協同過濾推薦算法的原理及實現
協同過濾推薦算法是誕生最早���,并且較為著名的推薦算法�。主要的功能是預測和推薦�。算法通過對用戶歷史行為數據的挖掘發現用戶的偏好����,基于不同的偏好對用戶進行群組劃分并推薦品味相似的商品��。協同過濾推薦算法分為兩類����,分別是基于用戶的協同過濾算法(user-based collaboratIve filtering)����,和基于物品的協同過濾算法(item-based collaborative filtering)�。簡單的說就是:人以類聚�,物以群分��。下面我們將分別說明這兩類推薦算法的原理和實現方法�����。
1.基于用戶的協同過濾算法(user-based collaboratIve filtering)
基于用戶的協同過濾算法是通過用戶的歷史行為數據發現用戶對商品或內容的喜歡(如商品購買�,收藏����,內容評論或分享)���,并對這些喜好進行度量和打分�。根據不同用戶對相同商品或內容的態度和偏好程度計算用戶之間的關系�。在有相同喜好的用戶間進行商品推薦����。簡單的說就是如果A,B兩個用戶都購買了x,y,z三本圖書�,并且給出了5星的好評�����。那么A和B就屬于同一類用戶��?���?梢詫看過的圖書w也推薦給用戶B�����。

1.1尋找偏好相似的用戶
我們模擬了5個用戶對兩件商品的評分��,來說明如何通過用戶對不同商品的態度和偏好尋找相似的用戶�。在示例中���,5個用戶分別對兩件商品進行了評分����。這里的分值可能表示真實的購買���,也可以是用戶對商品不同行為的量化指標��。例如�����,瀏覽商品的次數�,向朋友推薦商品�����,收藏��,分享�����,或評論等等��。這些行為都可以表示用戶對商品的態度和偏好程度�����。
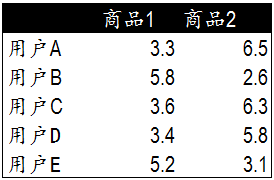
從表格中很難直觀發現5個用戶間的聯系����,我們將5個用戶對兩件商品的評分用散點圖表示出來后����,用戶間的關系就很容易發現了��。在散點圖中�,Y軸是商品1的評分���,X軸是商品2的評分���,通過用戶的分布情況可以發現��,A,C,D三個用戶距離較近�。用戶A(3.3 6.5)和用戶C(3.6 6.3)����,用戶D(3.4 5.8)對兩件商品的評分較為接近�����。而用戶E和用戶B則形成了另一個群體��。 散點圖雖然直觀�����,但無法投入實際的應用�,也不能準確的度量用戶間的關系���。因此我們需要通過數字對用戶的關系進行準確的度量���,并依據這些關系完成商品的推薦�。
散點圖雖然直觀�����,但無法投入實際的應用�,也不能準確的度量用戶間的關系���。因此我們需要通過數字對用戶的關系進行準確的度量���,并依據這些關系完成商品的推薦�。
1.2歐幾里德距離評價
歐幾里德距離評價是一個較為簡單的用戶關系評價方法��。原理是通過計算兩個用戶在散點圖中的距離來判斷不同的用戶是否有相同的偏好���。以下是歐幾里德距離評價的計算公式��。

通過公式我們獲得了5個用戶相互間的歐幾里德系數�,也就是用戶間的距離���。系數越小表示兩個用戶間的距離越近�,偏好也越是接近����。不過這里有個問題���,太小的數值可能無法準確的表現出不同用戶間距離的差異����,因此我們對求得的系數取倒數����,使用戶間的距離約接近����,數值越大����。在下面的表格中���,可以發現��,用戶A&C用戶A&D和用戶C&D距離較近�。同時用戶B&E的距離也較為接近�����。與我們前面在散點圖中看到的情況一致�。
1.3皮爾遜相關度評價
皮爾遜相關度評價是另一種計算用戶間關系的方法��。他比歐幾里德距離評價的計算要復雜一些�����,但對于評分數據不規范時皮爾遜相關度評價能夠給出更好的結果���。以下是一個多用戶對多個商品進行評分的示例��。這個示例比之前的兩個商品的情況要復雜一些��,但也更接近真實的情況���。我們通過皮爾遜相關度評價對用戶進行分組��,并推薦商品��。

