使用SPSS 文本挖掘工具構建社交媒體數據集市
文本挖掘 指的是用來從不同文字來源提取信息的技術�。它為何如此重要呢����?據普遍估計�����,在所有與業務有關的信息中��,有 80% 的信息是非結構化文本數據和半結構化文本數據���。換言之���,如果不對這 80% 的信息所代表的大量數據應用文本分析�,所有嵌入的業務信息和消費者行為數據都會被浪費��。術語文本挖掘 常常被稱為文本分析 具有很多的實際意義�����,比如垃圾過濾����、從電子商務網站上的意見和建議中提取信息�����、在博客和評論網站中進行社交收聽和意見挖掘�����、增強客戶服務和電子郵件支持�����、業務文檔的自動化處理���、法律領域的電子發現�����、衡量消費者的偏好�����、索賠分析和欺詐檢測���,以及網絡犯罪和國家安全應用程序��。
文本挖掘類似于數據挖掘���,因為它也針對的識別出數據內的有趣模式���。雖然手動(而且是高度勞動密集)文本挖掘出現于二十世紀八十年代���。在近些年來���,對于通過定義搜索引擎結果算法和篩選數據源來發現未知信息而言���,文本挖掘領域十分重要���。諸如機器學習�����、數據統計��、計算語言學和數據挖掘這樣的技術均在這個過程中發揮了重要作用�����。例如�,文本的知識發現目標是使用自然語言處理 (NLP) 從文本��、內容和暗示的上下文中檢測底層的語義關系��。這個過程旨在使用 NLP 進行復制�,然后衡量相同類型的語言區別�、模式識別以及閱讀和處理文本時的理解�����。
文本挖掘領域中有各種方法�����。下面將介紹文本挖掘所涉及到的一系列常見步驟和后續步驟���。
文本挖掘的第一個步驟是識別出想要分析的基于文本的源����,并通過信息檢索或選擇包含這組文本文件和感興趣內容的語法庫來收集這種材料��。擴展 NLP 的部署可以調用 “部分詞類標注” 和文本順序來解析語法(即語匯單元化 文本)�����,并應用 Named Entity Recognition(即確認品牌�、人的姓名���、地點�、常見縮略語等內容的提及)�����。而迭代的 Filter Stopwords 步驟則涉及禁用詞的刪除���,從而提煉出所需的主題內容�。Pattern Identified Entities 能識別電子郵件地址和電話號碼����,Coreference 則能識別文本內的名詞短語以及相關對象���,后跟 Relationship, Fact and Event Extraction�����。通常會生成 N-Grams����,它創建一系列連續單詞作為術語����。最后����,執行語義分析����,社交媒體偵聽和分類工具如今廣泛使用采用這種方式來提取對某個對象或主題的態度信息�����。很多時候����,各種映射和繪制功能還提供了可視化�����,以便進行進一步的準確驗證�����。
