通過數據解釋過去
數據的作用主要體現在兩方面:解釋過去和預測未來����。本篇文章介紹如何通過數據解釋過去發生的事情�����。包括過去發生了什么事情?這些事情有什么樣的規律?驅動因素是什么?是否有明顯的改進或提升?等等��。在開始之前我們先來介紹下數據的獲取來源以及數據的特點和分類����。
數據來源及分類
我們以網站的數據為例��,網站的數據來自于服務確日志和網站分析工具��。下面是來自網站分析工具Google Analytics的一條日志信息�����。在這條日志中包含了一些用戶及網站的信息���。Google通過對這些信息的處理產生數據��,并最終生成我們所看到的網站數據報告�。

我們將日志進行拆分展現����,以便更加清晰的看到日志中所包含的具體信息��??梢钥吹?�,每一條信息都是以一對參數和值的形式進行記錄的��。例如���,參數t表示這條日志的類型����,值pageview表示這是一條PV日志���。(Google Analytics中除了PV日志�����,還包括event日志等其他多種日志類別)說明每條這樣的日志都表示一次頁面瀏覽�。又如參數dl表示用戶當前瀏覽的頁面地址����,值表示頁面的具體URL����。
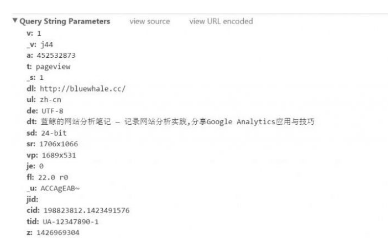
通過觀察日志中的信息可以發現���,日志中所包含的信息分為兩大類��,也就是參數后面的值類型��。一類是類別變量�����,這在Google Aanalytics中參數值類型為text或boolean�,例如客戶ID����,地理位置和屏幕分辨率等���。另一類是數值變量�,這在Google Analytics中參數值類別為integer或currency���,例如事件價值����,商品數量���,交易收入等�。詳細信息請參考《Measurement Protocol 參數參考》
類別型變量

數值型變量

在了解了Google Analytics日志中信息的分類后���,我們開始分布對每個類別信息的分析方法進行說明����。包括每一個類別信息的分析方法和它們所適合的圖表展現形式����。首先分布介紹類別型變量和數值型變量的分析方法�。
單因素分析
這里再啰嗦兩句���,很多時候我們面對數據無法獲得有用的結果或洞察�,原因不是因為缺少數據�,而是因為數據太多���。這里我們將信息進行拆分��,每次只針對一類信息進行介紹���,發現其中的規律及驅動因素���。避免迷失在大量無用的數據中�。
前面我們說過�����,Google Analytics日志收集到的信息分為兩類����,類別變量和數值變量��。下面我們分別來看下這兩類信息的分析方法�。
類別變量
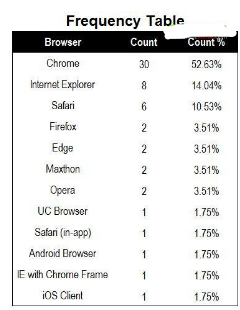
類別變量指日志中以文本或布爾值的形式記錄的信息����。這類信息本身不是數據�����,不能直接進行運算���。需要進行處理后才能轉化為我們常見的數據形式�。例如下面的瀏覽器信息���。每個用戶都會使用不同品類的瀏覽器�����。當用戶訪問網站時我們以文本形式記錄下了這些瀏覽器的品牌信息��。這類信息就屬于類別變量�。下面是一組瀏覽器的品牌信息列表�。

對于瀏覽器品牌這樣的類別變量����,我們會通過計算生成頻率和占比數據����。用來分析不同瀏覽器品牌的流行及重要程度�。下面是經計算獲得的不同瀏覽器品牌出現的次數以及在所有瀏覽器品牌中的占比情況���?�?梢园l現�����,Chrome在所有瀏覽器中出現次數最多���,為30次����。占比在所有瀏覽器中超過50%���。說明Chrome在樣本數據中是較為流行的瀏覽器品牌��。
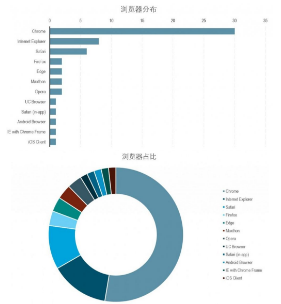
柱狀圖��,條形圖和餅圖或環形圖是對類別變量頻次和占比數據最好的展現形式�,下面我們分別使用的條形圖展示了不同瀏覽器品牌出現的頻率�����,使用環形圖展示了不同瀏覽器品牌的占比情況���。
數值變量
數值變量是指日志中以數值形式記錄的信息�����。這些信息可以直接作為數據����,或者通過相互間的運算生成新的數據�。例如下面的瀏覽深度是通過到訪網站次數和瀏覽頁面總次數計算獲得的����。

