控制在線問卷數據質量的具體方法
在對互聯網產品進行的用戶研究中,通過在線問卷收集數據是一個非常普遍的方式����。 在線問卷,不受訪問的環境限制,回收速度很快,具有明顯的優勢�����。但是由于被訪者沒有相關的指導,在設備存在差異,回答的態度有不同等,因此數據的質量能否得到保證, 是一個關鍵的問題���。數據質量決定了數據是否具有科學性,是否可以代表用戶,是否給出準確的研究結論����。因此我們要考慮對在線問卷的數據進行質量控制的具體的方法,保證問卷數據的質量�。
我們為什么會需要進行在線問卷數據的質量控制?
用戶在線回答問卷的過程中,會出現一些問題,總結起來有以下三類:
1���、會發生答題點擊失誤的情況
2����、會有理解錯誤導致錯誤回答的情況
3���、會出現答題不認真敷衍的情況
前兩種情況,屬于客觀必然發生的小概率事件,不易通過技術對數據進行質量控制,但是出現的可能性小,可以忽略���。而第三種情況,是用戶答題態度有偏差,是可以通過 技術實現質量控制,從而把有問題的數據發現并剔除掉�����。
如何發現有問題的問卷數據并剔除呢?
針對答題不認真的問卷數據,我們要怎么才能發現呢?可以通過以下三個層面�����。
1. 地雷題
我們第一種方法,也是最常用的方法,是通過在問卷中設置地雷題,并通過地雷題 的數據來檢驗問卷數據的準確性����。那么,什么是地雷題?
地雷題是問卷設計中驗證用戶回答態度認真與否而設計的題目�����。這類題目往往是 2 個,對應出現的����。也就是針對相同的問題以不明顯有差異的方式在問卷中提問兩次�����。如果被訪者回答對應出現的兩道題目,給出了完全相反或者差異巨大的答案,那么可以在 一定程度上反映,這個人回答問卷的態度不夠端正,可以懷疑這個人的數據是不真實的�。
例如:在某個問卷中,Q1 問題是:以下物品,請問您家擁有哪些?,其中有“汽車” 選項�����。Q10 問題是:請問您家擁有以下哪些個人資產?,其中也有“汽車”選項��。Q1 與 Q10 為地雷題,如果被訪者這兩個題目在汽車這個選項的答案出現差異,認為是不合格 的數據����。
地雷題應該如何設置?
地雷題是在問卷收集之前,就要設置好的,如果沒有設置,也就沒辦法通過其來進 行質控了����。同時需要注意,地雷題的設置也是有技巧的,針對選擇題,兩道地雷題之間 的距離應該盡可能大���。因為被訪者在回答問卷的時候,不一定記得清之前問題和選擇的 答案,如果地雷題之間相隔很多題目,用戶如果態度不端正,是很容易被甄別出來的����。
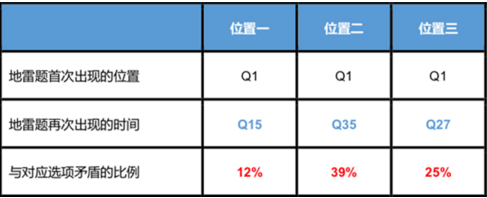
以下是一個實驗的數據結果�。實驗是將相同的地雷題,放在問卷的三個不同位置, 所甄別出的不合格問卷數據的比例���。我們發現,地雷題的相距越大,被訪者回答與對應 選項的矛盾比例越高�。
實驗數據一:設置在不同位置地雷題的效果
2. 答題時間
通過答題時間的長短,我們可以知道很多被訪者答題的情況:
(1)總體問卷回答時長
(2)單個問題回答時長
(3)總體問卷/單個問題的平均回答時長
(4)整體問卷/單個問卷的時長離散程度
……
通過以上這些時間數據,我們可以看到,一個被訪者在正常情況下,回答整個問卷或者單個問題,他需要的一個時間大概是多久��。如果回答問卷的平均需要15分鐘的時間,而有的人用了1分鐘就回答完了,而有的人用了2個小時,那么就很說明問題了, 回答時間過長或過短的被訪者回答問卷存在一定的問題���。
但是還有一種情況,就是如果平均時間是 15 分鐘,那么 3 分鐘的是否是認真的回 答,40 分鐘是否是不認真的回答呢?這個我們需要什么依據來判斷嗎?這就需要一個標準,稍后我們來揭曉這個標準��。
3. 題目選項個數
通過被訪者回答問卷的多選題,選擇的選項數量,也可以進行問卷數據的質量控制����。 如果一被訪者回答某個問題,所選擇的選項明顯多于或少于所有被訪者回答這個問卷的 平均選項數,那么就要注意了!
