談談樣本量選擇背后的科學道理
總是說XX的樣本量就夠了���,可是為什么呢��?
如何決定樣本量�,是一個老生常談的話題��,也有很多相關文章���。然而翻看相關文章����,就會發現介紹選多少合適的比較多���,而介紹為什么這么選就合適的卻比較少���。
相信很多用研同學都聽過這句著名的話:
根據尼爾森關于可用性測試的經典理論��,6-8人便可以找到產品80%以上的可用性問題���。
但是……為啥呢�?當有“無知的”地球人問:為什么6-8人就能發現80%以上的問題時����,難道我們要理直氣壯的說:因為是尼爾森說的么……
在樣本量選擇上似乎有一些“約定俗成”的規定�。比如:可用性測試5-8人����,問卷調研大約200-500份等等……但是�,當需要和地球人理論時��,單單的“約定俗成”卻沒有足夠的說服力����。不如讓我們一起來看看這些“約定俗成”背后的科學道理��,讓自己更有底氣�。
1. 為什么說可用性測試5-8個人就夠���?
俗話說“8個用戶可以發現80%的問題”���。其實這句話并不完整�����,完整的說法應該是:
8個人可以80%的概率發現發生可能性大于18%的問題���。
這話太繞了����,嘗試用人話解釋一下:如果某個APP中存在一個BUG�,100個人用���,50個人用都會遇到��,那么我們至少有80%的可能性發現�。只要可能遇到的人大于18個(發生可能性大于18%)�,我們都至少有80%的可能性發現�����。但如果這個BUG只有5個人可會遇到�,那么能發現的概率就要低于80%了��。
之所以這么說���,背后的原理是這樣一個公式:
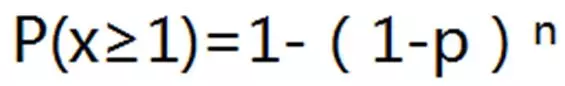
(P(X≥1)是在n次嘗試中事件至少發生1次的概率�,p是某事件的概率)
前輩們根據這個公式總結出了下表:
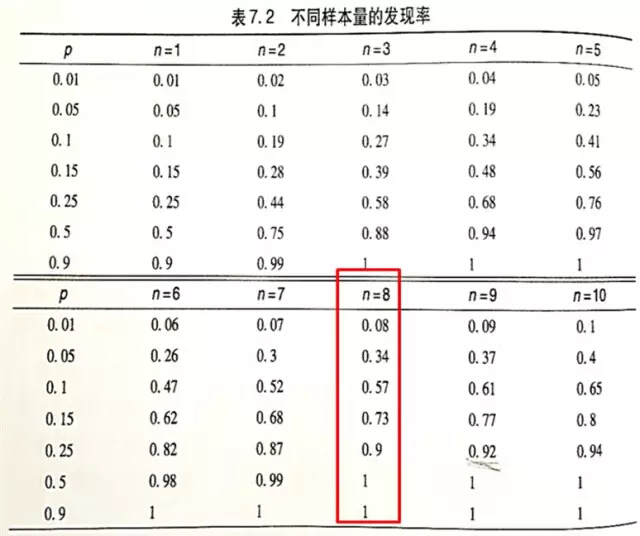
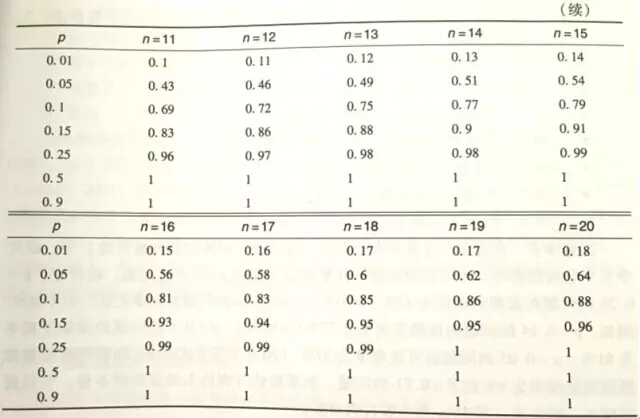
資料來源:《用戶體驗度量》Jeff Sauro�����,James R.Lewis著����,機械工業出版社����,P134-135
從表中可以看出�����,決定樣本量涉及到兩個因素:一個是確定程度�,一個是問題發生的概率��。
再來具體看一看我們常說的“8個人”�。
當選擇8個人進行測試時�����,可以100%發現發生概率大于50%的問題����,90%的可能性發現發生概率大于25%的問題���,73%的可能性發現發生概率大于15%的問題����。
就好像天氣預報員說:100%的確定明天的降水概率大于50%�����,90%的確定明天的降水概率大于25%����。
等等…這樣的話會不會被質疑:8個人只能90%發現發生概率大于25%的問題���,那發生概率低于25%的問題怎么辦��?就不重要了么�?
