實現R與Hadoop聯合作業的三種方法
為了滿足用R語言處理pb量級數據的需求�,我們需要把它和Hadoop聯合起來使用��。本文的目的就是闡述實現二者聯合作業的不同技術�。
方法一:利用Streaming APIs
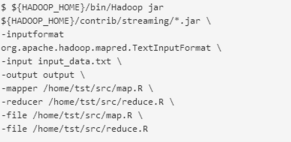
Hadoop支持一些 Streaming API來將R語言中的函數傳入��,并在MapReduce模式下運行這些函數���。這些Streaming API可以將任意能在map-reduce模式下訪問和操作標準I/O接口的R腳本傳入Hadoop中��。因此�����,你不需要額外開啟一些客戶端之類的東西�。如下是一個例子:
方法二:使用Rhipe包
Rhipe包允許用戶在R中使用MapReduce�。在使用這一方法前�����,要做相應的前期準備工作����。R需要被安裝在Hadoop集群中的每一個數據節點上�,此外每個節點還要安裝Protocol Buffers(更多資料請參考 http://wiki.apache.org/hadoop/ProtocolBuffers)�,Rhipe也需要在每個節點上都可以被使用����。
下面是在R中利用Rhipe應用MapReduce框架的范例:

方法三:使用RHadoop
RHadoop是Recolution Analytics下的一個開源庫��,與Rhipe類似�����,它的功能也是在MapReduce模式下執行R函數���。后續列舉的都是該庫中的一些包�����。plyrmr包可以在Hadoop中對大數據集進行一些常用的數據整理操作�。rmr包提供了一些讓R和Hadoop聯合作業的函數�。rdfs包提供了一些函數來連接R和分布式文件系統(HDFS)�。rhbase包中的函數則能連接R和HBase��。
下面這個例子中����,我們會演示如何使用rmr包中的一些函數來讓R與Hadoop聯合作業�。

方法總結
總的說來����,上述三種方法都能很容易地實現R與Hadoop的聯合作業���,這樣一來R就擁有了在分布式文件系統(HDFS)上處理大數據的能力����。但同時�,這三種方法也各有利弊�����。
關鍵結論:
1�、使用Streaming APIs最為簡單��,它的安裝和設置都很方便�。Rhipe和RHadoop都需要對R進行一些設置����,并且也需要Hadoop集群上一些包的支持����。但在執行函數方面�����,Streaming APIs 需要將函數依次map和reduce�,而Rhipe和RHadoop允許開發者在R函數中定義并調用MapReduce函數���。
2��、與Rhipe和RHadoop不同��,使用Streamings APIs也不需要客戶端���。
3�����、除此之外����,我們也可以使用Apache Mahout�����,Apache Hive�����,Segue框架與其他來自Revolution Analytics的商業版R來實現大規模機器學習����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