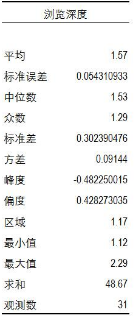
對于數值變量�,我們通常使用描述統計來觀察這組數據的集中程度和離散程度��。用來描述集中程度的指標有平均數�����,中位數和眾數����。描述離散程度的有方差和標準差����。通過描述統計提供的一系列指標�����,我們可以發現并描述數值的規律���。對于瀏覽深度數據�����,通過描述統計可以發現����,瀏覽深度集中在1.5個頁面左右��。標準差為0.3�,表示整體數據離散程度不高�。描述統計可以在Excel中數據菜單下的數據分析功能中找到����。
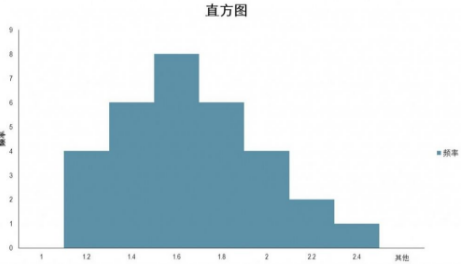
除了描述統計外��,第二個要分析的是數值的分布�����。其實前面的平均數���,標準差���,峰度和偏度幾個指標已經大體描繪出了變量分布的形態�����,但下面的直方圖更加直觀的展示了數據分布��。從直方圖中可以看到瀏覽深度數據符合正態分布���,概率最高的是1.5次����。換句話說�,瀏覽深度數據集中在1.5頁左右�,并且較為平穩�,變化不大�。瀏覽較多和較少頁面的都不多��。最少的頁面瀏覽深度為1.12頁��。最多的頁面瀏覽深度為2.29頁�。
雙變量分析
在前面的單因素分析中���,我們分別介紹了類別變量和數值變量的分析方法���,下面我們介紹雙變量的分析方法�。雙變量分析簡單來說就是單因素的組合�����。我們把雙變量分為三類��,分別為類別變量&類別變量����,數值變量&數值變量和類別變量&數值變量����。分析兩個變量間的關聯和差異����。
類別變量&類別變量
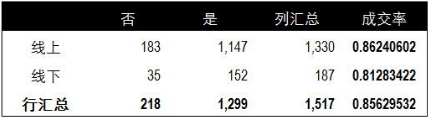
第一個雙變量是類別變量&類別變量�。下面是一組客戶來源和是否成交情況的列表��。記錄了每個客戶的來源以及最終是否成交的情況��。其中客戶來源分為線上和線下兩個來源����,是否成交中已成交的記錄為”是”�����,未成交的記錄為”否”��。對這組數據我們使用卡方檢驗來分析線上與線下來源在成交率上是否有顯著差異���。

卡方檢驗的方法我們之前有單獨的文章進行介紹�,感興趣的朋友可以查看詳細的計算過程����。這里我們粗略說明下計算過程和結果���。首先����,生成頻率表計算出不同來源的成交與未成交數量��。并由此計算出線上和線下來源的成交率數據���。
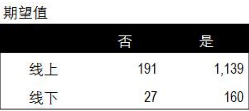
第二步����,根據前面頻率表中的數據��,按照卡方檢驗的方法計算出線上和線下來源成交與未成交的期望值數據����。以下是經過計算獲得的期望值數據��。
最后���,通過使用頻率表和期望值的數據進行計算��,線上和線下的成交率存在顯著差異��。具體數據請參考下表�。

