R與并行計算
本文首先介紹了并行計算的基本概念���,然后簡要闡述了R和并行計算的關系��。之后作者從R語言用戶的使用角度討論了隱式和顯示兩種并行計算模式���,并給出了相應的案例�。隱式并行計算模式不僅提供了簡單清晰的使用方法�,而且很好的隱藏了并行計算的實現細節����。因此用戶可以專注于問題本身����。顯示并行計算模式則更加靈活多樣�,用戶可以按照自己的實際問題來選擇數據分解���,內存管理和計算任務分配的方式����。最后�����,作者探討了現階段R并行化的挑戰以及未來的發展��。
R與并行計算
統計之都的小伙伴們對R�,SAS�����,SPSS�����, MATLAB之類的統計軟件的使用定是輕車熟路了�,但是對并行計算(又名高性能計算��,分布式計算)等概念可能多少會感到有點陌生����。應太云兄之邀��,在此給大家介紹一些關于并行計算的基本概念以及在R中的使用����。
什么是并行計算����?
并行計算�����,準確地說應該包括高性能計算機和并行軟件兩個方面����。在很長一段時間里���,中國的高性能計算機處于世界領先水平���。在最近一期的世界TOP500超級計算機排名中�����,中國的神威太湖之光列居榜首�。 但是高性能計算機的應用領域卻比較有限���,主要集中在軍事���,航天航空等國防軍工以及科研領域����。對于多數個人�����,中小型企業來說高性能計算機還是陽春白雪���。
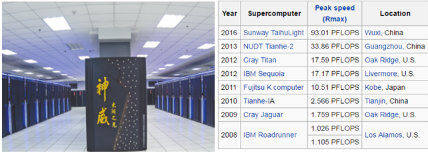
不過��,近年來隨著個人PC機���,廉價機群���,以及各種加速卡(NVIDIA GPU, Intel Xeon Phi, FPGA)的快速發展�,現在個人電腦已經完全可以和過去的高性能計算機相媲美了�����。相比于計算機硬件的迅速發展����,并行軟件的發展多少有些滯后���,試想你現在使用的哪些軟件是支持并行化運算的呢����?

軟件的并行化需要更多的研發支持����,以及對大量串行算法和現有軟件的并行化����,這部分工作被稱之為代碼現代化(code modernization)��。聽起來相當高大上的工作����,然而在實際中大量的錯誤修正(BUGFIX)�����,底層數據結構重寫�����,軟件框架的更改�����,以及代碼并行化之后帶來的運行不確定性和跨平臺等問題極大地增加了軟件的開發維護成本和運行風險�,這也使得這項工作在實際中并沒有想象中的那么吸引人����。
R為什么需要并行計算����?
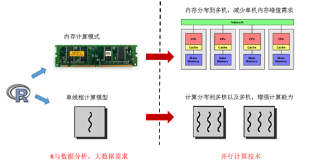
那么言歸正傳���,讓我們回到R本身�。R作為當前最流行的統計軟件之一����,具有非常多的優點�����,比如豐富的統計模型與數據處理工具�����,以及強大的可視化能力�。但隨著數據量的日漸增大�����,R的內存使用方式和計算模式限制了R處理大規模數據的能力�����。從內存角度來看�,R采用的是內存計算模式(In-Memory)�����,被處理的數據需要預取到主存(RAM)中���。其優點是計算效率高��、速度快���,但缺點是這樣一來能處理的問題規模就非常有限(小于RAM的大?�。?��。另一方面���,R的核心(R core)是一個單線程的程序����。因此�����,在現代的多核處理器上���,R無法有效地利用所有的計算內核����。腦補一下��,如果把R跑到具有260個計算核心的太湖之光CPU上����,單線程的R程序最多只能利用到1/260的計算能力�����,而浪費了其他259/260的計算核心��。
怎么破�?并行計算�!
并行計算技術正是為了在實際應用中解決單機內存容量和單核計算能力無法滿足計算需求的問題而提出的�。因此�����,并行計算技術將非常有力地擴充R的使用范圍和場景�。最新版本的R已經將parallel包設為了默認安裝包�����?���?梢奟核心開發組也對并行計算非常重視了��。
R用戶:如何使用并行計算��?