文本挖掘軟件和應用程序有很多商業和開源選項����。IBM 提供了種類繁多且強健的文本挖掘解決方案����。利用了 IBM? InfoSphere? BigInsights? 大數據功能的一種功能強大的方案提供了附加文本分析模塊��,能夠從 InfoSphere BigInsights 集群運行文本分析提取����。IBM SPSS? 方案規模和范圍都很廣泛�。對于搜索文檔并將它分配給一個主題非常有效的一個工具是 IBM SPSS Modeler�����,它能提供一個圖形界面來執行通常的文本文檔分類和分析��。另一個產品 IBM SPSS Text Analytics for Surveys 則使用了 NLP�����,對于分析文檔內開放的調查問題非常有用�����。IBM SPSS Modeler Premium 與 SPSS Text Analytics for Surveys 運行在同一個引擎上�����,但是可伸縮性更高�,能處理一個有助于結構化和非結構化數據集成的綜合工作臺內文檔(PDF�����、Web 頁面��、博客��、電子郵件��、Twitter 提要等)的整個語料庫��。面向 Facebook 的一個相關的自定義代碼節點擴展了 SPSS Modeler Premium 的功能�,以便能夠直接從 Facebook wall 直接讀取數據����,并與 SPSS Modeler 內的 Twitter 提要相集成����,從而獲得多社交媒體渠道觀點�。
在開源文本挖掘工具中����,RapidMiner 和 R 這兩個工具最為流行����。R 有更大的用戶群�����,它是一種需要源代碼的編程語言���,有許多算法選擇��。但可伸縮性一直是 R 的一個問題�����,所以���,對于大型數據集�,如果沒有變通方案�,R 不是一個理想選擇�����。RapidMiner 的用戶群較小����,但它不要求源代碼��,并且有一個強大的用戶界面 (UI)�����。而且它是高度可伸縮的�����,能夠處理集群和數據庫內編程��。IBM 提供了一個將查詢內的 R 項目集成在一起的 Jaql R 模塊��,它允許 MapReduce 作業并行運行 R 計算�。
現在我們將簡要介紹 NoSQL 和 Structured Query Language (SQL) 選項和技術堆棧的選擇過程����。當數據源變得難以處理時����,正如社交媒體數據中經常出現的情形那樣����,能夠有效集成 Hadoop 和其他功能擴展的開源工具的商業 NoSQL 選項(比如 IBM InfoSphere BigInsights)組合就顯得十分必要����。圖形數據庫���、關鍵值和文檔存儲都是可用的��,可基于主要用例做出最佳選擇���。對文本挖掘和分析感興趣的公司通常會選擇將 Hadoop 并與其他的開源工具相集成�,比如 Apache Mahout�,這是一種可提供分類�、集群和協作過濾的機器學習引擎����。Storm 的元組和流可以管理實時分析�����,操縱 Hadoop 的高延遲性���。
在將文本挖掘應用于社交媒體數據時���,有一些獨特的挑戰�����。社交網絡站點���、博客和論壇生成的數據屬于通常所說的大數據 范疇�����。數據是未結構化或半結構化的數據���,每天會圍繞較大品牌生成數千兆字節的數據����,而傳統的數據庫無法有效擴展來支持基于這些數據的實時分析�����。因此需要提供大數據和 NoSQL 數據庫解決方案��。
