數據挖掘系列樸素貝葉斯分類算法原理與實踐
隔了很久沒有寫數據挖掘系列的文章了�����,今天介紹一下樸素貝葉斯分類算法����,講一下基本原理�����,再以文本分類實踐���。
一個簡單的例子
樸素貝葉斯算法是一個典型的統計學習方法����,主要理論基礎就是一個貝葉斯公式�����,貝葉斯公式的基本定義如下:
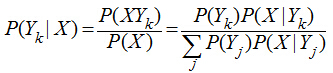
這個公式雖然看上去簡單�,但它卻能總結歷史���,預知未來���。公式的右邊是總結歷史����,公式的左邊是預知未來�����,如果把Y看出類別����,X看出特征����,P(Yk|X)就是在已知特征X的情況下求Yk類別的概率��,而對P(Yk|X)的計算又全部轉化到類別Yk的特征分布上來�。
舉個例子�,大學的時候���,某男生經常去圖書室晚自習����,發現他喜歡的那個女生也常去那個自習室�,心中竊喜�����,于是每天買點好吃點在那個自習室蹲點等她來�����,可是人家女生不一定每天都來����,眼看天氣漸漸炎熱�����,圖書館又不開空調�����,如果那個女生沒有去自修室�,該男生也就不去��,每次男生鼓足勇氣說:“嘿�����,你明天還來不��?”,“啊��,不知道����,看情況”�。然后該男生每天就把她去自習室與否以及一些其他情況做一下記錄�����,用Y表示該女生是否去自習室�����,即Y={去����,不去}��,X是跟去自修室有關聯的一系列條件�,比如當天上了哪門主課����,蹲點統計了一段時間后�,該男生打算今天不再蹲點�,而是先預測一下她會不會去�,現在已經知道了今天上了常微分方法這么主課��,于是計算P(Y=去|常微分方程)與P(Y=不去|常微分方程)����,看哪個概率大�����,如果P(Y=去|常微分方程) >P(Y=不去|常微分方程)����,那這個男生不管多熱都屁顛屁顛去自習室了�,否則不就去自習室受罪了�����。P(Y=去|常微分方程)的計算可以轉為計算以前她去的情況下���,那天主課是常微分的概率P(常微分方程|Y=去)�,注意公式右邊的分母對每個類別(去/不去)都是一樣的�����,所以計算的時候忽略掉分母�,這樣雖然得到的概率值已經不再是0~1之間��,但是其大小還是能選擇類別���。
后來他發現還有一些其他條件可以挖���,比如當天星期幾���、當天的天氣�,以及上一次與她在自修室的氣氛�,統計了一段時間后����,該男子一計算�����,發現不好算了���,因為總結歷史的公式:
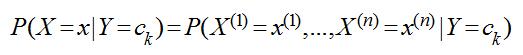
這里n=3���,x(1)表示主課���,x(2)表示天氣�����,x(3)表示星期幾����,x(4)表示氣氛���,Y仍然是{去���,不去}���,現在主課有8門�,天氣有晴�����、雨����、陰三種����、氣氛有A+,A,B+,B��,C五種��,那么總共需要估計的參數有8*3*7*5*2=1680個�,每天只能收集到一條數據����,那么等湊齊1680條數據大學都畢業了��,男生打呼不妙�����,于是做了一個獨立性假設�,假設這些影響她去自習室的原因是獨立互不相關的�����,于是
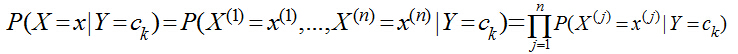
有了這個獨立假設后����,需要估計的參數就變為�����,(8+3+7+5)*2 = 46個了�,而且每天收集的一條數據��,可以提供4個參數��,這樣該男生就預測越來越準了����。
樸素貝葉斯分類器
講了上面的小故事���,我們來樸素貝葉斯分類器的表示形式:
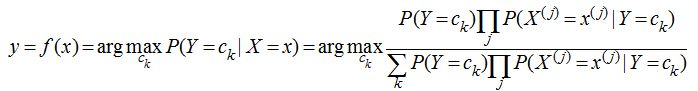
當特征為為x時�����,計算所有類別的條件概率����,選取條件概率最大的類別作為待分類的類別�����。由于上公式的分母對每個類別都是一樣的��,因此計算時可以不考慮分母���,即
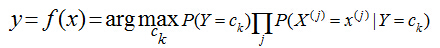
樸素貝葉斯的樸素體現在其對各個條件的獨立性假設上���,加上獨立假設后���,大大減少了參數假設空間�����?���! ?/span>
在文本分類上的應用
文本分類的應用很多��,比如垃圾郵件和垃圾短信的過濾就是一個2分類問題���,新聞分類���、文本情感分析等都可以看成是文本分類問題���,分類問題由兩步組成:訓練和預測��,要建立一個分類模型���,至少需要有一個訓練數據集����。貝葉斯模型可以很自然地應用到文本分類上:現在有一篇文檔d(Document)����,判斷它屬于哪個類別ck���,只需要計算文檔d屬于哪一個類別的概率最大:
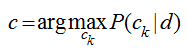