從用戶的使用方式來劃分��,R中的并行計算模式大致可以分為隱式和顯示兩種�����。下面我將用具體實例給大家做一個簡單介紹����。
隱式并行計算
隱式計算對用戶隱藏了大部分細節�����,用戶不需要知道具體數據分配方式 ����,算法的實現或者底層的硬件資源分配�����。系統會根據當前的硬件資源來自動啟動計算核心����。顯然�,這種模式對于大多數用戶來說是最喜聞樂見的���。我們可以在完全不改變原有計算模式以及代碼的情況下獲得更高的性能���。常見的隱式并行方式包括:
1�、 使用并行計算庫�,如OpenBLAS�����,Intel MKL�,NVIDIA cuBLAS
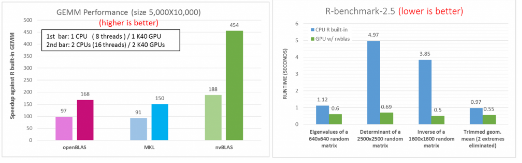
這類并行庫通常是由硬件制造商提供并基于對應的硬件進行了深度優化�����,其性能遠超R自帶的BLAS庫�,所以建議在編譯R的時候選擇一個高性能庫或者在運行時通過LD_PRELOAD來指定加載庫�。具體的編譯和加載方法可以參見這篇博客的附錄部分【1】�����。在下面左圖中的矩陣計算比較實驗中���,并行庫在16核的CPU上輕松超過R原有庫百倍之多���。在右圖中�����,我們可以看到GPU的數學庫對常見的一些分析算法也有相當顯著的提速���。
2�����、使用R中的多線程函數
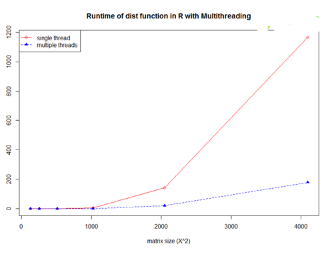
OpenMP是一種基于共享內存的多線程庫�����,主要用于單節點上應用程序加速���。最新的R在編譯時就已經打開了OpenMP選項����,這意味著一些計算可以在多線程的模式下運行���。比如R中的dist函數就 是一個多線程實現的函數���,通過設置線程數目來使用當前機器上的多個計算核心����,下面我們用一個簡單的例子來感受下并行計算的效率���, GitHub上有完整代碼【2】�, 此代碼需在Linux系統下運行���。
#comparison of single thread and multiple threads run
for(i in 6:11) {
ORDER <- 2^i
m <- matrix(rnorm(ORDER*ORDER),ORDER,ORDER);
.Internal(setMaxNumMathThreads(1)); .Internal(setNumMathThreads(1)); res <- system.time(d <- dist(m))
print(res)
.Internal(setMaxNumMathThreads(20)); .Internal(setNumMathThreads(20)); res <- system.time(d <- dist(m))
print(res)
}
3�、使用并行化包
在R高性能計算列表【3】中已經列出了一些現有的并行化包和工具�����。用戶使用這些并行化包可以像使用其他所有R包一樣快捷方便�����,始終專注于所處理的問題本身���,而不必考慮太多關于并行化實現以及性能提升的問題�。我們以H2O.ai【4】為例���。 H2O后端使用Java實現多線程以及多機計算�����,前端的R接口簡單清晰��,用戶只需要在加載包之后初始化H2O的線程數即可�����,后續的計算�����, 如GBM����,GLM, DeepLearning算法����,將會自動被分配到多個線程以及多個CPU上����。詳細函數可參見H2O文檔
【5】���。
R is connected to the H2O cluster:
H2O cluster uptime: 1 hours 53 minutes
H2O cluster version: 3.8.3.3
H2O cluster name: H2O_started_from_R_patricz_ywj416
H2O cluster total nodes: 1
H2O cluster total memory: 1.55 GB
H2O cluster total cores: 4
H2O cluster allowed cores: 4
H2O cluster healthy: TRUE
H2O Connection ip: localhost
H2O Connection port: 54321
H2O Connection proxy: NA
R Version: R version 3.3.0 (2016-05-03)
顯示并行計算
顯式計算則要求用戶能夠自己處理算例中數據劃分��,任務分配��,計算以及最后的結果收集����。因此���,顯式計算模式對用戶的要求更高�,用戶不僅需要理解自己的算法�,還需要對并行計算和硬件有一定的理解�。值得慶幸的是�,現有R中的并行計算框架�,如parallel (snow,multicores)���,Rmpi和foreach等采用的是映射式并行模型(Mapping)��,使用方法簡單清晰����,極大地簡化了編程復雜度�����。R用戶只需要將現有程序轉化為*apply或者for的循環形式之后��,通過簡單的API替換來實現并行計算��。對于更為復雜的計算模式��,用戶可以通過重復映射收集(Map-Reduce)的過程來構造���。
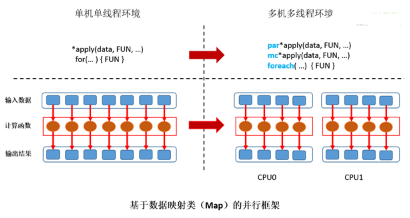
下面我們用一元二次方程求解問題來介紹如何利用*apply和foreach做并行化計算�,完整的代碼(ExplicitParallel.R)【6】可以在GitHuB上下載�。首先�,我們給出一個非向量化的一元二次方程求解函數�,其中包括了對幾種特殊情況的處理����,如二次項系數為零���,二次項以及一次項系數都為零或者開根號數為負��。我們隨機生成了3個大向量分別保存了方程的二次項���,一次項和常數項系數�����。