如果沒有定期收集并充分存儲社交媒體數據��,這些數據是很容易遭到破壞���。大多數開源社交偵聽工具僅存儲社交媒體評論歷史記錄的幾天內的記錄��。Twitter 也是最近才宣布會保存整個數據歷史記錄�,但僅限于由帳戶持有人明確發布的評論����。通過之前提及的一些更大型的社交數據提供商���,比如 Gnip 和 DataSift�����,以及基于量和調用的應用程序編程接口(API)和其他工具�����,可以獲得這類數據��。但是�,雖然可以獲得這類數據(對于 Twitter)���,除了那些最大的品牌之外���,價格對于一般人而言顯得尤為昂貴���。
每個社交媒體網站對這個問題的處理方式都是大相徑庭的��。根據數據的量和數據的特性�����,可以使用搜索請求和提供 JavaScript Object Notation (JSON) 格式響應�����,這些響應包含未解析的數據�����,以便立即包含在一個 MySQL 或 NoSQL 數據庫中���。
回頁首
品牌為文本挖掘提供了不同的目標:
像 Sears 這樣的公司��,如 示例 1 所示���,可能有興趣在新產品線啟動后通過社交媒體評論和 Facebook 頁面粉絲的交互來直接跟蹤消費者的觀點�����。這樣一來��,更容易理解圍繞圖片�、產品和啟動產品而引起的對話集群的基本反響��。通過這種實時的反饋可以實現快速的消息更新和非流行內容的刪除�,并且 Facebook 的粉絲們成為了實時焦點群��,提供了產品特性的即時反饋�。
JACT Media 公司的任務是構建品牌和視頻游戲玩家之間的關系��。該公司提供了一個游戲內的臨時設施�����,在玩家玩常玩游戲的同時向玩家展示各種具有針對性的����、已安排好的內容���。玩家贏得 JACT 虛擬貨幣�����,而這些 JACT BUX 可兌換獎品��,包括虛擬的和可下載的商品�����。玩家在 Facebook 頁面或 Twitter 上與 JACT 交互�,并頻繁在游戲論壇經常提及 JACT BUX����。這種原始的評論數據可從各種來源獲取���,并且可以存儲個人級別的評論和偏好��。比如��,如果玩家對某個視頻游戲特別感興趣���,或是在 tweet 上提到了自己的獎品�,那么基于特定游戲的游戲內目標鎖定和獎品類型可能比隨機的獎勵更能促進忠誠度的增加�����。
超市也能夠使用社交媒體數據來識別更為有價值的購物者�、對客服的印象����、商店的環境���、產品的偏好�����、包裝的偏好和定價�����。將這類信息與 Twitter 或移動設備提供的位置數據匯總在一起����,超市就能從某個角度進行定位���,量身定制購物體驗��。而這對于庫存��、定價����、廣告���、個人數字和郵寄優惠券等都有影響��。
示例 1:SPSS Modeler Premium 中的社交媒體數據和文本挖掘
