前面小編在介紹FP-Growth算法時�����,提到了Apriori算法���,其實FP-Growth是基于Apriori的�����,今天小編就具體給大家介紹一下Apriori算法����。
一���、什么是Apriori算法
Apriori算法是一種最有影響的挖掘數據關聯規則頻繁項集的算法����,能夠發現事物數據庫中頻繁出現的數據集��,通過這些聯系構成的規則����,能夠幫助用戶找出某些行為特征�����,從而幫助企業進行決策�����。
Apriori算法基于這樣的事實:算法使用頻繁項集性質的先驗知識���。Apriori使用一種稱作逐層搜索的迭代方法��,k-項集用于探索(k+1)-項集��。首先����,找出頻繁1-項集的集合���。該集合記作L1.L1用于找頻繁2-項集的集合L2.而L2用于找L3.如此下去�����,直到不能找到頻繁k-項集���。找每個Lk需要一次數據庫掃描�。
算法原始數據如下:
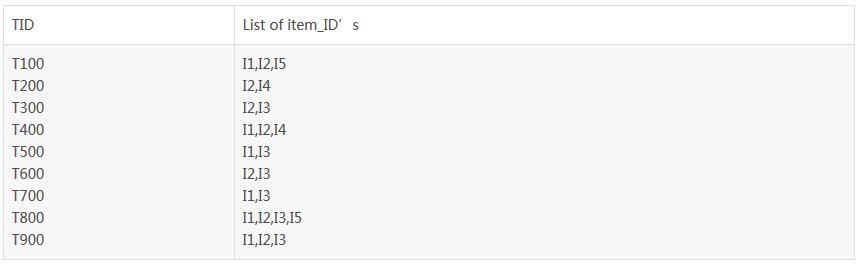
算法的基本過程如下圖:
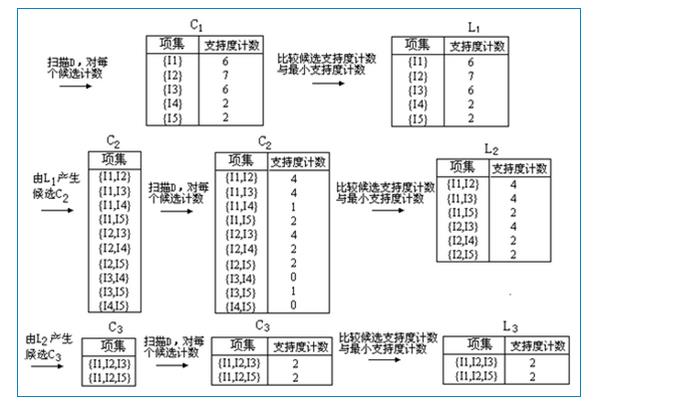
二��、Apriori算法原理
1.掃描數據集����,得到所有出現過的數據�,作為候選1項集�。
2.挖掘頻繁k項集���。
3.掃描計算候選k項集的支持度�����。
4.剪枝去掉候選k項集中支持度低于最小支持度α的數據集���,得到頻繁k項集�����。如果頻繁k項集為空�,則返回頻繁k-1項集的集合作為算法結果�����,算法結束����。如果得到的頻繁k項集只有一項���,則直接返回頻繁k項集的集合作為算法結果���,算法結束��。
5.基于頻繁k項集��,連接生成候選k+1項集��。
6.利用步驟2.迭代得到k=k+1項集結果�����。
三����、Apriori算法利弊分析
1.利:
適合于稀疏數據集����。
算法原理簡單��,很容易實現�����。
適合事務數據庫的關聯規則挖掘��。
2.弊
有可能產生龐大的候選集��。
算法需多次遍歷數據集��,效率比較低��,而且耗時���。
三�、算法實現
假如有項目集合I={1�,2��,3�,4�����,5}�����,有事務集T:
1,2,3
1,2,4
1,3,4
1,2,3,5
1,3,5
2,4,5
1,2,3,4
設定minsup=3/7�����,misconf=5/7�。
*Apriori算法 2012.10.31*/
#include <iostream>
#include <vector>
#include <map>
#include <string>
#include <algorithm>
#include <cmath>
using namespace std;
vector<string> T; //保存初始輸入的事務集
double minSup,minConf; //用戶設定的最小支持度和置信度
map<string,int> mp; //保存項目集中每個元素在事務集中出現的次數
vector< vector<string> > F; //存放頻繁項目集
vector<string> R; //存放關聯規則
void initTransactionSet() //獲取事務集
{
int n;
cout<<"請輸入事務集的個數:"<<endl;
cin>>n;
getchar();
cout<<"請輸入事務集:"<<endl;
while(n--)
{
string str;
getline(cin,str); //輸入的事務集中每個元素以空格隔開,并且只能輸入數字
T.push_back(str);
}
cout<<"請輸入最小支持度和置信度:"<<endl; //支持度和置信度為小數表示形式
cin>>minSup>>minConf;
}
vector<string> split(string str,char ch)
{
vector<string> v;
int i,j;
i=0;
while(i<str.size())
{
if(str[i]==ch)
i++;
else
{
j=i;
while(j<str.size())
{
if(str[j]!=ch)
j++;
else
break;
}
string temp=str.substr(i,j-i);
v.push_back(temp);
i=j+1;
}
}
return v;
}
void genarateOneFrequenceSet() //生成1-頻繁項目集
{
int i,j;
vector<string> f; //存儲1-頻繁項目集
for(i=0;i<T.size();i++)
{
string t = T[i];
vector<string> v=split(t,' '); //將輸入的事務集進行切分��,如輸入1 2 3�����,切分得到"1","2","3"
for(j=0;j<v.size();j++) //統計每個元素出現的次數�,注意map默認按照key的升序排序
{
mp[v[j]]++;
}
}
for(map<string,int>::iterator it=mp.begin();it!=mp.end();it++) //剔除不滿足最小支持度要求的項集
{