# Not vectorized function
solve.quad.eq <- function(a, b, c) {
# Not validate eqution: a and b are almost ZERO
if(abs(a) < 1e-8 && abs(b) < 1e-8) return(c(NA, NA) )
# Not quad equation
if(abs(a) < 1e-8 && abs(b) > 1e-8) return(c(-c/b, NA))
# No Solution
if(b*b - 4*a*c < 0) return(c(NA,NA))
# Return solutions
x.delta <- sqrt(b*b - 4*a*c)
x1 <- (-b + x.delta)/(2*a)
x2 <- (-b - x.delta)/(2*a)
return(c(x1, x2))
}
# Generate data
len <- 1e6
a <- runif(len, -10, 10)
a[sample(len, 100,replace=TRUE)] <- 0
b <- runif(len, -10, 10)
c <- runif(len, -10, 10)
apply實現方式: 首先我們來看串行代碼�����,下面的代碼利用lapply函數將方程求解函數solve.quad.eq映射到每一組輸入數據上����,返回值保存到列表里��。
# serial code
system.time(
res1.s <- lapply(1:len, FUN = function(x) { solve.quad.eq(a[x], b[x], c[x])})
)
接下來����,我們利用parallel包里的mcLapply (multicores)來并行化lapply中的計算����。從API的接口來看���,除了額外指定所需計算核心之外�,mcLapply的使用方式和原有的lapply一致�,這對用戶來說額外的開發成本很低�。mcLapply函數利用Linux下fork機制來創建多個當前R進程的副本并將輸入索引分配到多個進程上����,之后每個進程根據自己的索引進行計算���,最后將其結果收集合并�。在該例中我們指定了2個工作進程����,一個進程計算1:(len/2), 另一個計算(len/2+1):len的數據�����,最后當mcLapply返回時將兩部分結果合并到res1.p中�。但是���,由于multicores在底層使用了Linux進程創建機制���,所以這個版本只能在Linux下執行��。
# parallel
library(parallel)
# multicores on Linux
system.time(
res1.p <- mclapply(1:len, FUN = function(x) { solve.quad.eq(a[x], b[x], c[x])}, mc.cores = 2)
)
對于非Linux用戶來說���,我們可以使用parallel包里的parLapply函數來實現并行化�。parLapply函數支持Windows��,Linux��,Mac等不同的平臺�����,可移植性更好��,但是使用稍微復雜一點��。在使用parLapply函數之前��,我們首先需要建立一個計算組(cluster)���。計算組是一個軟件層次的概念�,它指我們需要創建多少個R工作進程(parallel包會創建新的R工作進程���,而非multicores里R父進程的副本)來進行計算���,理論上計算組的大小并不受硬件環境的影響����。比如說我們可以創建一個大小為1000的計算組�����,即有1000個R工作進程��。 但在實際使用中��,我們通常會使用和硬件計算資源相同數目的計算組�����,即每個R工作進程可以被單獨映射到一個計算內核�����。如果計算群組的數目多于現有硬件資源�����,那么多個R工作進程將會共享現有的硬件資源��。如下例我們先用detectCores確定當前電腦中的內核數目�。值得注意的是detectCores的默認返回數目是超線程數目而非真正物理內核的數目�����。例如在我的筆記本電腦上有2個物理核心�,而每個物理核心可以模擬兩個超線程���,所以detectCores()的返回值是4���。 對于很多計算密集型任務來說���,超線程對性能沒有太大的幫助���,所以使用logical=FALSE參數來獲得實際物理內核的數目并創建一個相同數目的計算組�����。由于計算組中的進程是全新的R進程�����,所以在父進程中的數據和函數對子進程來說并不可見��。因此���,我們需要利用clusterExport把計算所需的數據和函數廣播給計算組里的所有進程��。最后parLapply將計算平均分配給計算組里的所有R進程����,然后收集合并結果���。
#Cluster on Windows
cores <- detectCores(logical = FALSE)
cl <- makeCluster(cores)
clusterExport(cl, c('solve.quad.eq', 'a', 'b', 'c'))
system.time(
res1.p <- parLapply(cl, 1:len, function(x) { solve.quad.eq(a[x], b[x], c[x]) })
