數值變量正態性檢驗常用方法的對比及SPSS&R實現
一�、方法概述
正態分布又叫高斯分布����,“正態”即“正常的狀態”�,本意是說如果在觀察或試驗中不出現重大的失誤���,則結果應遵循這種模式的分布——盡管隨著人們實踐經驗的積累發現事實并非如此���。正態分布之所以得到普遍重視���,除了它可以用來刻畫數值變量的分布特征外�����,另一個重要原因要歸功于Fisher及其同時代的若干杰出學者�����。他們對正態總體下一系列重要的統計量建立了形式簡約且在計算上可行的小樣本理論��,為統計推斷提供了極大的方便���,而在非正態的情況下則沒有可比擬的結果[1,2]�����?����;诖?��,人們在實際統計分析時�,總是樂于采用正態假定�。人們在對一個數值變量進行分析之前�����,可以參照既往基于大樣本所推測的變量分布形式����,確定正態性假定的合理性����。然而�,有時既往文獻中沒有基于大樣本的變量分布形式定論����,致使研究者對正態性假定是否合理無充分的把握�。這時就需要使用實際的觀測數據�,實施正態性檢驗����。
二����、軟件實現
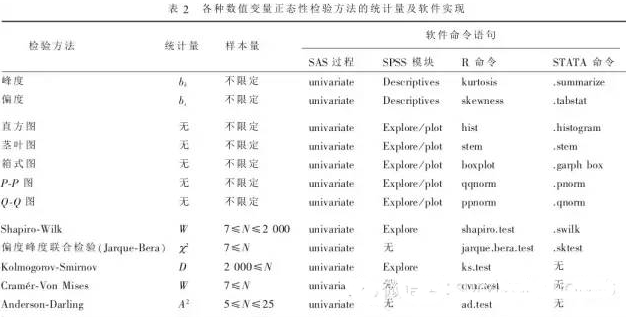
統計分析包括統計描述和統計推斷[1]�,正態性的分析主要包括統計圖繪制��,及統計指標的計算與檢驗兩種方法����。利用統計圖可以直觀地呈現變量的分布��,同時還可以呈現出經驗分布和理論分布的差距�����。峰度���、偏度就是兩個常用的正態性描述統計指標��,通過構建檢驗統計量還能實現正態性檢驗��,Shapiro-Wilk檢驗����、Kolmogorov-Smirnov���、偏度峰度聯合檢驗(Jarque–Bera檢驗)���、GramerVon-Mises檢驗等均是通過構建檢驗統計量對樣本進行正態性檢驗��。具體見表1��。

如表1所示�����,直方圖���、莖葉圖和箱式圖為主觀的基于統計圖的正態性描述方法���,而統計描述指標峰度檢驗和偏度檢驗可以被認為是一種客觀的數值計算的正態性檢驗方法�?��;诮y計推斷的概率圖����、P-P圖�、Q-Q圖為客觀的圖表判斷的正態性檢驗方法����,而基于數值計算的常用的統計軟件��,如SAS��,SPSS,R,STATA均有相關命令或者過程步基于樣本數據對總體的正態性進行檢驗��,表2給出了常見的四種統計軟件實現上述正態性檢驗方法的命令語句�����,以及各種方法使用過程中對樣本量的要求�。
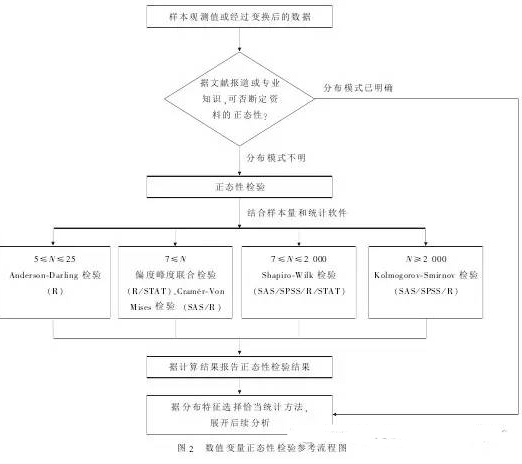
三���、方法選擇流程圖
下圖是正態性檢驗的方法選擇的流程圖���,大家可根據樣本數據情況選擇不同的方法��。
四���、SPSS中正態性檢驗操作演示
下面我們來看一組數據��,并檢驗“期初平均分” 數據是否呈正態分布(此數據已在SPSS里輸入好):

