【R語言進行數據挖掘】回歸分析
1����、線性回歸
線性回歸就是使用下面的預測函數預測未來觀測量:
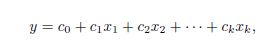
其中��,x1,x2,...,xk都是預測變量(影響預測的因素)�,y是需要預測的目標變量(被預測變量)�����。
線性回歸模型的數據來源于澳大利亞的CPI數據�,選取的是2008年到2011年的季度數據�����。
rep函數里面的第一個參數是向量的起始時間����,從2008-2010�����,第二個參數表示向量里面的每個元素都被4個小時間段��。
year <- rep(2008:2010, each=4)
quarter <- rep(1:4, 3)
cpi <- c(162.2, 164.6, 166.5, 166.0,
166.2, 167.0, 168.6, 169.5,
171.0, 172.1, 173.3, 174.0)
plot函數中axat=“n”表示橫坐標刻度的標注是沒有的
plot(cpi, xaxt="n", ylab="CPI", xlab="")
繪制橫坐標軸
axis(1, labels=paste(year,quarter,sep="Q"), at=1:12, las=3)
接下來�����,觀察CPI與其他變量例如‘year(年份)’和‘quarter(季度)’之間的相關關系��。
cor(year,cpi)
cor(quarter,cpi)
輸出如下:
cor(quarter,cpi)
[1] 0.3738028
cor(year,cpi)
[1] 0.9096316
cor(quarter,cpi)
[1] 0.3738028
由上圖可知���,CPI與年度之間的關系是正相關�,并且非常緊密�����,相關系數接近1�����;而它與季度之間的相關系數大約為0.37�,只是有著微弱的正相關����,關系并不明顯���。
然后使用lm()函數建立一個線性回歸模型�,其中年份和季度為預測因素��,CPI為預測目標�����。
建立模型fit
fit <- lm(cpi ~ year + quarter)
fit
輸出結果如下:
Call:
lm(formula = cpi ~ year + quarter)
Coefficients:
(Intercept) year quarter
-7644.488 3.888 1.167
由上面的輸出結果可以建立以下模型公式計算CPI:
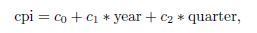
其中�,c0�、c1和c2都是模型fit的參數分別是-7644.488���、3.888和1.167���。因此2011年的CPI可以通過以下方式計算:
(cpi2011 <-fit$coefficients[[1]] + fit$coefficients[[2]]*2011 +
fit$coefficients[[3]]*(1:4))
輸出的2011年的季度CPI數據分別是174.4417���、175.6083�����、176.7750和177.9417�����。
模型的具體參數可以通過以下代碼查看:
查看模型的屬性
attributes(fit)
$names
[1] "coefficients" "residuals" "effects" "rank" "fitted.values"
[6] "assign" "qr" "df.residual" "xlevels" "call"
[11] "terms" "model"
$class
[1] "lm"
模型的參數
fit$coefficients
觀測值與擬合的線性模型之間的誤差�,也稱為殘差
residuals(fit)
1 2 3 4 5 6 7
-0.57916667 0.65416667 1.38750000 -0.27916667 -0.46666667 -0.83333333 -0.40000000
8 9 10 11 12
-0.66666667 0.44583333 0.37916667 0.41250000 -0.05416667
除了將數據代入建立的預測模型公式中��,還可以通過使用predict()預測未來的值��。
輸入預測時間
data2011 <- data.frame(year=2011, quarter=1:4)
cpi2011 <- predict(fit, newdata=data2011)
設置散點圖上的觀測值和預測值對應點的風格(顏色和形狀)
style <- c(rep(1,12), rep(2,4))
plot(c(cpi, cpi2011), xaxt="n", ylab="CPI", xlab="", pch=style, col=style)
標簽中sep參數設置年份與季度之間的間隔
axis(1, at=1:16, las=3,
labels=c(paste(year,quarter,sep="Q"), "2011Q1", "2011Q2", "2011Q3", "2011Q4"))
預測結果如下:
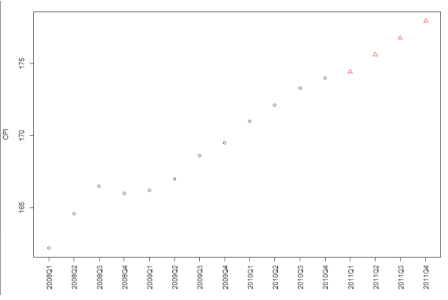
上圖中紅色的三角形就是預測值�����。
2�、Logistic回歸
Logistic回歸是通過將數據擬合到一條線上并根據簡歷的曲線模型預測事件發生的概率��?����?梢酝ㄟ^以下等式來建立一個Logistic回歸模型:

其中�����,x1,x2,...,xk是預測因素���,y是預測目標�。令
����,上面的等式被轉換成:
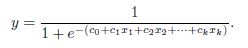
使用函數glm()并設置響應變量(被解釋變量)服從二項分布(family='binomial,'link='logit')建立Logistic回歸模型���,更多關于Logistic回歸模型的內容可以通過以下鏈接查閱:
· R Data Analysis Examples - Logit Regression
· 《LogisticRegression (with R)》
3�����、廣義線性模型
廣義線性模型(generalizedlinear model, GLM)是簡單最小二乘回歸(OLS)的擴展�����,響應變量(即模型的因變量)可以是正整數或分類數據����,其分布為某指數分布族�����。其次響應變量期望值的函數(連接函數)與預測變量之間的關系為線性關系���。因此在進行GLM建模時��,需要指定分布類型和連接函數���。這個建立模型的分布參數包括binomaial(兩項分布)�����、gaussian(正態分布)���、gamma(伽馬分布)�����、poisson(泊松分布)等�。
廣義線性模型可以通過glm()函數建立����,使用的數據是包‘TH.data’自帶的bodyfat數據集����。
data("bodyfat", package="TH.data")
myFormula <- DEXfat ~ age + waistcirc + hipcirc + elbowbreadth + kneebreadth
設置響應變量服從正態分布��,對應的連接函數服從對數分布
bodyfat.glm <- glm(myFormula, family = gaussian("log"), data = bodyfat)
預測類型為響應變量
pred <- predict(bodyfat.glm, type="response")
plot(bodyfat$DEXfat, pred, xlab="Observed Values", ylab="Predicted Values")
abline(a=0, b=1)
預測結果檢驗如下圖所示:
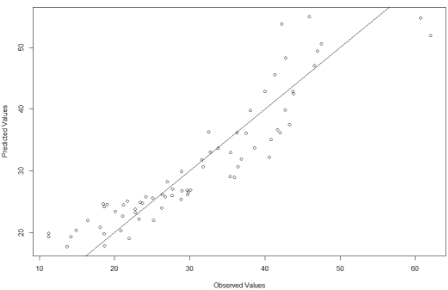
由上圖可知��,模型雖然也有離群點����,但是大部分的數據都是落在直線上或者附近的���,也就說明模型建立的比較好�����,能較好的擬合數據���。
4��、非線性回歸
如果說線性模型是擬合擬合一條最靠近數據點的直線����,那么非線性模型就是通過數據擬合一條曲線��。在R中可以使用函數nls()建立一個非線性回歸模型����,具體的使用方法可以通過輸入'?nls()'查看該函數的文檔�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