以下是一些問卷題目,被訪者的選擇的選項情況
實驗數據二:在線問卷的不同題目選項個數的平均值與最大值
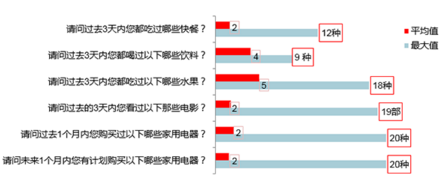
我們可以看到,對于吃飯,喝飲料,吃水果這種日常問題,被訪者選擇的選項個數明顯多于平均值或者不符合常理,就應被認為是不合理的����。比如圖中,吃水果的題目, 有的用戶選擇了三天內吃了 18 種水果,這樣的數據可能就有問題����。
3σ 原則數據檢驗標準
剛才我們講了答題時間,選項個數,可以反映被訪者答題的數據質量��。那么對于這兩個因素,有沒有一個標準可以來準確判斷,怎么樣的情況,我們就要剔除掉樣本數據呢?
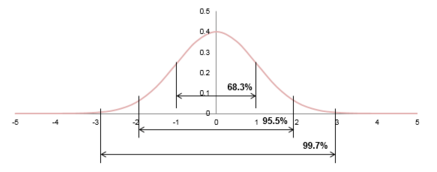
我們要引入一個概念��。即統計學原理的 3σ 原則�����。3σ 準則又稱為拉依達準則,它是先假設一組檢測數據只含有隨機誤差,對其進行計算處理得到標準偏差,按一定概率確 定一個區間,認為凡超過這個區間的誤差,就不屬于隨機誤差而是粗大誤差,含有該誤 差的數據應予以剔除���。這種判別處理原理及方法僅局限于對正態或近似正態分布的樣本 數據處理,它是以測量次數充分大為前提的����。在正態分布中 σ 代表標準差,μ 代表均值����。
3σ 原則為數值分布在(μ-σ,μ+σ)中的概率為 0.6826,數值分布在(μ-2σ,μ+2σ)中 的概率為 0.9544,數值分布在(μ-3σ,μ+3σ)中的概率為 0.9974,可以認為,Y 的取值幾乎全部集中在(μ-3σ,μ+3σ)區間內,超出這個范圍的可能性僅占不到 0.3%���。3σ 原則 告訴我們,標準正態分布時有 99.7%的可能數據應該落在 μ+3σ 的范圍內����。
選項個數在一定程度上是比較穩定的,即所有人選擇個數的均值是相對穩定的����?�?紤]到不同情況下大家行為的差異,我們需要關注所有人選擇個數的標準差來衡量其離散 程度���。由于在多選題中沒有負數出現,因而數據分布如下圖所示����。數據落在 μ+3σ 范圍內的概率均超過 99%,也就是說一個正常的數據有 99%的可能性會落在這個范圍內, 超過這個范圍的值發生的概率極小,因而一旦發生,可以認為是奇異值,需要剔除掉���。
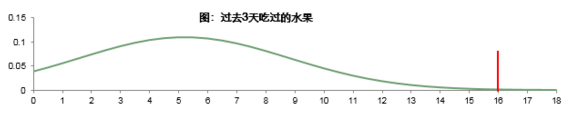
結合上圖舉例:如果 1000 人回答吃水果的題目,平均值是 4 個,標準差是 4,那么這道題目選項個數的合理范圍的最小值是 0(4-3*4=-8,水果個數不能為負數,取 0) 個,最大值是 16(4+3*4)個,超過 16 個的問卷數據應被視為無效,而無效的被訪者 不會超過 3 人�����。
同樣的方法,也可以驗證被訪者答題時間是否合理�����。
今天我們講了如何通過地不同的方式和方法,對在線問卷數據進行質量控制��。希望 今天的內容對大家在問卷數據處理有一定的幫助,未來我們會進一步完善相關方法,并 及時和大家探討!
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
