把近朱者赤����,近墨者黑這一思想運用到機器學習中會產生什么?當然是KNN最鄰近算法啦!KNN(全稱K-Nearest Neighbor)最鄰近分類算法是數據挖掘分類算法中最簡單的算法之一��,白話解釋一下就是:由你的鄰居來推斷出你的類別����。那么KNN算法的原理是什么�����,如何實現?一起與小編來看下面的內容吧�。
一�、KNN最鄰近算法概念
KNN最鄰近算法�����,是著名的模式識別統計學方法之一���,在機器學習分類算法中占有很高的地位�����。KNN最鄰近算法在理論上比較成熟�,不僅是最簡單的機器學習算法之一��,而且也是基于實例的學習方法中最基本的��,最好的文本分類算法之一�����。
KNN最鄰近算法基本做法是:給定測試實例�����,基于某種距離度量找出訓練集中與其最靠近的k個實例點����,然后基于這k個最近鄰的信息來進行預測�。
KNN最鄰近算法不具有顯式的學習過程��,事實上��,它是懶惰學習(lazy learning)的著名代表��,此類學習技術在訓練階段僅僅是把樣本保存起來�����,訓練時間開銷為零�,待收到測試樣本后再進行處理����。

二����、KNN最鄰近算法三要素
KNN最鄰近算法三要素為:距離度量�、k值的選擇及分類決策規則����。根據選擇的距離度量(如曼哈頓距離或歐氏距離)��,可計算測試實例與訓練集中的每個實例點的距離��,根據k值選擇k個最近鄰點���,最后根據分類決策規則將測試實例分類���。
1.距離度量
特征空間中的兩個實例點的距離是兩個實例點相似程度的反映�����。K近鄰法的特征空間一般是n維實數向量空間Rn�����。使用的距離是歐氏距離��,但也可以是其他距離����,如更一般的Lp距離或Minkowski距離�����。
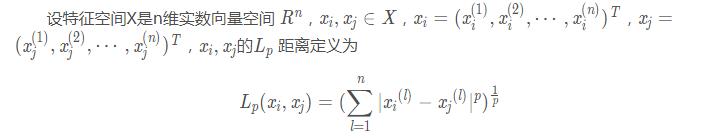
這里p≥1.
當p=1時��,稱為曼哈頓距離(Manhattan distance)���,即
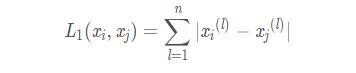
當p=2時����,稱為歐氏距離(Euclidean distance)�,即
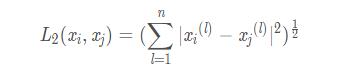

2.k值的選擇
k值的選擇會對KNN最鄰近算法的結果產生重大影響��。在應用中�����,k值一般取一個比較小的數值�����,通常采用交叉驗證法來選取最優的k值���。
3.分類決策規則
KNN最鄰近算法中的分類決策規則通常是多數表決��,即由輸入實例的k個鄰近的訓練實例中的多數類�����,決定輸入實例的類�����。
三���、KNN最鄰近算法優缺點
1.優點
①簡單�����,易于理解�,易于實現��,無需參數估計�,無需訓練;
②精度高��,對異常值不敏感(個別噪音數據對結果的影響不是很大);
③適合對稀有事件進行分類;
④特別適合于多分類問題(multi-modal,對象具有多個類別標簽)����,KNN要比SVM表現要好.
2.缺點
①對測試樣本分類時的計算量大��,空間開銷大����,因為對每一個待分類的文本都要計算它到全體已知樣本的距離�,才能求得它的K個最近鄰點�。目前常用的解決方法是事先對已知樣本點進行剪輯��,事先去除對分類作用不大的樣本;
②可解釋性差�����,無法給出決策樹那樣的規則;
③最大的缺點是當樣本不平衡時���,如一個類的樣本容量很大���,而其他類樣本容量很小時��,有可能導致當輸入一個新樣本時�,該樣本的K個鄰居中大容量類的樣本占多數�����。該算法只計算“最近的”鄰居樣本�,某一類的樣本數量很大�,那么或者這類樣本并不接近目標樣本���,或者這類樣本很靠近目標樣本�。無論怎樣���,數量并不能影響運行結果��??梢圆捎脵嘀档姆椒?和該樣本距離小的鄰居權值大)來改進;
④消極學習方法����。
四�、KNN算法實現
主要有以下三個步驟:
1. 算距離:給定待分類樣本��,計算它與已分類樣本中的每個樣本的距離;
2. 找鄰居:圈定與待分類樣本距離最近的K個已分類樣本�,作為待分類樣本的近鄰;
3. 做分類:根據這K個近鄰中的大部分樣本所屬的類別來決定待分類樣本該屬于哪個分類;
python示例
import math
import csv
import operator
import random
import numpy as np
from sklearn.datasets import make_blobs
#Python version 3.6.5
# 生成樣本數據集 samples(樣本數量) features(特征向量的維度) centers(類別個數)
def createDataSet(samples=100, features=2, centers=2):
return make_blobs(n_samples=samples, n_features=features, centers=centers, cluster_std=1.0, random_state=8)
# 加載鳶尾花卉數據集 filename(數據集文件存放路徑)
def loadIrisDataset(filename):
with open(filename, 'rt') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
return dataset
# 拆分數據集 dataset(要拆分的數據集) split(訓練集所占比例) trainingSet(訓練集) testSet(測試集)
def splitDataSet(dataSet, split, trainingSet=[], testSet=[]):
for x in range(len(dataSet)):
if random.random() <= split:
trainingSet.append(dataSet[x])
else:
testSet.append(dataSet[x])
# 計算歐氏距離
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow((instance1[x] - instance2[x]), 2)
return math.sqrt(distance)
# 選取距離最近的K個實例
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance) - 1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
# 獲取距離最近的K個實例中占比例較大的分類
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0]
# 計算準確率
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct / float(len(testSet))) * 100.0
def main():
# 使用自定義創建的數據集進行分類
# x,y = createDataSet(features=2)
# dataSet= np.c_[x,y]
# 使用鳶尾花卉數據集進行分類
dataSet = loadIrisDataset(r'C:\DevTolls\eclipse-pureh2b\python\DeepLearning\KNN\iris_dataset.txt')
print(dataSet)
trainingSet = []
testSet = []
splitDataSet(dataSet, 0.75, trainingSet, testSet)
print('Train set:' + repr(len(trainingSet)))
print('Test set:' + repr(len(testSet)))
predictions = []
k = 7
for x in range(len(testSet)):
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print('>predicted=' + repr(result) + ',actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: ' + repr(accuracy) + '%')
main()
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