1.4皮爾遜相關系數
皮爾遜相關系數的計算公式如下�����,結果是一個在-1與1之間的系數�。該系數用來說明兩個用戶間聯系的強弱程度��。

相關系數的分類
-
0.8-1.0 極強相關
-
0.6-0.8 強相關
-
0.4-0.6 中等程度相關
-
0.2-0.4 弱相關
-
0.0-0.2 極弱相關或無相關
通過計算5個用戶對5件商品的評分我們獲得了用戶間的相似度數據�。這里可以看到用戶A&B����,C&D��,C&E和D&E之間相似度較高�����。下一步���,我們可以依照相似度對用戶進行商品推薦�����。

2,為相似的用戶提供推薦物品
為用戶C推薦商品
當我們需要對用戶C推薦商品時����,首先我們檢查之前的相似度列表��,發現用戶C和用戶D和E的相似度較高�����。換句話說這三個用戶是一個群體�����,擁有相同的偏好��。因此�,我們可以對用戶C推薦D和E的商品�。但這里有一個問題����。我們不能直接推薦前面商品1-商品5的商品�����。因為這這些商品用戶C以及瀏覽或者購買過了���。不能重復推薦����。因此我們要推薦用戶C還沒有瀏覽或購買過的商品�。
加權排序推薦
我們提取了用戶D和用戶E評價過的另外5件商品A—商品F的商品��。并對不同商品的評分進行相似度加權�����。按加權后的結果對5件商品進行排序�����,然后推薦給用戶C��。這樣�,用戶C就獲得了與他偏好相似的用戶D和E評價的商品�。而在具體的推薦順序和展示上我們依照用戶D和用戶E與用戶C的相似度進行排序�����。
 以上是基于用戶的協同過濾算法��。這個算法依靠用戶的歷史行為數據來計算相關度���。也就是說必須要有一定的數據積累(冷啟動問題)����。對于新網站或數據量較少的網站�����,還有一種方法是基于物品的協同過濾算法���。
以上是基于用戶的協同過濾算法��。這個算法依靠用戶的歷史行為數據來計算相關度���。也就是說必須要有一定的數據積累(冷啟動問題)����。對于新網站或數據量較少的網站�����,還有一種方法是基于物品的協同過濾算法���。
基于物品的協同過濾算法(item-based collaborative filtering)
基于物品的協同過濾算法與基于用戶的協同過濾算法很像�����,將商品和用戶互換��。通過計算不同用戶對不同物品的評分獲得物品間的關系����?���;谖锲烽g的關系對用戶進行相似物品的推薦����。這里的評分代表用戶對商品的態度和偏好����。簡單來說就是如果用戶A同時購買了商品1和商品2���,那么說明商品1和商品2的相關度較高�����。當用戶B也購買了商品1時�����,可以推斷他也有購買商品2的需求�����。

1.尋找相似的物品
表格中是兩個用戶對5件商品的評分��。在這個表格中我們用戶和商品的位置進行了互換����,通過兩個用戶的評分來獲得5件商品之間的相似度情況�����。單從表格中我們依然很難發現其中的聯系��,因此我們選擇通過散點圖進行展示��。

