數據分析?這么簡單的描述性統計先學了好嗎
用戶研究中數據分析的目的��,常見有三種:
歸納分析�����、差異分析��、關聯分析
今天我們聊一下����,在以歸納分析為目的的數據分析中���,集中趨勢和離散趨勢怎么玩�,形狀測量將在《Part.5: 不用的數據類型對應的視覺化呈現》中一并聊��。
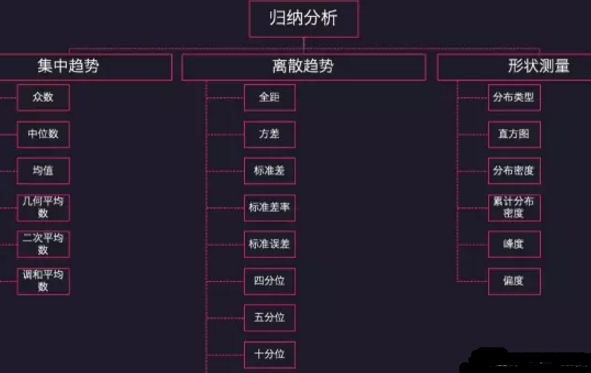
如上圖����,歸納分析中對集中趨勢和離散趨勢的描述我們統稱為描述性統計����,這是統計分析中最基礎的概念���,也是日常的數據分析如問卷調研中用得最多的統計方法��。本文中會另外聊到一個事情����,就是在分析好集中趨勢和離散趨勢后����,還需要判斷這個結果在多大程度上可以相信�����,也就是置信區間的玩法��。
集中趨勢
集中趨勢可以簡單地理解成用單個數值來代表一組數據�����。最常見的三種集中趨勢指標是平均數(mean)����、中位數(median)和眾數(mode)�����。
a.平均數
平均數大家都很熟悉�����,用戶的平均年齡�、平時在線時長����、平均客單價等等���,他是拿到用戶數據后第一件要做的事情�。大多數用戶體驗度量的平均值都能提供非常有用的信息���,比如新版本上線后采用5分或7分量表獲取用戶的體驗滿意度�����,最簡單的方法就是根據采集的數據計算出平均值����,將平均值作為用戶滿意度結果進行報告�����。這份滿意度報告展示的第一個數據就已經呈現了�,讀者對該次版本的滿意度就有了初步的印象�。
b.中位數(中數)
中位數��,顧名思義��,就是將數據從小到大或從大到小進行排序排序�,然后取中間的數字作為這一列數據的中位數��。如果正好樣本量是偶數�,那么就平均一下中間的兩個數據得到中位數���。
什么時候該用中位數而不是平均數來表示呢����?如下表�,一項可用性研究中12名參加者完成某任務的時間(秒)�。
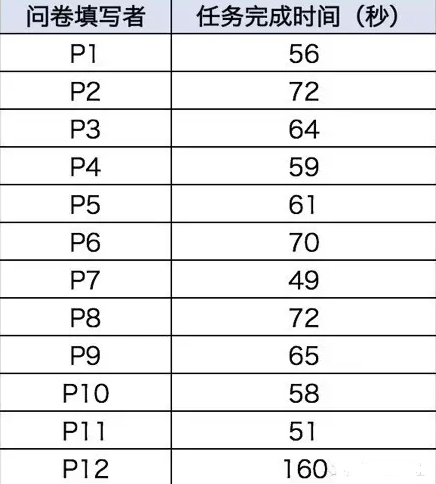
上圖這組數據中�,第12位參與者大大拉高了平均值�,但是中位數不受其影響����。所以一般情況下存在某些數據偏差太大的情況����,中位數比平均數更適用����。
c.眾數
能用字面意思理解的概念都是好概念��,眾數也同樣可以從字面理解�,就是出現次數最多的那個數值��。如1����、2����、2��、3���、6這組數據的眾數為2�。眾數的使用場景比較少���,但當一組數據包含的數值范圍很?����。ㄈ?-3分的主觀評價量表����,滿意��、一般����、不滿意)時��,眾數會更有價值�。
一般收集到用戶數據后���,我們錄入和分析工具使用最多的是excel和spss����,數據量未超過一萬條(樣本量未超1萬)可以直接在excel中進行計算�����,超過一萬條后excel的處理速度會變慢����,可以考慮spss或其他統計軟件���。
[excel 計算方法]
(1)平均數:可以用“=AVERAGE”函數計算
(2)中數:可以用“=MEDIAN”函數計算
(3)眾數:可以用“=MODE”函數計算
離散趨勢
實例:
新版本上線后針對操作簡便性與賬戶安全性兩個維度進行滿意度的問卷調研?���,F選取10名核心用戶分別在兩個維度上進行滿意度評分�����,結果如下表���。
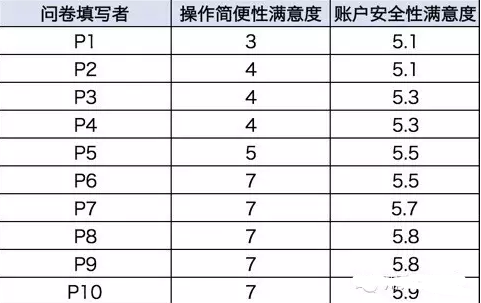
如上表��,兩組得分數據平均值均為5.5���,但是操作簡便性維度上�����,10名用戶間的差異很大����,而賬戶安全性維度上10名用戶的差異很小����。也就是說�,在操作簡便性上��,其實只有一半用戶表示最為滿意��,但另一半用戶認為一般及不滿意��;在賬戶安全性維度上�,所有用戶都較滿意�,評價較統一���。
平均數相同的兩個維度����,其實樣本間差異非常大��,這時候如果只用平均數來表示這次調研的整體表現�����,結果就會對讀者產生誤導��,因為樣本間的差異過大時將平均數作為產品的評判和改進依據是沒有意義的����,應該從離散的數據中找到數據背后的疑問點進行深入了解����。