在分類問題中����,我們并不是把所有的特征都用上�����,對一篇文檔d�,我們只用其中的部分特征詞項<t1,t2,...,tnd>(nd表示d中的總詞條數目)�,因為很多詞項對分類是沒有價值的�����,比如一些停用詞“的,是,在”在每個類別中都會出現�����,這個詞項還會模糊分類的決策面�,關于特征詞的選取���,我的這篇文章有介紹�。用特征詞項表示文檔后���,計算文檔d的類別轉化為:
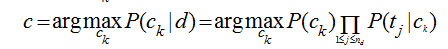
注意P(Ck|d)只是正比于后面那部分公式����,完整的計算還有一個分母�,但我們前面討論了���,對每個類別而已分母都是一樣的�����,于是在我們只需要計算分子就能夠進行分類了��。實際的計算過程中���,多個概率值P(tj|ck)的連乘很容易下溢出為0����,因此轉化為對數計算���,連乘就變成了累加:
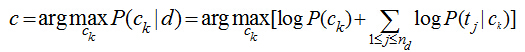
我們只需要從訓練數據集中�����,計算每一個類別的出現概率P(ck)和每一個類別中各個特征詞項的概率P(tj|ck)�,而這些概率值的計算都采用最大似然估計����,說到底就是統計每個詞在各個類別中出現的次數和各個類別的文檔的數目:
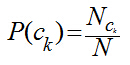
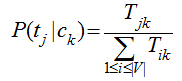
其中����,Nck表示訓練集中ck類文檔的數目�����,N訓練集中文檔總數���;Tjk表示詞項tj在類別ck中出現的次數�,V是所有類別的詞項集合�����。這里對詞的位置作了獨立性假設���,即兩個詞只要它們出現的次數一樣��,那不管它們在文檔的出現位置����,它們大概率值P(tj|ck)都是一樣��,這個位置獨立性假設與現實很不相符����,比如“放馬屁”跟“馬放屁”表述的是不同的內容�,但實踐發現����,位置獨立性假設得到的模型準確率并不低���,因為大多數文本分類都是靠詞的差異來區分���,而不是詞的位置�����,如果考慮詞的位置���,那么問題將表達相當復雜����,以至于我們無從下手����。
然后需要注意的一個問題是ti可能沒有出現在ck類別的訓練集���,卻出現在ck類別的測試集合中����,這樣因為Tik為0���,導致連乘概率值都為0��,其他特征詞出現得再多��,該文檔也不會被分到ck類別�,而且在對數累加的情況下�����,0值導致計算錯誤�����,處理這種問題的方法是采樣加1平滑����,即認為每個詞在各個類別中都至少出現過一次��,即
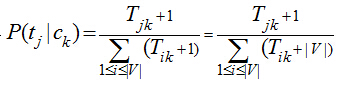
下面這個例子來自于參考文獻1����,假設有如下的訓練集合測試集:

現在要計算docID為5的測試文檔是否屬于China類別��,首先計算個各類的概率���,P(c=China)=3/4,P(c!=China)=1/4���,然后計算各個類中詞項的概率:
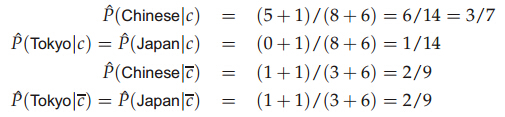
注意分母(8+6)中8表示China類的詞項出現的總次數是8�����,+6表示平滑�����,6是總詞項的個數�,然后計算測試文檔屬于各個類別的概率:
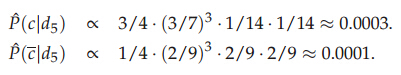
可以看出該測試文檔應該屬于CHina類別����。
文本分類實踐
我找了搜狗的搜狐新聞數據的歷史簡潔版��,總共包括汽車����、財經����、it��、健康等9類新聞�����,一共16289條新聞��,搜狗給的數據是每一篇新聞用一個txt文件保存��,我預處理了一下�,把所有的新聞文檔保存在一個文本文件中����,每一行是一篇新聞�,同時保留新聞的id�,id的首字母表示類標���,預處理并分詞后的示例如下:

我用6289條新聞作為訓練集��,剩余1萬條用于測試����,采用互信息進行文本特征的提取�����,總共提取的特征詞是700個左右�。
分類的結果如下:
8343100000.8343
總共10000條新聞����,分類正確的8343條�,正確率0.8343��,這里主要是演示貝葉斯的分類過程���,只考慮了正確率也沒有考慮其他評價指標��,也沒有進行優化��。貝葉斯分類的效率高����,訓練時�����,只需要掃描一遍訓練集����,記錄每個詞出現的次數�,以及各類文檔出現的次數��,測試時也只需要掃描一次測試集�����,從運行效率這個角度而言����,樸素貝葉斯的效率是最高的����,而準確率也能達到一個理想的效果����。
我的實現代碼如下:
1 #!encoding=utf-8
2 import random
3 import sys
4 import math
5 import collections
6 import sys
7 def shuffle():
8 '''將原來的文本打亂順序�,用于得到訓練集和測試集'''
9 datas = [line.strip() for line in sys.stdin]
10 random.shuffle(datas)
11 for line in datas:
12 print line
13
14
15 lables = ['A','B','C','D','E','F','G','H','I']
16 def lable2id(lable):
17 for i in xrange(len(lables)):
18 if lable == lables[i]:
19 return i
20 raise Exception('Error lable %s' % (lable))
21
22 def docdict():
23 return [0]*len(lables)
24
25 def mutalInfo(N,Nij,Ni_,N_j):
26 #print N,Nij,Ni_,N_j
27 return Nij * 1.0 / N * math.log(N * (Nij+1)*1.0/(Ni_*N_j))/ math.log(2)
28
29 def countForMI():
30 '''基于統計每個詞在每個類別出現的次數��,以及每類的文檔數'''
31 docCount = [0] * len(lables)#每個類的詞數目
32 wordCount = collections.defaultdict(docdict)
33 for line in sys.stdin:
34 lable,text = line.strip().split(' ',1)
35 index = lable2id(lable[0])
36 words = text.split(' ')
37 for word in words:
38 wordCount[word][index] += 1
39 docCount[index] += 1
40
41 miDict = collections.defaultdict(docdict)#互信息值
42 N = sum(docCount)
43 for k,vs in wordCount.items():
44 for i in xrange(len(vs)):
45 N11 = vs[i]
46 N10 = sum(vs) - N11
47 N01 = docCount[i] - N11
48 N00 = N - N11 - N10 - N01
49 mi = mutalInfo(N,N11,N10+N11,N01+N11) + mutalInfo(N,N10,N10+N11,N00+N10)+ mutalInfo(N,N01,N01+N11,N01+N00)+ mutalInfo(N,N00,N00+N10,N00+N01)
50 miDict[k][i] = mi
51 fWords = set()
52 for i in xrange(len(docCount)):
53 keyf = lambda x:x[1][i]
54 sortedDict = sorted(miDict.items(),key=keyf,reverse=True)
55 for j in xrange(100):
56 fWords.add(sortedDict[j][0])
57 print docCount#打印各個類的文檔數目
58 for fword in fWords:
59 print fword
60
61
62 def loadFeatureWord():
63 '''導入特征詞'''
64 f = open('feature.txt')
65 docCounts = eval(f.readline())
66 features = set()
67 for line in f:
68 features.add(line.strip())
69 f.close()
70 return docCounts,features
71
72 def trainBayes():
73 '''訓練貝葉斯模型�,實際上計算每個類中特征詞的出現次數'''
74 docCounts,features = loadFeatureWord()
75 wordCount = collections.defaultdict(docdict)