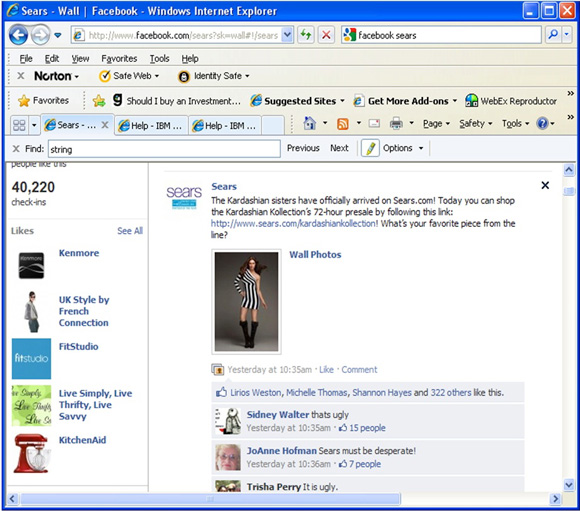
第一個示例是一個 SPSS Modeler Premium 用例�。在此場景中�,啟動了一個新的產品線�����,該公司有興趣跟蹤社會媒體數據中的消費者反應����。SPSS Modeler Premium Facebook 節點被用來跟蹤 Sears Facebook 頁面上的新 Kardashian 產品線�,如 圖 1 所示���。
圖 1. 零售商在 Facebook 上啟動了一個新的產品線
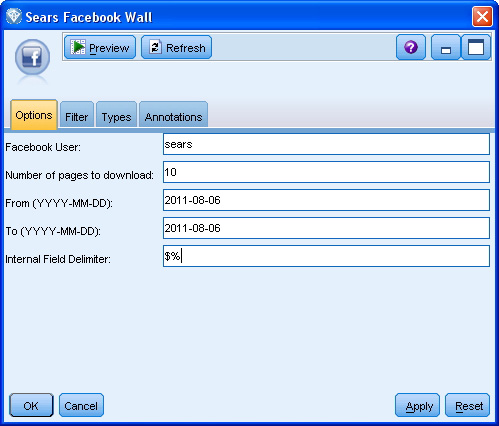
在跟蹤和分析評論數據的第一個步驟中�,涉及到要求用戶指定用戶名以及在 SPSS Modeler Premium Facebook 節點中用于評論的頁面和線程的數量����,如 圖 2 所示���。
圖 2. 用于通過提取 Facebook wall 評論來識別啟動后的評論反饋分析的 SPSS Modeler
然后��,會從 Sears Facebook 頁面提取評論數據�����,并在 SPSS Modeler 中使用它����,如 圖 3 所示�。
圖 3. 可直接通過 SPSS Modeler Facebook 節點查看的原始評論數據
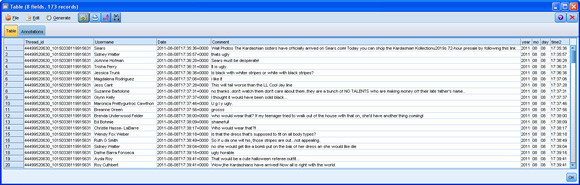
(請查看 圖 3 的大圖��。)
下一個步驟涉及到添加過濾器和執行概念提取����,從而形象地描述圍繞該品牌的內容類別�。這個用戶友好的圖形 UI 可在整個過程中引導用戶����,并且不需要使用 API 從 Twitter 或 Facebook 中提取社交數據�����。其結果是獲得一個容易理解的概念地圖��,并了解連接線的厚度所代表的概念集群的敏感性�,如 圖 4 所示��。
圖 4. 概念地圖為品牌提供了概念強度類別的可視化
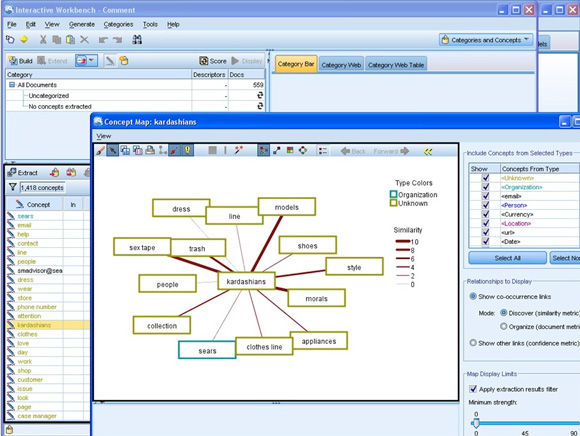
(請查看圖 4 的大圖��。)
示例 2:在 SPSS Statistics Base 中使用了提取內容和禁止詞的超市產品偏好示例
下列的社交媒體數據集市組裝過程描述了一個簡單的手動文本挖掘過程�����。在這個示例中�����,我們希望使用借助了 SPSS Statistics Base 的文本挖掘來獲取和存儲來自社交媒體數據的各種產品偏好�。本例包括一個從 Twitter 和 Facebook 提取超市品牌數據的分步指南����。過程架構如 圖 5 所示��。
圖 5. BrandMeter 社交媒體數據集市架構
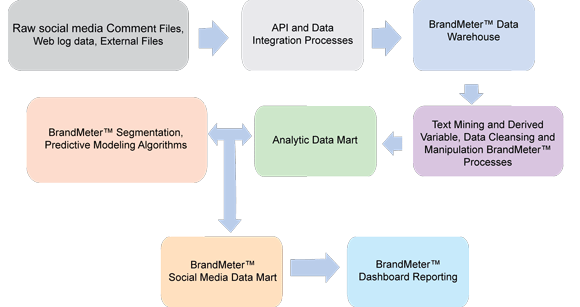
(請查看 圖 5 的大圖�。)
第一步是確定感興趣的品牌����。設置一個例程來通過一個 API 過程收集與品牌相關的提及����。這是通過 圖 6 中所示的搜索請求來完成的��,結果是以 JSON 格式返回的�。一個 JSON 庫會解析數據�����,并將每個記錄分成多個字段�����,這些字段包含了像用戶 ID����、數據和未處理的文本消息評論這樣的信息���。然后��,此數據會存儲在一個數據庫中���,并且可供文本挖掘使用���。
