協同過濾是一種基于一組興趣相同的用戶或項目進行的推薦�����,它根據鄰居用戶(與目標用戶興趣相似的用戶)的偏好信息產生對目標用戶的推薦列表�����。協同過濾算法主要分為基于用戶的協同過濾算法和基于項目的協同過濾算法�����。
基于用戶的(User based)協同過濾算法是根據鄰居用戶的偏好信息產生對目標用戶的推薦����。它基于這樣一個假設:如果一些用戶對某一類項目的打分比較接近���,則他們對其它類項目的打分也比較接近�����。協同過濾推薦系統采用統計計算方式搜索目標用戶的相似用戶��,并根據相似用戶對項目的打分來預測目標用戶對指定項目的評分��,最后選擇相似度較高的前若干個相似用戶的評分作為推薦結果���,并反饋給用戶�。這種算法不僅計算簡單且精確度較高���,被現有的協同過濾推薦系統廣泛采用�。User-based協同過濾推薦算法的核心就是通過相似性度量方法計算出最近鄰居集合�,并將最近鄰的評分結果作為推薦預測結果返回給用戶�����。例如���,在下表所示的用戶一項目評分矩陣中�,行代表用戶�,列代表項目(電影)���,表中的數值代表用戶對某個項目的評價值?�,F在需要預測用戶Tom對電影《槍王之王》的評分(用戶Lucy對電影《阿凡達》的評分是缺失的數據)����。

由上表不難發現�����,Mary和Pete對電影的評分非常接近�����,Mary對《暮色3:月食》�、《唐山大地震》���、《阿凡達》的評分分別為3��、4����、4����,Tom的評分分別為3�����、5���、4���,他們之間的相似度最高�,因此Mary是Tom的最接近的鄰居��,Mary對《槍王之王》的評分結果對預測值的影響占據最大比例����。相比之下����,用戶John和Lucy不是Tom的最近鄰居����,因為他們對電影的評分存在很大差距�����,所以JohLn和Lucy對《槍王之王》的評分對預測值的影響相對小一些�。在真實的預測中����,推薦系統只對前若干個鄰居進行搜索�����,并根據這些鄰居的評分為目標用戶預測指定項目的評分��。由上面的例子不難知道��,User一based協同過濾推薦算法的主要工作內容是用戶相似性度量�、最近鄰居查詢和預測評分�����。
目前主要有三種度量用戶間相似性的方法����,分別是:余弦相似性����、相關相似性以及修正的余弦相似性��。
①余弦相似性(Cosine):用戶一項目評分矩陣可以看作是n維空間上的向量���,對于沒有評分的項目將評分值設為0�����,余弦相似性度量方法是通過計算向量間的余弦夾角來度量用戶間相似性的���。設向量i和j分別表示用戶i和用戶j在n維空間上的評分��,則用基于協同過濾的電子商務個性化推薦算法研究戶i和用戶j之間的相似性為:
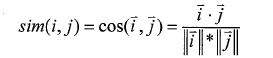
②修正的余弦相似性 (AdjustedCosine):余弦相似度未考慮到用戶評分尺度問題�����,如在評分區間[1一5]的情況下�,對用戶甲來說評分3以上就是自己喜歡的�,而對于用戶乙�,評分4以上才是自己喜歡的�。通過減去用戶對項的平均評分���,修正的余弦相似性度量方法改善了以上問題�。用幾表示用戶i和用戶j共同評分過的項集合��,Ii和壽分別表示用戶i和用戶j評分過的項集合�����,則用戶i和用戶j之間的相似性為:
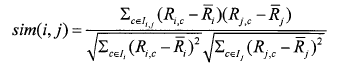
③相關相似性(Correlation)此方法是采用皮爾森(Pearson)相關系數來進行度量�。設Iij表示用戶i和用戶j共同評分過的項目集合�,則用戶i和用戶j之間相似性為:
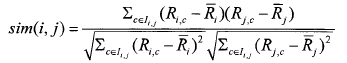
在得到目標用戶的最近鄰居以后��,接著就要產生相應的推薦結果��。設NNu為用戶u的最近鄰居集合���,則用戶u對項j的預測評分Puj計算公式如下:
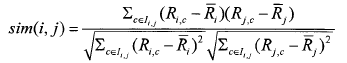
基于項目的(Item一based)協同過濾是根據用戶對相似項目的評分數據預測目標項目的評分����,它是建立在如下假設基礎上的:如果大部分用戶對某些項目的打分比較相近�����,則當前用戶對這些項的打分也會比較接近��。ltem一based協同過濾算法主要對目標用戶所評價的一組項目進行研究���,并計算這些項目與目標項目之間的相似性���,然后從選擇前K個最相似度最大的項目輸出�,這是區別于User-based協同過濾����。仍拿上所示的用戶一項目評分矩陣作為例子�����,還是預測用戶Tom對電影《槍王之王》的評分(用戶Lucy對電影《阿凡達》的評分是缺失的數據)�。
通過數據分析發現�����,電影《暮色3:月食》的評分與《槍王之王》評分非常相似�����,前三個用戶對《暮色3:月食》的評分分別為4�、3��、2�����,前三個用戶對《槍王之王》的評分分別為4�����、3��、3��,他們二者相似度最高��,因此電影《暮色3:月食》是電影《槍王之王》的最佳鄰居��,因此《暮色3:月食》對《槍王之王》的評分對預測值的影響占據最大比例��。而《唐山大地震》和《阿凡達》不是《槍王之王》的好鄰居���,因為用戶群體對它們的評分存在很大差距�����,所以電影《唐山大地震》和《阿凡達》對《槍王之王》的評分對預測值的影響相對小一些����。在真實的預測中����,推薦系統只對前若干個鄰居進行搜索��,并根據這些鄰居的評分為目標用戶預測指定項目的評分�����。
由上面的例子不難知道�,Item一based協同過濾推薦算法的主要工作內容是最近鄰居查詢和產生推薦��。因此���,Item一based協同過濾推薦算法可以分為最近鄰查詢和產生推薦兩個階段�。最近鄰查詢階段是要計算項目與項目之間的相似性����,搜索目標項目的最近鄰居;產生推薦階段是根據用戶對目標項目的最近鄰居的評分信息預測目標項目的評分����,最后產生前N個推薦信息�����。
ltem一based協同過濾算法的關鍵步驟仍然是計算項目之間的相似性并選出最相似的項目��,這一點與user一based協同過濾類似���。計算兩個項目i和j之間相似性的基本思想是首先將對兩個項目共同評分的用戶提取出來���,并將每個項目獲得的評分看作是n維用戶空間的向量���,再通過相似性度量公式計算兩者之間的相似性���。
分離出相似的項目之后����,下一步就要為目標項目預測評分���,通過計算用戶u對與項目i相似的項目集合的總評價分值來計算用戶u對項目i的預期��。這兩個階段的具體公式和操作步驟與基于用戶的協同過濾推薦算法類似�����,所以在此不再贅述���。
與基于內容的推薦算法相比�,協同過濾有下列優點:能夠過濾難以進行機器自動基于內容分析的信息����。如藝術品��、音樂;能夠基于一些復雜的���,難以表達的概念(信息質量��、品位)進行過濾;推薦的新穎性��。
然而����,協同過濾也存在著以下的缺點:用戶對商品的評價非常稀疏�,這樣基于用戶的評價所得到的用戶間的相似性可能不準確(即稀疏性問題)�����;隨著用戶和商品的增多�,系統的性能會越來越低(即可擴展性問題)��;如果從來沒有用戶對某一商品加以評價��,則這個商品就不可能被推薦(即最初評價問題)�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
