支持向量機實例講解
簡介
掌握機器學習算法不再是天方夜譚的事情�����。大多數初學者都是從回歸模型學起��。雖然回歸模型簡單易學易上手���,但是它能解決我們的需求嗎�?當然不行��!因為除了回歸模型外我們還可以構建許多模型�����。
我們可以把機器學習算法看成包含劍��、鋒刃�、弓箭和匕首等武器的兵器庫����。你擁有各式各樣的工具��,但是你應該在恰當的時間點使用它們����。比如��,我們可以把回歸模型看做“劍”�����,它可以非常高效地處理切片數據����,但是它卻無法應對高度復雜的數據����。相反的是���,“支持向量機模型”就像一把尖刀���,它可以更好地對小數據集進行建模分析���。
到目前為止����,我希望你已經掌握了隨機森林����、樸素貝葉斯算法和集成建模方法�����。不然的話��,我建議你應該花一些時間來學習這些方法����。本文中����,我將會介紹另外一個重要的機器學習算法——支持向量機模型��。
目錄
-
什么是支持向量機模型���?
-
支持向量機模型運行原理
-
如何利用 Python 實現 SVM�?
-
如何調整 SVM 的參數�����?
-
SVM 的優缺點
什么是支持向量機模型��?
支持向量機(SVM)是一種有監督學習的算法����,它可以用來處理分類和回歸的問題�。然而���,實際應用中�����,SVM 主要用來處理分類問題����。在這個算法中����,首先我們將所有點畫在一個 n 維空間中(其中 n 代表特征個數)�。然后我們通過尋找較好區分兩類樣本的超平面來對數據進行分類處理(如下圖所示)�。
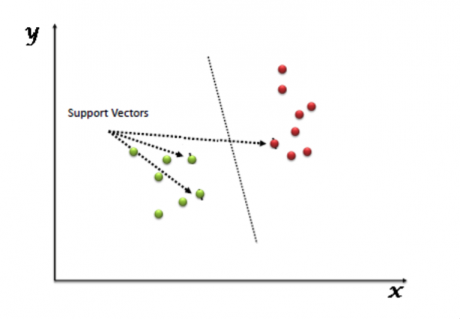
支持向量是觀測值的坐標�����,支持向量機是隔離兩個類別的最佳邊界(超平面)����。
你可以在這里看到關于支持向量的定義和一些實例�。
支持向量機的運行原理
首先���,我們已經熟悉了如何利用超平面來區分兩個類別的數據�。如今急需解決的問題是:“如何找出最佳的超平面�?”不要擔心�����,它沒有你所想的那么困難�!
讓我們來看幾個例子:
場景一:首先����,我們有三個超平面(A���、B 和 C)?�,F在我們需要的是找出區分星星和圓圈的最佳超平面�。
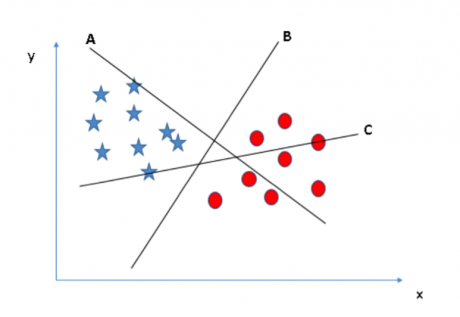
你需要記住一個識別最佳超平面的經驗法則:“選擇能更好區分兩個類別的超平面�����?!痹谶@個例子中�����,超平面“B”是最佳分割平面��。
場景二:首先我們有三個超平面(A���、B 和 C)���,它們都很好地區分兩個類別的數據�����。那么我們要如何選出最佳的超平面呢���?
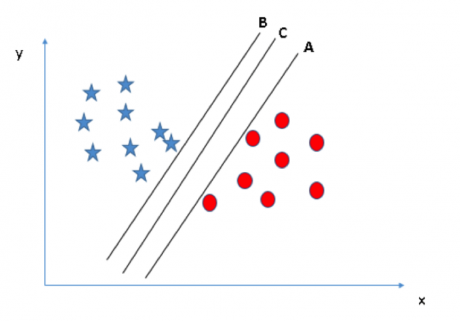
在這里���,我們可以通過最大化超平面和其最近的各個類別中數據點的距離來尋找最佳超平面�����。這個距離我們稱之為邊際距離�����。
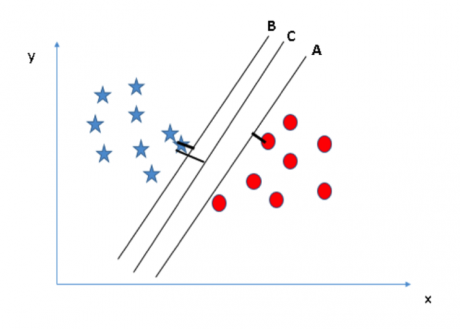
從上圖中你可以看到超平面 C 的邊際距離最大�。因此�����,我們稱 C 為最佳超平面�。選擇具有最大邊際距離的超平面的做法是穩健的�。如果我們選擇其他超平面��,將存在較高的錯分率���。
場景三:利用之前章節提到的規則來識別最佳超平面
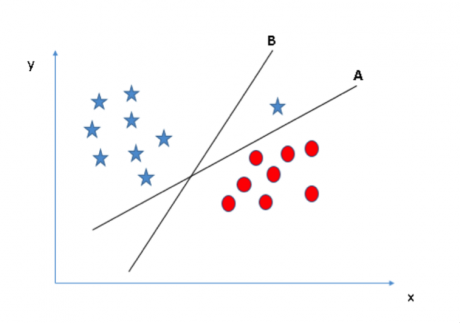
或許你們會選擇具有較大邊際距離的超平面 B���。但是你們錯了����,SVM 選擇超平面時更看重分類的準確度�����。在上圖中���,超平面 B 存在一個錯分點而超平面 A 的分類則全部正確����。因此��,最佳超平面是 A��。
場景四:由于存在異常值�����,我們無法通過一條直線將這兩類數據完全區分開來�����。

