隨機森林(RF, RandomForest)介紹
隨機森林(RF, RandomForest)包含多個決策樹的分類器�,并且其輸出的類別是由個別樹輸出的類別的眾數而定����。通過自助法(boot-strap)重采樣技術��,不斷生成訓練樣本和測試樣本����,由訓練樣本生成多個分類樹組成的隨機森林���,測試數據的分類結果按分類樹投票多少形成的分數而定���。
隨機森林以隨機的方式建立一個森林�����,森林里有很多決策樹�����,且每棵樹之間無關聯����,當有一個新樣本進入后�����,讓森林中每棵決策樹分別各自獨立判斷�����,看這個樣本應該屬于哪一類(對于分類算法)��。然后看哪一類被選擇最多��,就選擇預測此樣本為那一類����。
→ 每個節點處隨機選擇特征進行分支�。
利用bootstrap重抽樣方法��,從原始樣本中抽出多個樣本�,對每個bootstrap樣本進行決策樹建模���。
主要思想是bagging并行算法����,用很多弱模型組合出一種強模型�。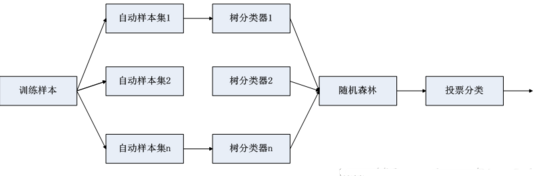
一�����、隨機決策樹的構造
建立每棵決策樹的過程中�����,有2點:采樣與完全分裂����。首先是兩個隨機采樣的過程�����,RF要對輸入數據進行一下行(樣本)��、列(特征)采樣���,對于行采樣(樣本)采用有放回的方式�,也就是在采樣得到的樣本中可以有重復�����。從M個特征中(列采樣)出m特征��。之后就是用完全分裂的方式建立出決策樹���。
一般決策樹會剪枝����,但這里采用隨機化���,就算不剪枝也不會出現“過擬合”現象����。
1.有N個樣本�����,則有放回地隨機選擇N個樣本(每次取1個���,放回抽樣)����。這選擇好了的N各樣本用來訓練一個決策樹���,作為決策樹根節點處的樣本�。
2.當每個樣本有M個屬性時����,在決策樹的每個節點需要分裂時�����,隨機從這M個屬性中選取出m個屬性��,滿足條件m<<M�。然后從這m個屬性中采用某種策略(如信息增益)來選擇一個屬性���,作為該節點的分裂屬性�。
3.決策樹形成過程中��,每個節點都要按照步驟2來分裂(很容易理解�����,如果下一次該節點選出來的那一個屬性是剛剛父節點分裂時用過的屬性��,則該節點已經達到了葉子節點���,無需繼續分裂)����。一直到不能再分裂為止���,注意整個決策樹形成過程中沒有剪枝�。
4.按步驟1-3建立大量決策樹��,如此形成RF�。
(從上面步驟可以看出����,RF的隨機性體現在每棵樹的訓練樣本是隨機的�����,樹中每個節點的分類屬性也是隨機選擇的�,有了這兩個隨機的保證�,RF就不會產生過擬合現象了)
隨機森林有2個重要參數:一是樹節點預選變量個數���,二是隨機森林中樹的個數(m的大?�。?/span>
RF中有2個要人為控制的參數:1.森林中樹的數量����,一般建議取很大�;2.m的大小����,推薦m的值為M的均方根��。
四�、RF性能及優缺點
優點:
1.很多的數據集上表現良好�;
2.能處理高維度數據��,并且不用做特征選擇���;
3.訓練完后�,能夠給出那些feature比較重要��;
4.訓練速度快��,容易并行化計算�。
缺點:
1.在噪音較大的分類或回歸問題上會出現過擬合現象�;
2.對于不同級別屬性的數據�����,級別劃分較多的屬性會對隨機森林有較大影響����,則RF在這種數據上產出的數值是不可信的�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