數值變量&數值變量
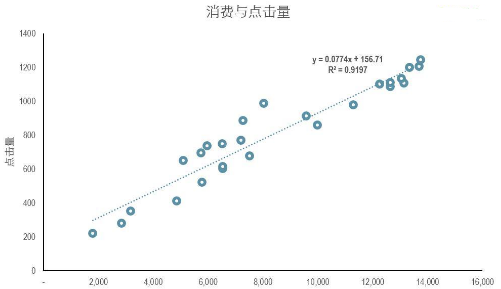
第二個雙變量是數值變量&數值變量����,下面是一組廣告消費和點擊量的數據�����。記錄了在廣告平臺上的消費情況和獲得的點擊量數據��。對于這組數據我們通過關聯分析來分析消費和點擊量之間的關聯����。
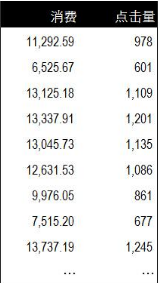
相關分析的方法有很多種��,我們之前單獨有文章介紹過《5種常用的相關分析方法》�����。這里使用相關分析來分析消費和點擊量數據間的關聯�����。通過Excel數據菜單中的數據分析功能獲得消費和點擊量的相關性數據為0.95����,說明消費和點擊量高度正相關��。

對于兩組數值變量���,最好的展現形式是使用散點圖�����。下面通過散點圖描述了點擊量與消費的關系��。隨著消費的增長��,點擊量也隨之增長�。在Excel的散點圖中�����,選擇添加趨勢線可以自動生成回歸方程和判定系數R方�。點擊量有91%的變化可以被解釋�����。
類別變量&數值變量
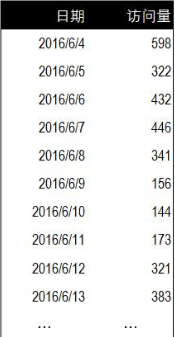
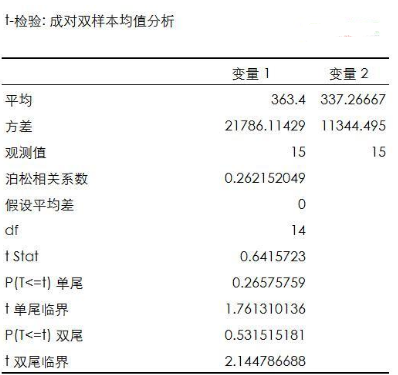
第三個雙變量是類別變量&數值變量����,下面是一組每日訪問量數據�,分別對應了每一天網站獲得的訪問量數據���。其中日期是類別變量��,訪問量是數值變量�����。我們在前15天和后15天分別使用了不同的推廣策略���。下面將分別使用Z建議和T檢驗分析訪問量數據前后變化差異的顯著性���。
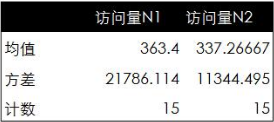
首先將30天的訪問量數據按投放策略分為前后兩組����,每組各15天���,然后計算出每組數據的均值和方差�。具體數據如下表所示�����。
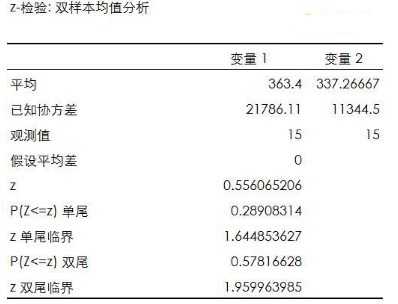
然后在Excel的數據菜單中選擇數據分析�����,使用其中的Z檢驗進行差異顯著性檢驗���。經檢驗��,在95%的置信區間下兩組訪問量數據間不存在顯著性差異�。
T檢驗和Z檢驗類似�����,我們在Excel對數據菜單中選擇數據分析����,使用T檢驗對兩組訪問量數據進行差異顯著性檢驗��,經檢驗在95%的置信區間下兩組訪問量數據不存在顯著差異�����。
最后�,總結一下整篇文章的內容�����。我們將信息分為兩類�,類別變量和數值變量���,類別變量是以文本或布爾值記錄的信息�,數值變量是以數字記錄的信息����。在單獨對這兩類信息進行分析時�����,類別變量通常使用頻率和占比的方法����,數值變量通常使用藐視統計和數據分布的方法進行分析���。在雙變量分析中�,主要分析兩個變量間的關聯和差異的顯著性�����。雙變量分析分為三大類�����,分別為類別變量&類別變量���,數值變量&數值變量和類別變量&數值變量����。第一種類別變量&類別變量通過卡方檢驗分析數據間差異的顯著性�����。數值變量&數值變量通過線性相關分析發現數據間的關系��。類別變量&數值變量通過Z檢驗和T檢驗分析數據間差異的顯著性�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
