feature importance��,根據含義就能理解����,也就是特征重要性��,在預測建模項目中起著非常重要作用���,能夠提供對數據��、模型的見解�,和如何進行降維和選擇特征���,并以此來提高預測模型的的效率和有效性�����。今天小編為大家帶來的是如何理解隨機森林中的feature importance��,希望對大家有所幫助����。
一���、簡單了解feature importance
實際情況中����,一個數據集中往往包含數以萬計個特征����,如何在其中選擇出�����,結果影響最大的幾個特征���,并通過這種方法縮減建立模型時的特征數�,這是我們最為關心的問題�����。今天要介紹的是:用隨機森林來對進行特征篩選����。
用隨機森林進行特征重要性評估的思想其實非常簡單�����,簡單來說�,就是觀察每個特征在隨機森林中的每顆樹上做了多少貢獻����,然后取平均值�����,最后對比特征之間的貢獻大小���。
總結一下就是:特征重要性是指���,在全部單顆樹上此特征重要性的一個平均值���,而單顆樹上特征重要性計算方法事:根據該特征進行分裂后平方損失的減少量的求和�。

二����、feature importance評分作用
1.特征重要性分可以凸顯出特征與目標的相關相關程度�,能夠幫助我們了解數據集
2.特征重要性得分可以幫助了解模型
特征重要性得分通常是通過數據集擬合出的預測模型計算的�����。查看重要性得分能夠洞悉此特定模型����,以及知道在進行預測時特征的重要程度����。
3.特征重要性能夠用于改進預測模型
我們可以通過特征重要性得分來選擇要刪除的特征(即得分最低的特征)或者需要保留的特征(即得分最高的特征)�。這其實是一種特征選擇���,能夠簡化正在建模的問題����,加快建模過程����,在某些情況下���,還能夠改善模型的性能�����。
三�、python實現隨機森林feature importances
import xlrd
import csv
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.interpolate import spline
#設置路徑
path='/Users/kqq/Documents/postgraduate/煙葉原始光譜2017.4.7數字產地.csv'
#讀取文件
df = pd.read_csv(path, header = 0)
#df.info()
#訓練隨機森林模型
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import RandomForestClassifier
x, y = df.iloc[:, 1:].values, df.iloc[:, 0].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
feat_labels = df.columns[1:]
forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1)
forest.fit(x_train, y_train)
#打印特征重要性評分
importances = forest.feature_importances_
#indices = np.argsort(importances)[::-1]
imp=[]
for f in range(x_train.shape[1]):
print(f + 1, feat_labels[f], importances[f])
#將打印的重要性評分copy到featureScore.xlsx中����;plot特征重要性
#設置路徑
path='/Users/kqq/Documents/postgraduate/實驗分析圖/featureScore.xlsx'
#打開文件
myBook=xlrd.open_workbook(path)
#查詢工作表
sheet_1_by_index=myBook.sheet_by_index(0)
data=[]
for i in range(0,sheet_1_by_index.nrows):
data.append(sheet_1_by_index.row_values(i))
data=np.array(data)
X=data[:1,].ravel()
y=data[1:,]
plt.figure(1,figsize=(8, 4))
i=0
print(len(y))
while i 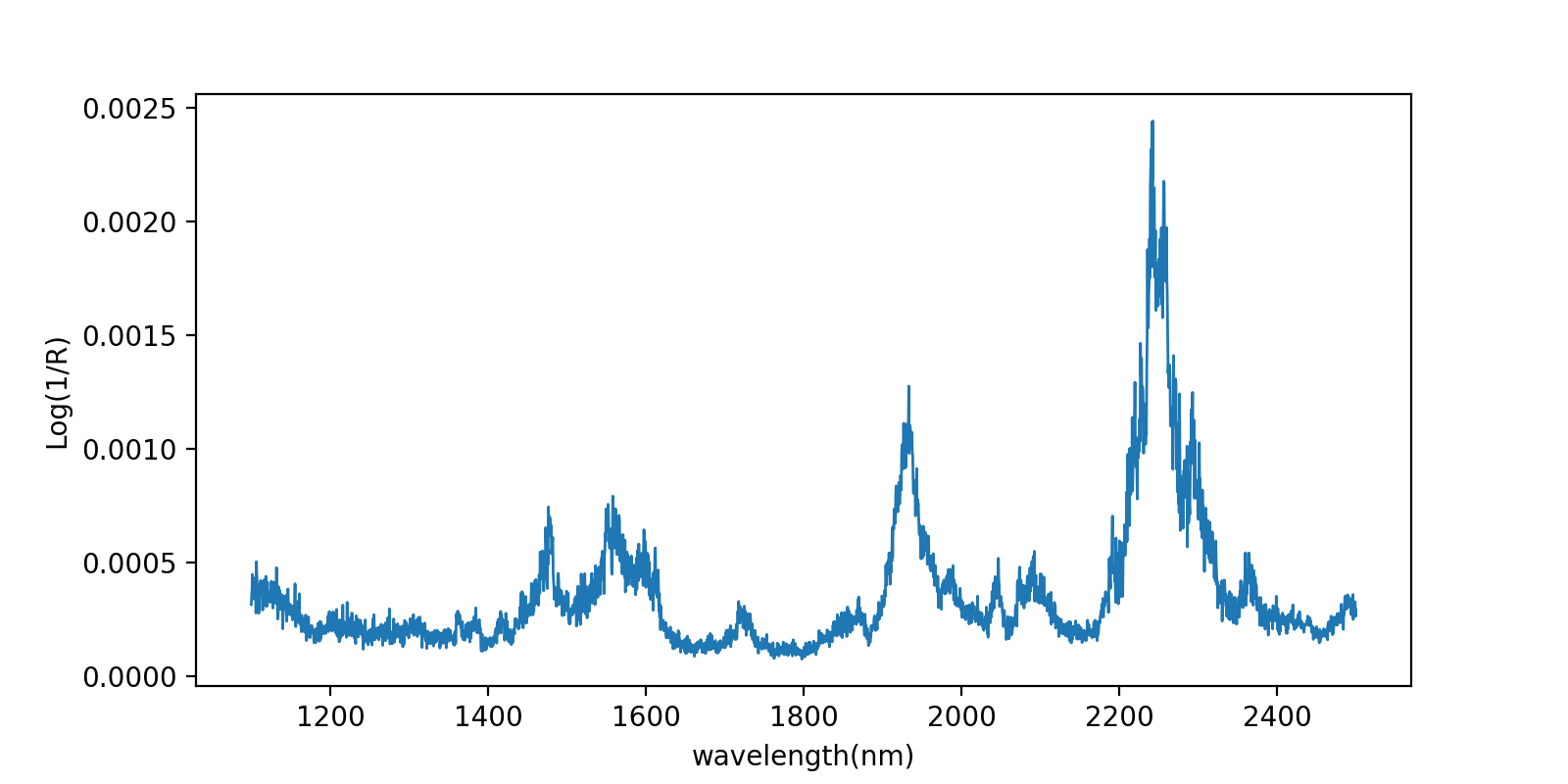
相信讀完上文�����,你對算法已經有了全面認識��。若想進一步探索機器學習的前沿知識�����,強烈推薦機器學習之半監督學習課程���。

學習入口:https://edu.cda.cn/goods/show/3826?targetId=6730&preview=0
涵蓋核心算法����,結合多領域實戰案例�,還會持續更新����,無論是新手入門還是高手進階都很合適�����。趕緊點擊鏈接開啟學習吧���!
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