不如讓我們再來看看尼爾森關于釣魚的比喻:
假設你有好多個池塘可以釣魚���,一些魚比另一些魚更容易抓到�。所以��,如果你有10小時��,你會花10個小時都在一個池塘里釣魚����,還是花5個小時在一個池塘上�����、花另外的5個小時在另一個池塘上呢�����? 為使抓到的魚數量最大化����,你應該在兩個池塘上都花一些時間���,以便從每個池塘里都釣到容易釣的魚���。
一次何必找那么多用戶���,少做幾個用戶先把發生率高的問題get了�����,版本更新以后再繼續找用戶去get發生率高的問題��,省時省力效果佳���。
這樣是不是就可以完整的證明我們可用性測試做5-8個人的觀點了呢����。
2. 問卷調研�,樣本量選多少����?
在做問卷調研的時候�,如何估計樣本量����?眾所周知有一個公式:
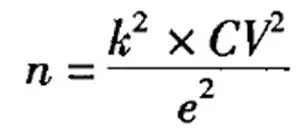
但是這個公式存在一個問題:我要是連總體方差(CV2)都能知道���,還做個毛線調研����。
如果想估算總體方差�,需要先選取一批人進行測試��,得到一個樣本方差���,用樣本方差代替總體方差����,這在現實工作中顯然難以實現�。于是為了便于計算����,偉大的前輩對公式進行了轉換:
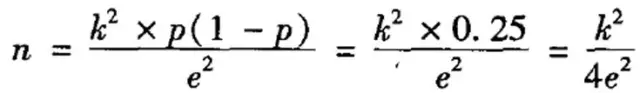
資料來源:《社會研究方法》仇立平著���,重慶大學出版社���,P137
作者說這一轉換是根據“推論總體比例或百分比的原理”進行的��。姑且不去管這個轉換原理是什么��,這個公式我們可以這樣來理解:當p=0.5的時候���,總體的差異性最大�。因為p=0.5表示兩種情況出現的概率是相等的�。比如一個群體中男生和女生出現的概率都是0.5�����,說明男女人數相等���。這種情況下�����,這個群體的性別差異是最大的�����。
由于總體差異越大�,需要的樣本量就越大����。我們面對任何總體的時候��,都可以假設“這是一個差異性最大的總體”��,來計算我們所需要的樣本量�����。因此����,把p=0.5代入����,就簡化出了一個可以供我們輕松計算樣本量的公式���。
如果想看到總體不同差異所對應的樣本量����,前人還總結了這樣一個表:
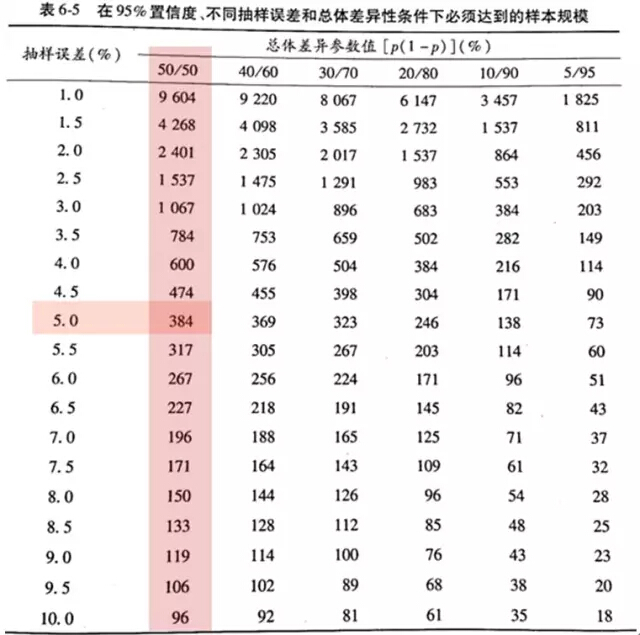
資料來源:《社會研究方法》仇立平著��,重慶大學出版社����,P137
因此假設總體差異性最大的情況下�����,在習慣使用的5%誤差檔��,300多的樣本也就可以了�。
當然���,在具體使用過程中��,并不用查表那么麻煩��。有一個著名的計算樣本量的網站�,直接去算就OK了���。
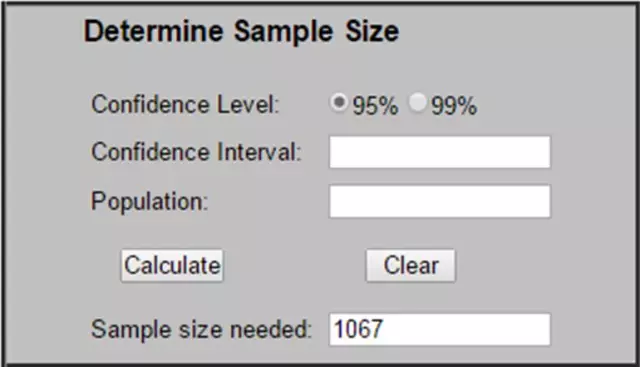
http://www.surveysystem.com/sscalc.htm
3.用戶量越大���,需調研人數越多���?
