面向高維度的機器學習的計算框架-Angel
為支持超大維度機器學習模型運算�����,騰訊數據平臺部與香港科技大學合作開發了面向機器學習的分布式計算框架——Angel 1.0��。
Angel是使用Java語言開發的專有機器學習計算系統�����,用戶可以像用Spark, MapReduce一樣���,用它來完成機器學習的模型訓練���。Angel已經支持了SGD��、ADMM優化算法��,同時我們也提供了一些常用的機器學習模型�;但是如果用戶有自定義需求���,也可以在我們提供的最優化算法上層比較容易地封裝模型���。
Angel應用香港科技大學的Chukonu 作為網絡解決方案�����, 在高維度機器學習的參數更新過程中���,有針對性地給滯后的計算任務的參數傳遞提速�����,整體上縮短機器學習算法的運算時間�。這一創新采用了香港科技大學陳凱教授及其研究小組開發的可感知上層應用(Application-aware)的網絡優化方案���,以及楊強教授領導的的大規模機器學習研究方案�。
另外��,北京大學崔斌教授及其學生也共同參與了Angel項目的研發�����。
在實際的生產任務中����,Angel在千萬級到億級的特征緯度條件下運行SGD��,性能是成熟的開源系統Spark的數倍到數十倍不等����。Angel已經在騰訊視頻推薦�����、廣點通等精準推薦業務上實際應用�����,目前我們正在擴大在騰訊內部的應用范圍�,目標是支持騰訊等企業級大規模機器學習任務�。
整體架構
Angel在整體架構上參考了谷歌的DistBelief���。DistBeilef最初是為深度學習而設計�����,它使用了參數服務器�,以解決巨大模型在訓練時的更新問題��。參數服務器同樣可用于機器學習中非深度學習的模型��,如SGD��、ADMM�、LBFGS的優化算法在面臨在每輪迭代上億個參數更新的場景中����,需要參數分布式緩存來拓展性能���。Angel在運算中支持BSP����、SSP��、ASP三種計算模型��,其中SSP是由卡耐基梅隆大學EricXing在Petuum項目中驗證的計算模型����,能在機器學習的這種特定運算場景下提升縮短收斂時間���。系統有五個角色:
Master:負責資源申請和分配���,以及任務的管理�����。
Task:負責任務的執行�����,以線程的形式存在���。
Worker:獨立進程運行于Yarn的Container中�����,是Task的執行容器����。
ParameterServer:隨著一個任務的啟動而生成���,任務結束而銷毀�����,負責在該任務訓練過程中的參數的更新和存儲�����。
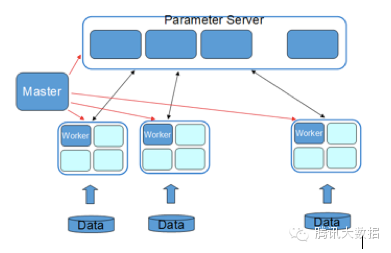
WorkerGroup為一個虛擬概念����,由若干個Worker組成����,元數據由Master維護��。為模型并行拓展而考慮����,在一個WorkerGroup內所有Worker運行的訓練數據都是一樣的���。雖然我們提供了一些通用模型�,但并不保證都滿足需求���,而用戶自定義的模型實現可以實現我們的通用接口�����,形式上等同于MapReduce或Spark��。
1)用戶友好
1. 自動化數據切分: Angel系統為用戶提供了自動切分訓練數據的功能�,方便用戶進行數據并行運算:系統默認兼容了Hadoop FS接口����,原始訓練樣本存儲在支持Hadoop FS接口的分布式文件系統如HDFS���、Tachyon����。
2. 豐富的數據管理:樣本數據存儲在分布式文件系統中���,系統在計算前從文件系統讀取到計算進程����,放在緩存在內存中以加速迭代運算�;如果內存中緩存不下的數據則暫存到本地磁盤�����,不需要向分布式文件系統再次發起通訊請求����。
3. 豐富的線性代數及優化算法庫: Angel更提供了高效的向量及矩陣運算庫(稀疏/稠密)����,方便了用戶自由選擇數據�、參數的表達形式�。在優化算法方面����,Angel已實現了SGD�、ADMM���;模型方面���,支持了Latent DirichletAllocation (LDA)����、MatrixFactorization (MF)�、LogisticRegression (LR) �、Support Vector Machine(SVM) 等�����。
4. 可選擇的計算模型:綜述中我們提到了����,Angel的參數服務器可以支持BSP�,SSP��,ASP計算模型��。
5. 更細粒度的容錯:在系統中容錯主要分為Master的容錯�,參數服務器的容災�����,Worker進程內的參數快照的緩存����,RPC調用的容錯���。
6. 友好的任務運行及監控: Angel也具有友好的任務運行方式���,支持基于Yarn的任務運行模式���。同時��,Angel的Web App頁面也方便了用戶查看集群進度��。
2)參數服務器
在實際的生產環境中����,可以直觀的感受到Spark的Driver單點更新參數和廣播的瓶頸�,雖然可以通過線性拓展來減少計算時的耗時��,但是帶來了收斂性下降的問題�,同時更嚴重的是在數據并行的運算過程中��,由于每個Executor都保持一個完整的參數快照����,線性拓展帶來了N x 參數快照的流量��,而這個流量集中到了Driver一個節點上��!