if( (*it).second >= minSup*T.size())
{
f.push_back((*it).first);
}
}
F.push_back(T); //方便用F[1]表示1-頻繁項目集
if(f.size()!=0)
{
F.push_back(f);
}
}
bool judgeItem(vector<string> v1,vector<string> v2) //判斷v1和v2是否只有最后一項不同
{
int i,j;
i=0;
j=0;
while(i<v1.size()-1&&j<v2.size()-1)
{
if(v1[i]!=v2[j])
return false;
i++;
j++;
}
return true;
}
bool judgeSubset(vector<string> v,vector<string> f) //判斷v的所有k-1子集是否在f中
{
int i,j;
bool flag=true;
for(i=0;i<v.size();i++)
{
string str;
for(j=0;j<v.size();j++)
{
if(j!=i)
str+=v[j]+" ";
}
str=str.substr(0,str.size()-1);
vector<string>::iterator it=find(f.begin(),f.end(),str);
if(it==f.end())
flag=false;
}
return flag;
}
int calculateSupportCount(vector<string> v) //計算支持度計數
{
int i,j;
int count=0;
for(i=0;i<T.size();i++)
{
vector<string> t=split(T[i],' ');
for(j=0;j<v.size();j++)
{
vector<string>::iterator it=find(t.begin(),t.end(),v[j]);
if(it==t.end())
break;
}
if(j==v.size())
count++;
}
return count;
}
bool judgeSupport(vector<string> v) //判斷一個項集的支持度是否滿足要求
{
int count=calculateSupportCount(v);
if(count >= ceil(minSup*T.size()))
return true;
return false;
}
void generateKFrequenceSet() //生成k-頻繁項目集
{
int k;
for(k=2;k<=mp.size();k++)
{
if(F.size()< k) //如果Fk-1為空��,則退出
break;
else //根據Fk-1生成Ck候選項集
{
int i,j;
vector<string> c;
vector<string> f=F[k-1];
for(i=0;i<f.size()-1;i++)
{
vector<string> v1=split(f[i],' ');
for(j=i+1;j<f.size();j++)
{
vector<string> v2=split(f[j],' ');
if(judgeItem(v1,v2)) //如果v1和v2只有最后一項不同�����,則進行連接
{
vector<string> tempVector=v1;
tempVector.push_back(v2[v2.size()-1]);
sort(tempVector.begin(),tempVector.end()); //對元素排序�����,方便判斷是否進行連接
//剪枝的過程
//判斷 v1的(k-1)的子集是否都在Fk-1中以及是否滿足最低支持度
if(judgeSubset(tempVector,f)&&judgeSupport(tempVector))
{
int p;
string tempStr;
for(p=0;p<tempVector.size()-1;p++)
tempStr+=tempVector[p]+" ";
tempStr+=tempVector[p];
c.push_back(tempStr);
}
}
}
}
if(c.size()!=0)
F.push_back(c);
}
}
}
vector<string> removeItemFromSet(vector<string> v1,vector<string> v2) //從v1中剔除v2
{
int i;
vector<string> result=v1;
for(i=0;i<v2.size();i++)
{
vector<string>::iterator it= find(result.begin(),result.end(),v2[i]);
if(it!=result.end())
result.erase(it);
}
return result;
}
string getStr(vector<string> v1,vector<string> v2) //根據前件和后件得到規則
{
int i;
string rStr;
for(i=0;i<v1.size();i++)
rStr+=v1[i]+" ";