首先�,總體規模會對樣本量有影響�。當總體規模比較小的時候���,對樣本量影響較大�。但是當總體規模達到一定程度以后��,對樣本量增加的需求是較小的�。
我們往往調查所涉及到的總體不是無限總體��,產品的用戶人數都是一個有限的數量��。因此在計算所需樣本量的時候����,為了更精確可以加入變量“總體規?�!?����,公式大概長成這個樣子:
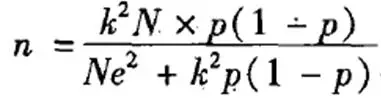
然而這不是重點��,重點是通過這個公式可以計算出�,不同總體規模所需要的樣本量大致如下:
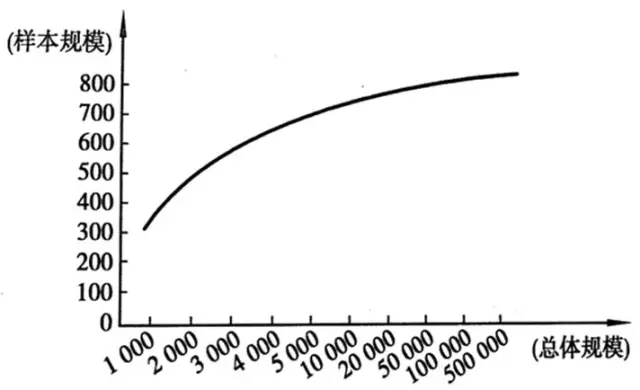
由此可以看出�����,當總體規模在1萬以下時��,隨著總體規模上升��,所需樣本量增加比較大�。但是當總體規模在1萬以上時��,規模再變大����,所需樣本人數的增長變得緩慢����。
為了得到更準確的答案�,我們不妨用計算樣本量的網址自己來算一下�����。假設置信區間為±3個標準差��。計算結果如下:
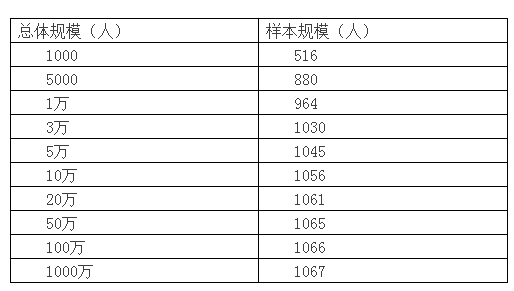
如果再有人說:我們是億級的產品�����,1000人怎么能代表我們的用戶�����?
就可以理直氣壯的告訴他:
總體規模10萬以上和10萬所需要的樣本量并沒有什么區別呢���。
樣本量選多少合適���,對于調研本身而言或許不是個問題����。但是當我們想推動調研結果的時候���,樣本量卻很容易遭到對方質疑�??赡苁菐装賯€人的答案看起來容易讓人覺得不靠譜����,也可能因為樣本量是最容易質疑的一個因素……
無論如何���,多了解一些背后的原因�����,讓自己更有底氣��,或許才能更好地說服別人�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
