理上由多個segment組成�,每個Segment存著message信息
Producer : 生產者�����,負責生產message發布到topic
Consumer : 消息消費者���,訂閱topic并消費message, consumer從broker拉取(pull)數據并進行處理�����。
Consumer Group:消費者組��,一個Consumer Group包含多個consumer
Offset:偏移量����,消息partition中的索引即可
三����、Kafka優勢
1. 分布式
大數據處理業務中極為重要的流處理框架���,分布式是Kafka的天然屬性��。
2. 高性能:
Kafka高性能體現在兩方面:(1)高吞吐量����,最高能達到幾十萬每秒的級別的吞吐量;(2)低延時����,這使得Kafka能夠很好的配合SparkStreaming等其它流式處理框架的進行數據實時性處理�����。
3. 持久性和擴展性:
這兩點是Kafka區別于其它消息隊列的重要特點����,主要體現在:(1)數據可持久化�,(2) 容錯性;(3)大水平方向上擴展;(4) 消息自動平等����,避免熱點問題��。
四���、Kafka常用場景
(1)消息隊列
(2)網站活性跟蹤
(3)可操作的監控數據
(4)日志收集
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