76 tCount = [0]*len(docCounts)#每類文檔特征詞出現的次數
77 for line in sys.stdin:
78 lable,text = line.strip().split(' ',1)
79 index = lable2id(lable[0])
80 words = text.split(' ')
81 for word in words:
82 if word in features:
83 tCount[index] += 1
84 wordCount[word][index] += 1
85 for k,v in wordCount.items():
86 scores = [(v[i]+1) * 1.0 / (tCount[i]+len(wordCount)) for i in xrange(len(v))]#加1平滑
87 print '%s\t%s' % (k,scores)
88
89 def loadModel():
90 '''導入貝葉斯模型'''
91 f = open('model.txt')
92 scores = {}
93 for line in f:
94 word,counts = line.strip().rsplit('\t',1)
95 scores[word] = eval(counts)
96 f.close()
97 return scores
98
99 def predict():
100 '''預測文檔的類標���,標準輸入每一行為一個文檔'''
101 docCounts,features = loadFeatureWord()
102 docscores = [math.log(count * 1.0 /sum(docCounts)) for count in docCounts]
103 scores = loadModel()
104 rCount = 0
105 docCount = 0
106 for line in sys.stdin:
107 lable,text = line.strip().split(' ',1)
108 index = lable2id(lable[0])
109 words = text.split(' ')
110 preValues = list(docscores)
111 for word in words:
112 if word in features:
113 for i in xrange(len(preValues)):
114 preValues[i]+=math.log(scores[word][i])
115 m = max(preValues)
116 pIndex = preValues.index(m)
117 if pIndex == index:
118 rCount += 1
119 print lable,lables[pIndex],text
120 docCount += 1
121 print rCount,docCount,rCount * 1.0 / docCount
122
123
124 if __name__=="__main__":
125 #shuffle()
126 #countForMI()
127 #trainBayes()
128 predict()
代碼里面�,計算特征詞與訓練模型�����、測試是分開的�����,需要修改main方法�����,比如計算特征詞:
$cat train.txt | python bayes.py > feature.txt
訓練模型:
$cat train.txt | python bayes.py > model.txt
預測模型:
$cat test.txt | python bayes.py > predict.out
總結
本文介紹了樸素貝葉斯分類方法��,還以文本分類為例���,給出了一個具體應用的例子�����,樸素貝葉斯的樸素體現在條件變量之間的獨立性假設�,應用到文本分類上����,作了兩個假設����,一是各個特征詞對分類的影響是獨立的���,另一個是詞項在文檔中的順序是無關緊要的��。樸素貝葉斯的獨立性假設在實際中并不成立���,但在分類效上依然不錯��,加上獨立性假設后�,對與屬于類ck的謀篇文檔d�����,其p(ck|d)往往會估計過高�,即本來預期p(ck|d)=0.55�����,而樸素貝葉斯卻計算得到p(ck|d)=0.99���,但這并不影響分類結果����,這是樸素貝葉斯分類器在文本分類上效果優于預期的原因�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