rStr=rStr.substr(0,rStr.size()-1);
rStr+="->";
for(i=0;i<v2.size();i++)
rStr+=v2[i]+" ";
rStr=rStr.substr(0,rStr.size()-1);
return rStr;
}
void ap_generateRules(string fs)
{
int i,j,k;
vector<string> v=split(fs,' ');
vector<string> h;
vector< vector<string> > H; //存放所有的后件
int fCount=calculateSupportCount(v); //f的支持度計數
for(i=0;i<v.size();i++) //先生成1-后件關聯規則
{
vector<string> temp=v;
temp.erase(temp.begin()+i);
int aCount=calculateSupportCount(temp);
if( fCount >= ceil(aCount*minConf)) //如果滿足置信度要求
{
h.push_back(v[i]);
string tempStr;
for(j=0;j<v.size();j++)
{
if(j!=i)
tempStr+=v[j]+" ";
}
tempStr=tempStr.substr(0,tempStr.size()-1);
tempStr+="->"+v[i];
R.push_back((tempStr));
}
}
H.push_back(v);
if(h.size()!=0)
H.push_back(h);
for(k=2;k<v.size();k++) //生成k-后件關聯規則
{
h=H[k-1];
vector<string> addH;
for(i=0;i<h.size()-1;i++)
{
vector<string> v1=split(h[i],' ');
for(j=i+1;j<h.size();j++)
{
vector<string> v2=split(h[j],' ');
if(judgeItem(v1,v2))
{
vector<string> tempVector=v1;
tempVector.push_back(v2[v2.size()-1]); //得到后件集合
sort(tempVector.begin(),tempVector.end());
vector<string> filterV=removeItemFromSet(v,tempVector); //得到前件集合
int aCount=calculateSupportCount(filterV); //計算前件支持度計數
if(fCount >= ceil(aCount*minConf)) //如果滿足置信度要求
{
string rStr=getStr(filterV,tempVector); //根據前件和后件得到規則
string hStr;
for(int s=0;s<tempVector.size();s++)
hStr+=tempVector[s]+" ";
hStr=hStr.substr(0,hStr.size()-1);
addH.push_back(hStr); //得到一個新的后件集合
R.push_back(rStr);
}
}
}
}
if(addH.size()!=0) //將所有的k-后件集合加入到H中
H.push_back(addH);
}
}
void generateRules() //生成關聯規則
{
int i,j,k;
for(k=2;k<F.size();k++)
{
vector<string> f=F[k];
for(i=0;i<f.size();i++)
{
string str=f[i];
ap_generateRules(str);
}
}
}
void outputFrequenceSet() //輸出頻繁項目集
{
int i,k;
if(F.size()==1)
{
cout<<"無頻繁項目集!"<<endl;
return;
}
for(k=1;k<F.size();k++)
{
cout<<k<<"-頻繁項目集:"<<endl;
vector<string> f=F[k];
for(i=0;i<f.size();i++)
cout<<f[i]<<endl;
}
}
void outputRules() //輸出關聯規則
{
int i;
cout<<"關聯規則:"<<endl;
for(i=0;i<R.size();i++)
{
cout<<R[i]<<endl;
}
}
void Apriori()
{
initTransactionSet();
genarateOneFrequenceSet();
generateKFrequenceSet();
outputFrequenceSet();
generateRules();
outputRules();
}
int main(int argc, char *argv[])
{
Apriori();
return 0;
}
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