如果發現了樣本背景有差異�,則應該進一步分析�,比如按照不同樣本背景將用戶進行分組�,驗證是否的確由于這個原因引起了整體數據的離散���,然后再通過其他質性的方式深入了解樣本背景與其數據表現的相關性或因果性����。
從上面的事例中��,我們發現:除了需要報告數據的集中趨勢�,數據的離散趨勢即變異性也是必不可少的���。
變異性描述統計顯示的是數據的分散或離散程度��。如上表中�����,不同用戶對操作簡便性滿意度的評分差異很大�,也就是說數據離散程度高�����、集中趨勢低�;不同用戶對賬戶安全性滿意度的評分差異較小����,也就是說數據離散程度低���、集中趨勢高����。
在實際的數據統計中��,在99.9%的情況下�,我們都無法像上述例子那樣直接用肉眼判斷數據的離散程度��,需要借助幾個數據指標來判斷�。表示離散趨勢的常見指標為全距(range)��、方差(variance)和標準差(standard deviation)�。
a.全距
全距就是一組數據中最大值和最小值之間的距離�����。計算最大值和最小值的差距即發現極端值����,所以查看全距大小是初步檢驗數據離散趨勢的一個最快捷方法�。
b.方差
方差說明的是一組數據中每個數據與平均數的離散程度�����。具體公式在此就不細述����,因為感謝強大的excel公式�,足以幫我們從繁復的公式中解放出來�����。具體操作詳見下文[excel計算方法]部分����。
c.標準差
標準差其實就是開方后的方差�。標準差的原理和方差的原理是一樣的�����,只是將方差開方后��,它的單位與原始數據單位就一致了����,所以業內普遍用標準差反映數據的離散程度��。標準差越大就說明每個數據與平均值的差異很大����,能夠證明這組數據之間差異很大(離散程度高)��。
[excel計算方法]
(1)全距:用“=MIN”函數得到最小值����;用“=MAX”函數得到最大值��;MAX-MIN得到的就是全距
(2)方差:用“=VAR”函數就可以得出方差
(3)標準差:用“=STAEV”函數就能得出標準差
置信區間
上述滿意度的問卷中�����,考慮到成本和時間等各方面因素�����,只能搜集到200份有效問卷��,如果老板對于得出的數據結果有質疑:200份夠嗎��?可以代表總體的實際評分嗎�?這時候就可以瀟灑地甩一個置信區間給他(老板我這么說你是不會介意 對嗎�,看了這里不要扣我績效)���。
置信區間是對總體樣本實際平均值的估計����。一般情況下是先自己設置好置信區間���,再算出這個置信區間下真實的平均數范圍是什么樣����。
如置信區間是95%���,說明你得出的“真實的平均數范圍”這一結論它的可信度在95%�,相應的錯誤概率(也就是α系數�����,α系數在計算操作的時候會用到)就是5%�����。
我們通常選用的置信區間有99%��、95%和90%��。如果你需要估值的置信區間有更大的把握�����,就選擇99%的置信區間�����;如果對需要估值的置信區間不是很有把握�,就選擇90%的置信區間�����。
實例:
如果我們需要根據上述10名用戶對賬戶安全性的滿意度評分來估計總樣本的實際滿意度����,我們不可能讓所有用戶都來填寫問卷���,但是你可以根據獲得的10份樣本估計滿意度可能的范圍(這里只是用虛擬的數據舉例�����,實際的問卷調研樣本數量要求會根據具體情況而定)��。
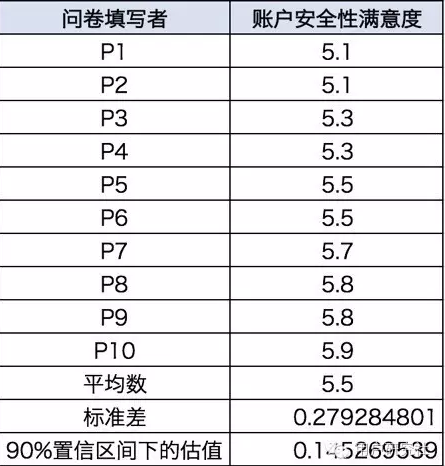
在上表中��,得到平均數為5.5���,90%置信區間下的估值結果為0.15(0.145269539���,取小數點后兩位)����,所以可以將結果表述為這個平均數的90%置信區間是5.5±0.15����。也就是說��,你有90%的把握判斷出所有用戶對賬戶安全性的滿意度在5.35至5.65之間(置信區間非常有用�,可以當作匯報平均值的常規項)���。數據分析培訓
[excel計算方法]
在excel中用“CONFIDENCE”函數“=CONFIDENCE(α系數�����、標準差���、樣本量)”就能快速計算置信區間�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