圖 6. 用來訪問原始 Twitter 和 Facebook 評論數據的示例 API

(請查看 圖 6 的大圖�。)
這個簡化的文本挖掘練習的目標是確定特定消費者產品偏好和消費模式��。然后�,此信息會存儲在社交媒體數據集市在�����。對于這個特定示例��,假設您想要確定蔬菜玉米的所有消費者���。圖 7 顯示了 Character Index 函數的使用情況��,該函數可識別原始評論數據中使用了單詞 corn 的所有實例���。
圖 7. 用 SPSS Base Character Index 函數提取文本
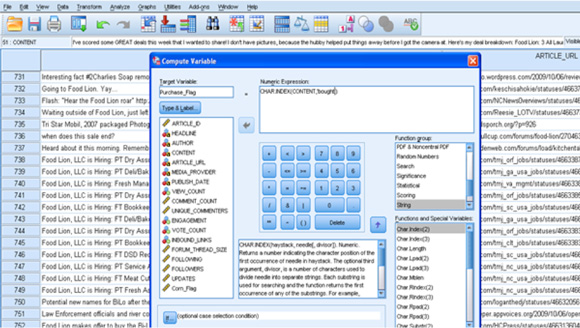
(請查看 圖 7 的大圖����。)
這些結果還需要進一步的過濾����,并且需要通過各種迭代來應用禁止詞���,從而提高分類的準確性���。通過應用像 popcorn��、candy corn����、corndog 和 corn syrup 這樣的禁止詞�����,并限制實例為四個字符的組合�,可以讓玉米產品的識別更準確一些�����。然后可以使用 'corn_consumer_flag'=1 在數據庫中標記這些用戶名�,并在未來市場營銷活動中�����,為特定于玉米的產品和食品而選中它們�����。(請查看 圖 8����。)
圖 8. 使用了禁止詞的原始評論分類過程
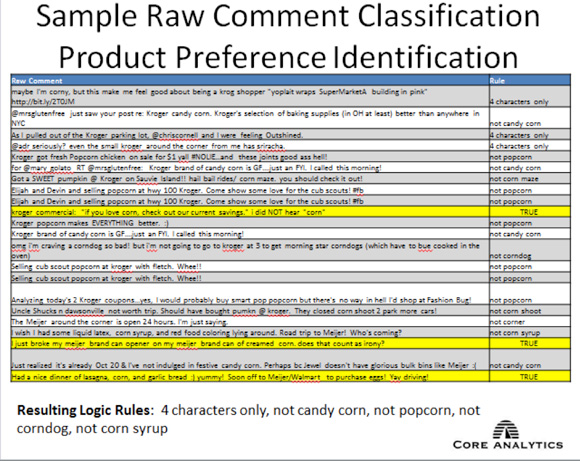
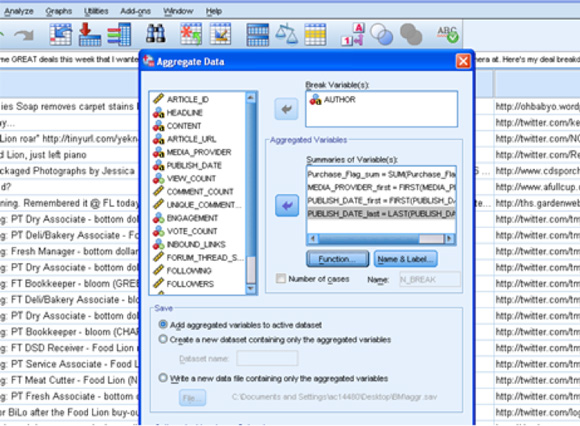
在獲得詳盡的列表之后��,您就可以執行用戶 ID 聚合���,并填充表來捕獲產品購買�����、包裝方面的評論和其他存儲了個人級別消費者行為的變量���。在本例中����,原始社交媒體數據存儲在一個 NoSQL 數據庫內����,而所得到的產品偏好標志則存儲在一個 MySQL 數據集市內�����,其中用戶 ID 是一個主匹配鍵(參見 圖 9)�。
圖 9. 用 SPSS Base Aggregate 函數將評論數據聚合到用戶 ID 級別
結束語
文本挖掘愈來愈流行�����,因為很多公司評估使用社交媒體作為一種市場營銷和品牌交互渠道的潛在回報��。許多公司都急于實現大數據存儲方案����,以便存儲未結構化的數據�����,并將這些數據與傳統的交易類型數據相集成�����。社交媒體評論和與品牌相關的交互數據提供了對消費者偏好的洞察��,可以利用這些偏好信息來設計相關的產品特性��,并采用與消費者需求和預期相吻合的方式進行市場營銷��。如果為了獲得更深入的品牌體驗定制而將這類個人級別的行為和偏好數據存儲在社交媒體數據集市中���,那么這將會將信息置于公司的手中��,公司可以使用這些信息來充實消費者與品牌的關系��,促使消費者參與其品牌體驗的自我管理����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
