前面小編給大家簡單介紹過損失函數���,今天給大家繼續分享交叉熵損失函數����,直接來看干貨吧����。
一�、交叉熵損失函數概念
交叉熵損失函數CrossEntropy Loss����,是分類問題中經常使用的一種損失函數����。公式為:

接下來了解一下交叉熵:交叉熵Cross Entropy����,是Shannon信息論中一個重要概念���,主要用于度量兩個概率分布間的差異性信息���。在信息論中�,交叉熵是表示兩個概率分布p,q����,其中p表示真實分布��,q表示非真實分布�����,在相同的一組事件中�,其中��,用非真實分布q來表示某個事件發生所需要的平均比特數���。
交叉熵的計算方式如下:

交叉熵可在機器學習中作為損失函數�,p代表真實標記的分布�,q則代表訓練后的模型的預測標記分布�,交叉熵損失函數可以衡量p與q的相似性����。交叉熵作為損失函數還有一個好處是:使用sigmoid函數在梯度下降時�,可以避免均方誤差損失函數學習速率下降的問題�,這是因為學習速率是能夠被輸出的誤差所控制的���。
二�、交叉熵損失函原理
一般我們學習交叉熵損失函數是在二元分類情況下���,就比如邏輯回歸「Logistic Regression」�、神經網絡「Neural Network」等����,其真實樣本的標簽為 [0.1]���,分別表示負類和正類����。模型的最后通常會經過一個 Sigmoid 函數�,輸出一個概率值�����,這個概率值反映了預測為正類的可能性:概率越大����,可能性越大�����。
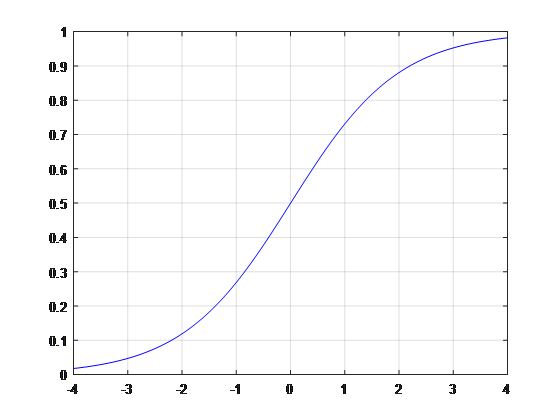
其中s是模型上一層的輸出���,sigmoid函數有這樣的特點:s = 0 時�,g(s) = 0.5; s >> 0 時����,g ≈ 1.s << 0 時��,g ≈ 0.顯然��,g(s) 將前一級的線性輸出映射到[0. 1]之間的數值概率上��,這里g(s)就是交叉熵公式中的模型預測輸出����。
預測輸出也就是����, Sigmoid 函數的輸出���,表示當前樣本標簽為 1 的概率:
y^=P(y=1|x)
那么��,當前樣本標簽為 0 的概率就可以表示為:
1?y^=P(y=0|x)
從極大似然性的角度考慮����,將上面兩種情況進行整合:
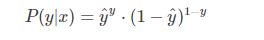
也就是:
當真實樣本標簽 y = 0 時���,上面式子第一項就為 1.概率等式轉化為:
P(y=0|x)=1?y^
當真實樣本標簽 y = 1 時�,上面式子第二項就為 1.概率等式轉化為:
P(y=1|x)=y^
這兩種情況下的概率表達式跟原來的完全相同�����,只是將兩種情況進行了整合���。
接下來我們重點看一下整合之后的概率表達式��,概率 P(y|x) 越大越好��。因為 log 運算并不會影響函數本身的單調性�����,所以 將log 函數引入P(y|x)�����。于是就有:
log P(y|x)=log(y^y?(1?y^)1?y)=ylog y^+(1?y)log(1?y^)
log P(y|x) 越大越好���,反過來說也就是����,只需要 log P(y|x) 的負值 -log P(y|x) 越小就可以了���。引入損失函數��,而且使得 Loss = -log P(y|x)即可�。那么就能得到損失函數為:
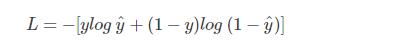
如果是計算N個樣本的總損失函數的情況��,則只需要將N個Loss疊加起來
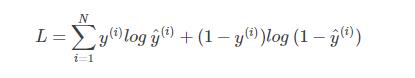
三�、交叉熵損失函數的優缺點分析
1.使用邏輯函數得到概率�,并結合交叉熵當損失函數時�,當模型效果差的時����,學習速度較快�,模型效果好時��,學習速度會變慢�����。
2.采用了類間競爭機制����,比較擅長于學習類間的信息��,但是只關心對于正確標簽預測概率的準確性�,而忽略了其他非正確標簽的差異���,從而導致學習到的特征比較散����。
以上就是小編今天跟大家分享的關于交叉熵損失函數概念和原理的相關介紹�����,希望對于大家有所幫助�。
相信讀完上文�����,你對算法已經有了全面認識�����。若想進一步探索機器學習的前沿知識��,強烈推薦機器學習之半監督學習課程����。

學習入口:https://edu.cda.cn/goods/show/3826?targetId=6730&preview=0
涵蓋核心算法�,結合多領域實戰案例���,還會持續更新����,無論是新手入門還是高手進階都很合適����。趕緊點擊鏈接開啟學習吧��!
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