從圖中看到����,在機器學習任務中�����,Spark即使有更多的機器資源也無法利用�����,機器只在特定較少的規模下才能發揮最佳性能���,但是這個最佳性能其實也并不理想�。
采用參數服務器方案�,我們與Spark做了如下比較:在有5000萬條訓練樣本的數據集上����,采用SGD解的邏輯回歸模型����,使用10個工作節點(Worker)����,針對不同維度的特征逐一進行了每輪迭代時間和整體收斂時間的比較(這里Angel使用的是BSP模式)�����。

通過數據可見�,模型越大Angel對比Spark的優勢就越明顯����。
3)內存優化
在運算過程中為減少內存消耗和提升單進程內運算收斂性使用了異步無鎖的Hogwild! 模式�����。同一個運算進程中的N個Task如果在運算中都各自保持一個獨立的參數快照���,對參數的內存開銷就N倍�,模型維度越大時消耗越明顯����!SGD的優化算法中��,實際場景中�����,訓練數據絕大多數情況下是稀疏的�����,因此參數更新沖突的概率就大大降低了�,即便沖突了梯度也不完全是往差的方向發展����,畢竟都是朝著梯度下降的方向更新的�。我們使用了Hogwild!模式之后�����,讓多個Task在一個進程內共享同一個參數快照�,減少內存消耗并提升了收斂速度�����。
4)網絡優化
我們有兩個主要優化點:
1)進程內的Task運算之后的參數更新合并之后平滑的推送到參數服務器更新�,這減少了Task所在機器的上行消耗����,也減少了參數服務器的下行消耗����,同時減少在推送更新的過程中的峰值瓶頸次數���;
2)針對SSP進行更深一步的網絡優化:由于SSP是一種半同步的運算協調機制�����,在有限的窗口運行訓練����,快的節點達到窗口邊緣時��,任務就必須停下來等待最慢的節點更新最新的參數�。針對這一問題���,我們通過網絡流量的再分配來加速較慢的工作節點�����。我們給較慢的節點以更高的帶寬��;相應的�����,快的工作節點就分得更少的帶寬����。這樣一來�����,快的節點和慢的節點的迭代次數的差距就得以控制��,減少了窗口被突破(發生等待)的概率�����,也就是減少了工作節點由于SSP窗口而空閑等待時間����。
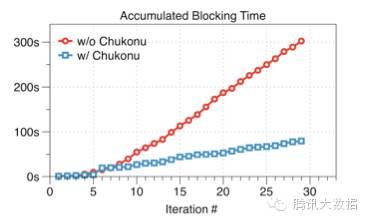
如下圖所示�,在1億維度�、迭代30輪的效果評測中����,可以看到Chukonu使得累積的空閑等待時間大幅度減少�,達3.79倍��。
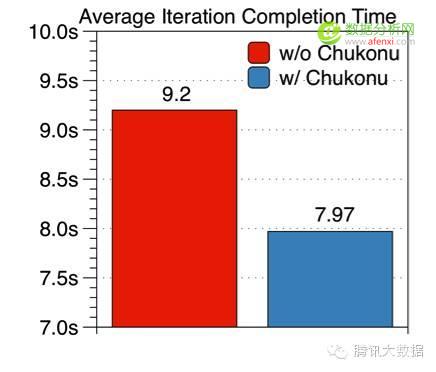
下圖展示的是優化前后的執行時間�����,以5000萬維度的模型為例���,20個工作節點和10個參數服務器����,Staleness=5�����,執行30輪迭代����?�?梢钥闯?,開啟Chukonu后平均每輪的完成時間只需7.97秒�����,相比于比原始的任務平均每輪9.2秒有了15%的提升����。
另外��,針對性加速慢的節點可以使慢的節點更大可能的獲得最新的參數��,因此對比原始的SSP計算模型���,算法收斂性得到了提升���。下圖所示���,同樣是針對五千萬維度的模型在SSP下的效果評測����,原生的Angel任務在30輪迭代后(276秒)loss達到了0.0697��,而開啟了Chukonu后��,在第19輪迭代(145秒)就已達到更低的loss���。從這種特定場景來看有一個接近90%的收斂速度提升�。

后續計劃
未來��,項目組將擴大應用的規模�����,同時���,項目組已經在繼續研發Angel的下一版本����,下一個版本會在模型并行方面做一些深入的優化�。另外���,項目組正在計劃把Angel進行開源�����,我們會在后續合適的時機進行公開����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