正如我之前提到的����,另一端的星星可以被視為異常值���。SVM 可以忽略異常值并尋找具有最大邊際距離的超平面����。因此�����,我們可以說 SVM 模型在處理異常值時具有魯棒性����。
場景五:在這個場景中����,我們無法通過線性超平面區分這兩類數據��,那么 SVM 是如何對這種數據進行分類的呢���?
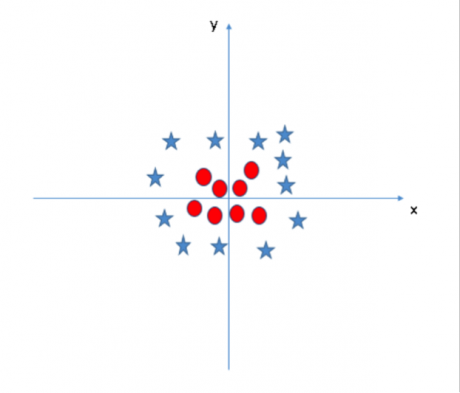
SVM 模型可以非常容易地解決這個問題���。通過引入新的變量信息��,我們可以很容易地搞定這個問題��。比如我們引入新的變量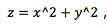 然后我們對 x 和 z 構建散點圖:
然后我們對 x 和 z 構建散點圖:
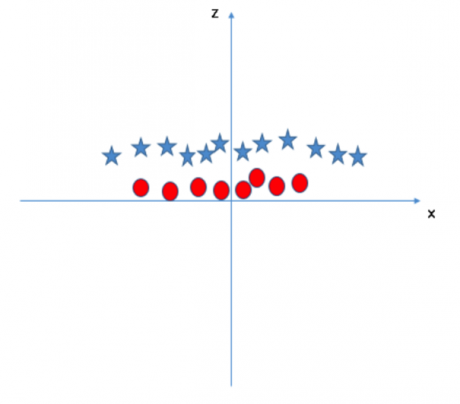
從上圖中我們可以看出:
由于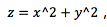 所以變量 z 恒大于零����。
所以變量 z 恒大于零����。
原始圖中�����,紅圈數據分布在原點附近��,它們的 z 值比較??���;而星星數據則遠離原點區域��,它們具有較大的 z 值�����。
在 SVM 模型中�����,我們可以很容易地找到分割兩類數據的線性超平面���。但是另外一個急需解決的問題是:我們應該手動增加變量信息從而獲得該線性超平面分割嗎���?答案是否定的����!SVM 模型有一個工具叫做 kernel trick��。該函數可以將輸入的低維空間信息轉化為高維空間信息�。在解決非線性分割問題時���,我們經常用到這個函數���。簡單地說����,該函數可以轉換一些極其復雜的數據��,然后根據自己所定義的標簽或輸出結果尋找區分數據的超平面����。
我們可以在原始圖中畫出最佳超平面:

