數據挖掘系列篇:聚類算法概述
本篇重點介紹聚類算法的原理����,應用流程��、使用技巧�、評估方法����、應用案例等�����。具體的算法細節可以多查閱相關的資料��。聚類的主要用途就是客戶分群�����。1.聚類 VS 分類
分類是“監督學習”��,事先知道有哪些類別可以分���。
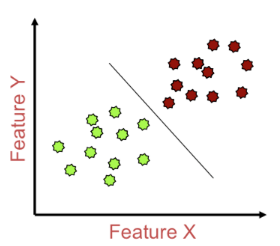
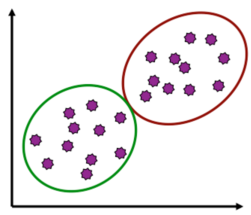
聚類是“無監督學習”����,事先不知道將要分成哪些類�。
舉個例子���,比如蘋果����、香蕉��、獼猴桃�����、手機���、電話機��。
根據特征的不同��,我們聚類會分為【蘋果�、香蕉���、獼猴桃】為水果的一類��,和【手機�、電話機】為數碼產品的一類�����。
而分類的話��,就是我們在判斷“草莓”的時候��,把它歸為“水果”一類�����。
所以通俗的解釋就是:分類是從訓練集學習對數據的判斷能力����,再去做未知數據的分類判斷�����;而聚類就是把相似的東西分為一類��,它不需要訓練數據進行學習���。
學術解釋:分類是指分析數據庫中的一組對象��,找出其共同屬性���。然后根據分類模型���,把它們劃分為不同的類別���。分類數據首先根據訓練數據建立分類模型���,然后根據這些分類描述分類數據庫中的測試數據或產生更恰當的描述�。
聚類是指數據庫中的數據可以劃分為一系列有意義的子集��,即類��。在同一類別中�����,個體之間的距離較小�����,而不同類別上的個體之間的距離偏大�����。聚類分析通常稱為“無監督學習”���。
2.聚類的常見應用
我們在實際情況的中的應用會有:
marketing:客戶分群
insurance:尋找汽車保險高索賠客戶群
urban planning:尋找相同類型的房產
比如你做買家分析��、賣家分析時����,一定會聽到客戶分群的概念���,用標準分為高價值客戶�、一般價值客戶和潛在用戶等�����,對于不同價值的客戶提供不同的營銷方案��;

還有像在保險公司����,那些高索賠的客戶是保險公司最care的問題�����,這個就是影響到保險公司的盈利問題���;
還有在做房產的時候����,根據房產的地理位置��、價格��、周邊設施等情況聚類熱房產區域和冷房產區域���。
3.k-means
(1)假定K個clusters(2)目標:尋找緊致的聚類
a.隨機初始化clusters
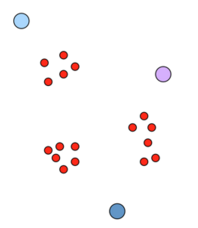
b.分配數據到最近的cluster
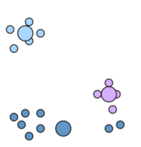
c.重復計算clusters
d.repeat直到收斂
優點:局部最優
缺點:對于非凸的cluster有問題
其中K=�����?
K<=sample size
取決于數據的分布和期望的resolution
AIC��,DIC
層次聚類避免了這個問題
4.評估聚類
魯棒性����?
聚類如何���,是否過度聚合�?
很多時候是取決于聚合后要干什么�。
5.case案例
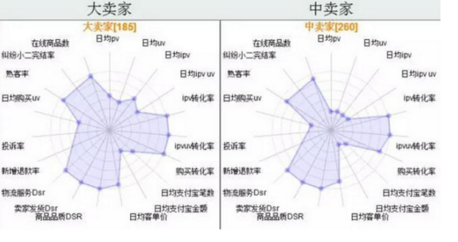
case 1:賣家分群云圖
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