)
stopCluster(cl)
for實現方式: for循環的計算和*apply形式基本類似��。在如下的串行實現中�,我們提前創建了矩陣用來保存計算結果���,for循環內部只需要逐一賦值即可�����。
# serial code
res2.s <- matrix(0, nrow=len, ncol = 2)
system.time(
for(i in 1:len) {
res2.s[i,] <- solve.quad.eq(a[i], b[i], c[i])
}
)
對于for循環的并行化�����,我們可以使用foreach包里的%dopar% 操作將計算分配到多個計算核心�����。foreach包提供了一個軟件層的數據映射方法�����,但不包括計算組的建立�����。因此�,我們需要doParallel或者doMC包來創建計算組��。計算組的創建和之前基本一樣����,當計算組建立之后�����,我們需要使用registerDoParallel來設定foreach后端的計算方式���。這里我們從數據分配方式入手��,我們希望給每個R工作進程分配一段連續的計算任務���,即將1:len的數據均勻分配給每個R工作進程����。假設我們有兩個工作進程���,那么進程1處理1到len/2的數據�,進程2處理len/2+1到len的數據���。所以在下面的程序中��,我們將向量均勻分配到了計算組���,每個進程計算chunk.size大小的聯系任務�����。并且在進程內創建了矩陣來保存結果�����,最終foreach函數根據.combine指的的rbind函數將結果合并�����。
# foreach
library(foreach)
library(doParallel)
# Real physical cores in the computer
cores <- detectCores(logical=F)
cl <- makeCluster(cores)
registerDoParallel(cl, cores=cores)
# split data by ourselves
chunk.size <- len/cores
system.time(
res2.p <- foreach(i=1:cores, .combine='rbind') %dopar%
{ # local data for results
res <- matrix(0, nrow=chunk.size, ncol=2)
for(x in ((i-1)*chunk.size+1):(i*chunk.size)) {
res[x - (i-1)*chunk.size,] <- solve.quad.eq(a[x], b[x], c[x])
}
# return local results
res
}
)
stopImplicitCluster()
stopCluster(cl)
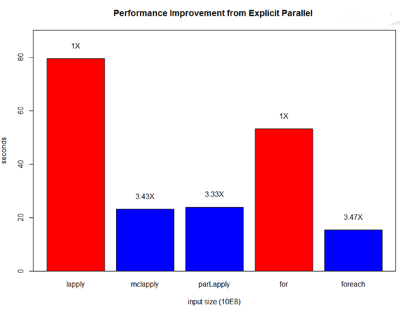
最后��,我們在Linux平臺下使用4個線程進行測試��,以上幾個版本的并行實現均可達到3倍以上的加速比���。
R并行化的挑戰與展望
挑戰:
在實際中��,并行計算的問題并沒有這么簡單�����。要并行化R以及整個生態環境的挑戰仍然巨大��。
1�、R是一個分散的��,非商業化的軟件
R并不是由一個緊湊的組織或者公司開發的�,其大部分包是由用戶自己開發的�。這就意味著很難在軟件架構和設計上來統一調整和部署�����。一些商業軟件����,比如Matlab����,它的管理維護開發就很統一�,架構的調整和局部重構相對要容易一些�����。通過幾個版本的迭代�����,軟件整體并行化的程度就要高很多�。
2�����、R的底層設計仍是單線程����,上層應用包依賴性很強
R最初是以單線程模式來設計的�����,意味著許多基礎數據結構并不是線程安全的�。所以���,在上層并行算法實現時���,很多數據結構需要重寫或者調整�����,這也將破壞R本來的一些設計模式��。另一方面����,在R中����,包的依賴性很強�,我們假設使用B包����,B包調用了A包����。如果B包首先實現了多線程��,但是在一段時間之后A包也做了并行化�����。那么這時候就很有可能出現混合并行的情況���,程序就非常有可能出現各種奇怪的錯誤(BUG)�,性能也會大幅度降低��。
展望:
未來 R并行化的主要模式是什么樣的���?以下純屬虛構�,如果有雷同完全是巧合�。
1����、R將會更多的依賴于商業化以及研究機構提供的高性能組件
比如H2O�����,MXNet��,Intel DAAL��,這些包都很大程度的利用了并行性帶來的效率提升��,而且有相關人員長期更新和調優�����。從本質上來說��,軟件的發展是離不開人力和資金的投入的�����。
2�����、云計算平臺
隨著云計算的興起�����,數據分析即服務(DAAS:Data Analyst as a Services)以及機器學習即服務(MLAS: machine learning as a services)的浪潮將會到來���。 各大服務商從底層的硬件部署�����,數據庫優化到上次的算法優化都提供了相應的并行化措施����,比如微軟近期推出了一系列R在云上的產品�,更多信息請參見這篇文章�。因此��,未來更多的并行化工作將會對用戶透明���,R用戶看到的還是原來的R�����,然而真正的計算已經分布到云端了�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
