數據挖掘實戰:PCA算法
為什么要進行數據降維�����?因為實際情況中我們的訓練數據會存在特征過多或者是特征累贅的問題���,比如:
一個關于汽車的樣本數據�,一個特征是”km/h的最大速度特征“����,另一個是”英里每小時“的最大速度特征�����,很顯然這兩個特征具有很強的相關性
拿到一個樣本����,特征非常多��,樣本缺很少���,這樣的數據用回歸去你和將非常困難����,很容易導致過度擬合
PCA算法就是用來解決這種問題的��,其核心思想就是將 n 維特征映射到 k 維上(k < n)���,這="" k="" 維是全新的正交特征�。我們將這="" k="" 維成為主元���,是重新構造出來的="" k="" 維特征���,而不是簡單地從="" n="" 維特征中取出其余="" n-k="">
PCA 的計算過程
假設我們得到 2 維數據如下:

其中行代表樣例���,列代表特征���,這里有10個樣例����,每個樣例有2個特征����,我們假設這兩個特征是具有較強的相關性�����,需要我們對其進行降維的���。
第一步:分別求 x 和 y 的平均值�����,然后對所有的樣例都減去對應的均值
這里求得 x 的均值為 1.81 �, y 的均值為 1.91�,減去均值后得到數據如下:
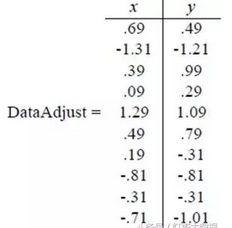
注意�����,此時我們一般應該在對特征進行方差歸一化����,目的是讓每個特征的權重都一樣�,但是由于我們的數據的值都比較接近�,所以歸一化這步可以忽略不做
第一步的算法步驟如下:

第四步:將特征值從大到小進行排序�����,選擇其中最大的 k 個��,然后將其對應的 k 個特征向量分別作為列向量組成特征矩陣
這里的特征值只有兩個�,我們選擇最大的那個��,為: 1.28402771 ����,其對應的特征向量為:

注意:matlab 的 eig 函數求解協方差矩陣的時候���,返回的特征值是一個特征值分布在對角線的對角矩陣�,第 i 個特征值對應于第 i 列的特征向量
第五步: 將樣本點投影到選取的特征向量上
假設樣本列數為 m �����,特征數為 n ���,減去均值后的樣本矩陣為 DataAdjust(m*n),協方差矩陣為 n*n ,選取 k 個特征向量組成后的矩陣為 EigenVectors(n*k)�,則投影后的數據 FinalData 為:
FinalData (m*k) = DataAdjust(m*n) X EigenVectors(n*k)
得到的結果是:
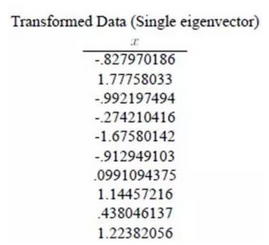
這樣�,我們就將 n 維特征降成了 k 維��,這 k 維就是原始特征在 k 維上的投影����。
整個PCA的過程貌似很簡單���,就是求協方差的特征值和特征向量�,然后做數據轉換����。但為什么協方差的特征向量就是最理想的 k 維向量����?這個問題由PCA的理論基礎來解釋��。
PCA 的理論基礎
關于為什么協方差的特征向量就是 k 維理想特征��,有3個理論����,分別是:
-
最大方差理論
-
最小錯誤理論
-
坐標軸相關度理論
這里簡單描述下最大方差理論:
最大方差理論
信號處理中認為信號具有較大的方差���,噪聲有較小的方差����,信噪比就是信號與噪聲的方差比�����,越大越好���。因此我們認為�����,最好的 k 為特征既是將 n 維樣本點轉換為 k 維后��,每一維上的樣本方差都很大
PCA 處理圖解如下:
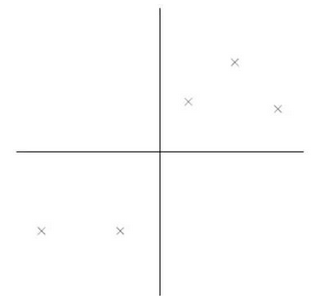
降維轉換后:

上圖中的直線就是我們選取的特征向量����,上面實例中PCA的過程就是將空間的2維的點投影到直線上�。
那么問題來了�����,兩幅圖都是PCA的結果����,哪一幅圖比較好呢�����?
根據最大方差理論�����,答案是左邊的圖����,其實也就是樣本投影后間隔較大���,容易區分���。
其實從另一個角度看���,左邊的圖每個點直線上的距離絕對值之和比右邊的每個點到直線距離絕對值之和小���,是不是有點曲線回歸的感覺����?其實從這個角度看���,這就是最小誤差理論:選擇投影后誤差最小的直線����。
再回到上面的左圖�����,也就是我們要求的最佳的 u �����,前面說了��,最佳的 u 也就是最佳的曲線����,它能夠使投影后的樣本方差最大或者是誤差最小���。
另外����,由于我們前面PCA算法第一步的時候已經執行對樣本數據的每一維求均值��,并讓每個數據減去均值的預處理了��,所以每個特征現在的均值都為0�����,投影到特征向量上后�����,均值也為0.因此方差為:


最佳投影直線就是特征值 λ 最大是對應的特征向量���,其次是 λ 第二大對應的特征向量(求解的到的特征向量都是正交的)����。其中 λ 就是我們的方差����,也對應了我們前面的最大方差理論���,也就是找到能夠使投影后方差最大的直線�����。
Python實現
1.代碼實現
偽代碼如下(摘自機器學習實戰):

2.代碼下載
下載地址: https://github.com/jimenbian/PCA
loadDataSet函數是導入數據集���。
PCA輸入參數:參數一是輸入的數據集�,參數二是提取的維度��。比如參數二設為1���,那么就是返回了降到一維的矩陣����。
PCA返回參數:參數一指的是返回的低維矩陣���,對應于輸入參數二�����。參數二對應的是移動坐標軸后的矩陣����。
上一張圖����,綠色為原始數據����,紅色是提取的2維特征�����。

Matlab 實現
|
function [lowData,reconMat] = PCA(data,K)[row , col] = size(data);meanValue = mean(data);%varData = var(data,1,1);normData = data - repmat(meanValue,[row,1]);covMat = cov(normData(:,1),normData(:,2));%求取協方差矩陣[eigVect,eigVal] = eig(covMat);%求取特征值和特征向量[sortMat, sortIX] = sort(eigVal,'descend');[B,IX] = sort(sortMat(1,:),'descend');len = min(K,length(IX));eigVect(:,IX(1:1:len));lowData = normData * eigVect(:,IX(1:1:len));reconMat = (lowData * eigVect(:,IX(1:1:len))') + repmat(meanValue,[row,1]); % 將降維后的數據轉換到新空間end
|
調用方式
|
function testPCA%%clcclearclose all%%filename = 'testSet.txt';K = 1;data = load(filename);[lowData,reconMat] = PCA(data,K);figurescatter(data(:,1),data(:,2),5,'r')hold onscatter(reconMat(:,1),reconMat(:,2),5)hold offend
|
效果圖

CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