在散點圖中���,X軸和Y軸分別是兩個用戶的評分�。5件商品按照所獲的評分值分布在散點圖中���。我們可以發現����,商品1,3,4在用戶A和B中有著近似的評分����,說明這三件商品的相關度較高��。而商品5和2則在另一個群體中�����。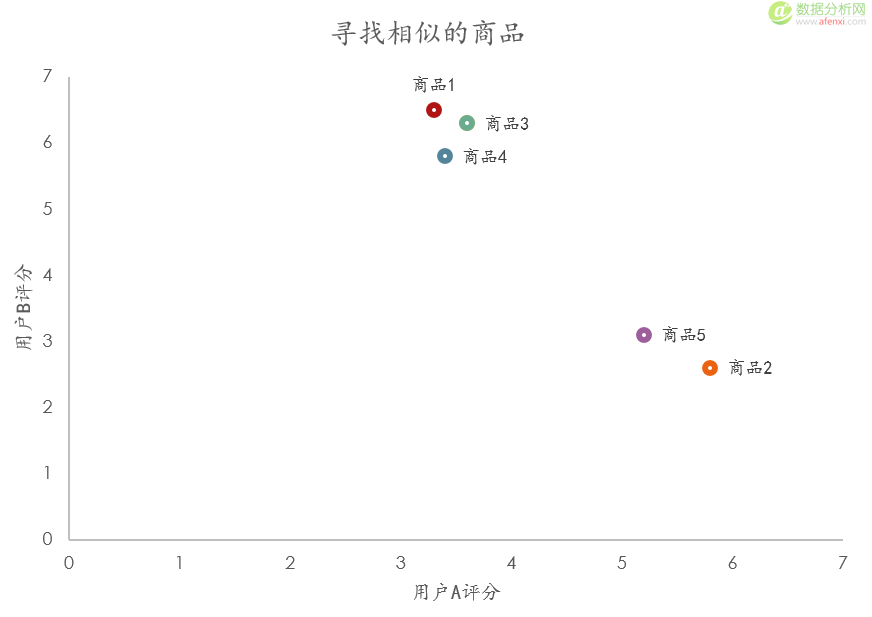 歐幾里德距離評價
歐幾里德距離評價
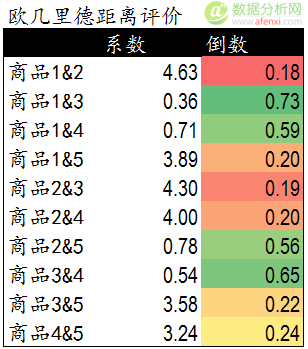
在基于物品的協同過濾算法中���,我們依然可以使用歐幾里德距離評價來計算不同商品間的距離和關系�����。以下是計算公式����。
通過歐幾里德系數可以發現�,商品間的距離和關系與前面散點圖中的表現一致���,商品1,3,4距離較近關系密切�����。商品2和商品5距離較近����。
皮爾遜相關度評價
我們選擇使用皮爾遜相關度評價來計算多用戶與多商品的關系計算���。下面是5個用戶對5件商品的評分表�。我們通過這些評分計算出商品間的相關度�。
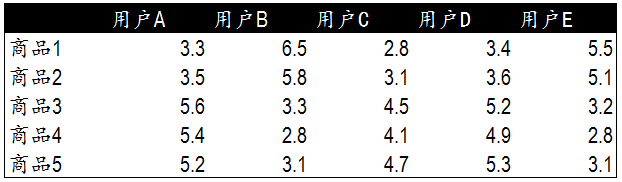
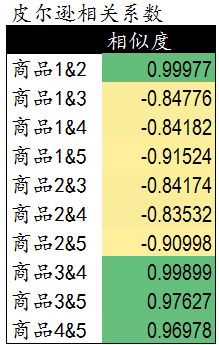
皮爾遜相關度計算公式通過計算可以發現�,商品1&2��,商品3&4�,商品3&5和商品4&5相似度較高��。下一步我們可以依據這些商品間的相關度對用戶進行商品推薦��。
2,為用戶提供基于相似物品的推薦
這里我們遇到了和基于用戶進行商品推薦相同的問題�����,當需要對用戶C基于商品3推薦商品時��,需要一張新的商品與已有商品間的相似度列表��。在前面的相似度計算中�,商品3與商品4和商品5相似度較高����,因此我們計算并獲得了商品4,5與其他商品的相似度列表��。
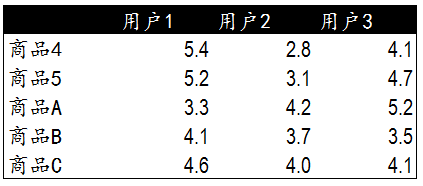
以下是通過計算獲得的新商品與已有商品間的相似度數據��。

加權排序推薦
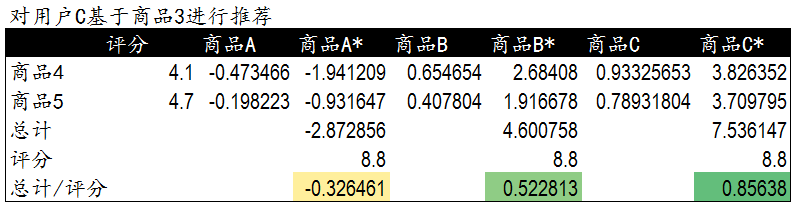
這里是用戶C已經購買過的商品4,5與新商品A,B,C直接的相似程度����。我們將用戶C對商品4,5的評分作為權重�����。對商品A,B,C進行加權排序��。用戶C評分較高并且與之相似度較高的商品被優先推薦�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