接下來���,我們將學習如何將 SVM 模型應用到實際的數據科學案例中�。
如何利用 Python 實現 SVM 模型��?
在 Python 中�����,scikit-learn 是一個被廣泛使用的機器學習算法庫�����。我們可以通過 scikit-learn 庫來構建 SVM 模型�����。

如何調整 SVM 模型的參數�?
有效地調節機器學習算法的參數可以提高模型的表現力����。讓我們來看看 SVM 模型的可用參數列表:

接下來我將要討論 SVM 模型中一些比較重要的參數:“kernel”���,“gamma”和“C”�。
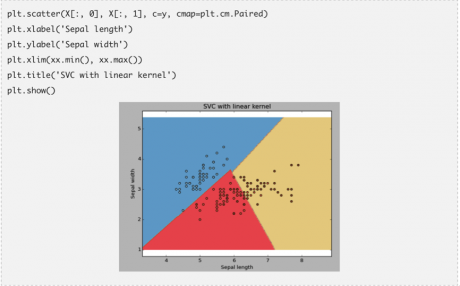
kernel:我們之前已經討論過這個問題����。Kernel參數中具有多個可選項:“linear”��,“rbf”和“poly”等(默認值是“rbf”)�����。其中 “rbf”和“poly”通常用于擬合非線性超平面��。下面是一個例子:我們利用線性核估計-對鳶尾花數據進行分類�。
例子:線性核估計

例子:rbf 核估計
我們可以通過下面的代碼調用 rbf 核估計����,并觀察其擬合結果�。
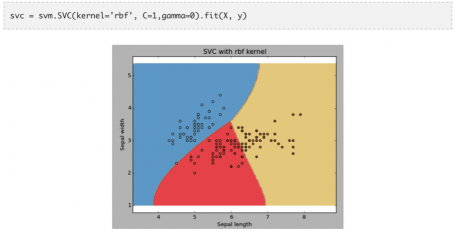
當變量個數比較大時(大于1000)���,我建議你最好使用線性核估計�,因為在高維空間中數據大多是線性可分的���。當然你也可以利用 rbf 核估計���,不過你必須使用交叉驗證調整參數從而避免過度擬合��。
“gamma”:“rbf”����,“poly”和“sigmoid”的核估計系數����。gamma的取值越大�,越容易出現過度擬合的問題�����。
例子:比較不同gamma取值下模型的擬合結果
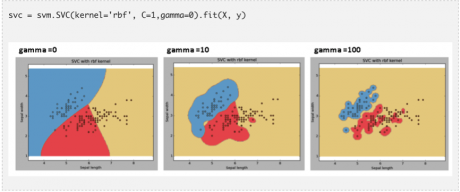
C:誤差項的懲罰參數�����。我們可以通過調節該參數達到平衡分割邊界的平滑程度和分類準確率的目的��。
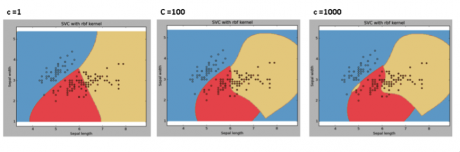
我們應該經常關注交叉驗證結果從而有效地利用這些參數的組合避免過度擬合情況的問題�����。
SVM 模型的優缺點
優點:
-
它的分類效果非常好����。
-
它可以有效地處理高維空間數據�����。
-
它可以有效地處理變量個數大于樣本個數的數據�����。
-
它只利用一部分子集來訓練模型����,所以 SVM 模型不需要太大的內存��。
-
-
缺點:
-
它無法很好地處理大規模數據集���,因為此時它需要較長的訓練時間����。
-
同時它也無法處理包含太多噪聲的數據集���。
-
SVM 模型并沒有直接提供概率估計值�����,而是利用比較耗時的五倍交叉驗證估計量����。
結語
在本文中��,我們詳細地介紹了機器學習算法——支持向量機模型���。我介紹了它的工作原理����,Python 的實現途徑��,使模型更有效參數調整技巧以及它的優缺點���。我建議你使用 SVM 模型并通過調整參數值分析該模型的解釋力�。同時我還想了解你們使用 SVM 的經驗��,你在建模過程有通過調整參數來規避過度擬合問題和減少建模訓練的時間嗎����?
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