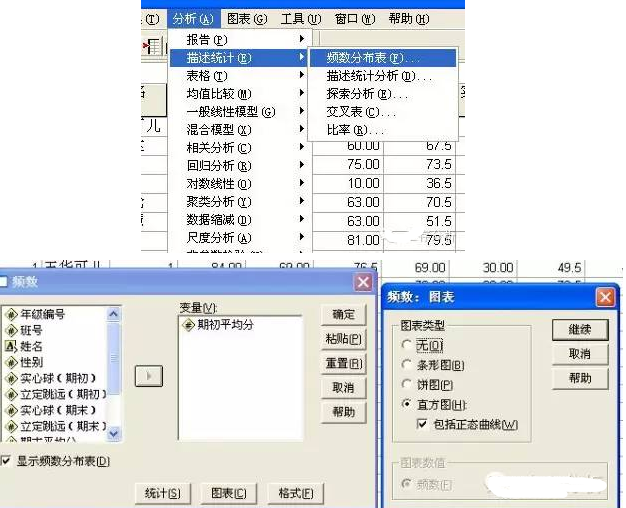
在SPSS里執行“分析—>描述統計—>頻數統計表”(菜單見下圖�����,英文版的可以找到相應位置)�����,然后彈出左邊的對話框�����,變量選擇左邊的“期初平均分”���,再點下面的“圖表”按鈕���,彈出圖中右邊的對話框�,選擇“直方圖”��,并選中“包括正態曲線”�����。
設置完后點“確定”�����,就后會出來一系列結果����,包括2個表格和一個圖��,我們先來看看最下面的圖�����,見下圖�����,
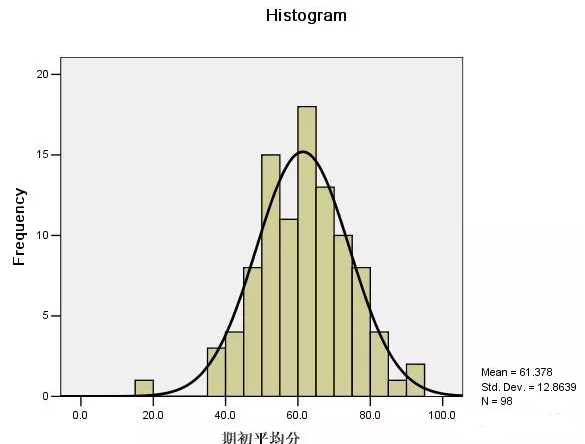
上圖中橫坐標為期初平均分���,縱坐標為分數出現的頻數����。從圖中可以看出根據直方圖繪出的曲線是很像正態分布曲線���。如何證明這些數據符合正態分布呢���,光看曲線還不夠�,還需要檢驗:
檢驗方法一:看偏度系數和峰度系數
我們把SPSS結果最上面的一個表格拿出來看看(見下圖):

偏度系數Skewness=-0.333;峰度系數Kurtosis=0.886���;兩個系數都小于1�����,可認為近似于正態分布����。
檢驗方法二:單個樣本K-S檢驗
在SPSS里執行“分析—>非參數檢驗—>單個樣本K-S檢驗��,彈出對話框���,檢驗變量選擇“期初平均分”�,檢驗分布選擇“正態分布”����,然后點“確定”����。
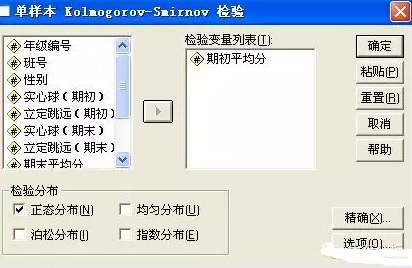
檢驗結果為:

從結果可以看出�,K-S檢驗中,Z值為0.493��,P值(sig
2-tailed)=0.968>0.05���,因此數據呈近似正態分布
檢驗方法三:Q-Q圖檢驗
在SPSS里執行“圖表—>Q-Q圖”���,彈出對話框�,見下圖:

變量選擇“期初平均分”�,檢驗分布選擇“正態”��,其他選擇默認���,然后點“確定”����,最后可以得到Q-Q圖檢驗結果�����,結果很多��,我們只需要看最后一個圖�����,見下圖��。
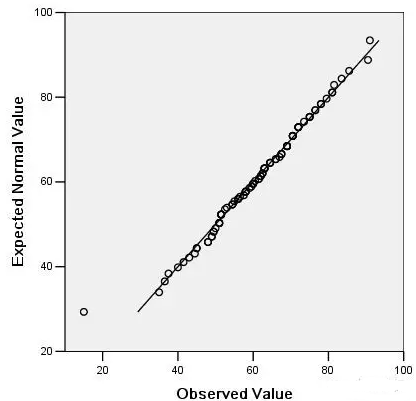
QQ Plot中�����,各點近似圍繞著直線����,說明數據呈近似正態分布�。
五�、R:正態性檢驗
(1)QQ概率圖
功能和原理:檢驗樣本的概率分布是否服從某種理論分布��。PP概率圖的原理是檢驗實際累積概率分布與理論累積概率分布是否吻合��,若吻合���,則散點應圍繞
在一條直線周圍��,或者實際概率與理論概率之差分布在對稱于以0為水平軸的帶內���。QQ概率圖的原理是檢驗實際分位數與理論分位數之差分布是否吻合����,若吻合��,則散點應圍繞在一條直線周圍�,或者實際分位數與理論分位數之差分布在對稱于以0為水平軸的帶內����。QQ概率圖以樣本的分位數為橫軸���,以指定理論分布的分位數為縱軸繪制散點圖����。
> library(DAAG)
> data(possum)
> attach(possum)
The following object(s) are masked from 'possum (position 12)':
age, belly, case, chest, earconch, eye, footlgth, hdlngth, Pop,
sex, site, skullw, taill, totlngth
> fpossum <- possum[possum$sex=="f",]
> mean = mean(totlngth)
> sd = sd(totlngth)
> x <- sort(totlngth)
> n <- length(x)
> y <- (1:n)/n
>
> plot(x,y,
+ type = 's',
+ main = "Empirical CDF of ")
> curve(pnorm(x, mean, sd),
+ col = 'red',
+ lwd = 2,
+ add = T)
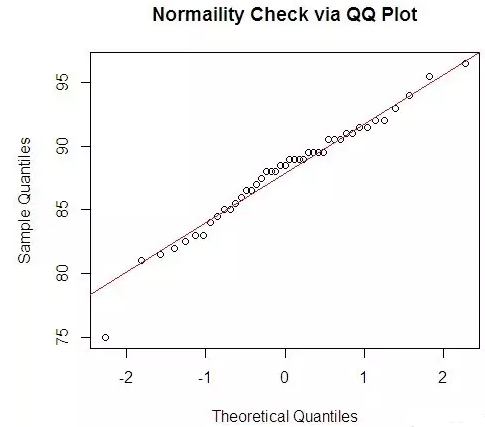
圖形表示����,數據與正態性略有差異�,特別是中部區域�����。
(2)與正態密度函數直接比較
> library(DAAG)
> data(possum)
> attach(possum)
The following object(s) are masked from 'possum (position 13)':
age, belly, case, chest, earconch, eye, footlgth, hdlngth, Pop,
sex, site, skullw, taill, totlngth
> fpossum <- possum[possum$sex=="f",]
> dens <- density(totlngth)
> xlim <- range(dens$x)
> ylim <- range(dens$y)
> mean = mean(totlngth)
> sd = sd(totlngth)
> par(mfrow=c(1,2))
>
> hist(totlngth,
+ breaks=72.5+(0:5)*5,
+ xlim = xlim ,
+ ylim = ylim ,
+ probability = T ,
+ xlab = "total length",
+ main = "A:Breaks at 72.5...")
> lines(dens,
+ col = par('fg'),
+ lty = 2)
> curve( dnorm(x, mean, sd),
+ col = 'red',
+ add = T)
>
> hist(totlngth,
+ breaks = 75 + (0:5) * 5 ,
+ xlim = xlim,
+ ylim = ylim,
+ probability = T,
+ xlab="total length",
+ main = "B:Breaks at 75")
> lines(dens,
+ col = par('fg'),
+ lty = 2)
> curve(dnorm(x,mean,sd),
+ col = 'red',
+ add = T)
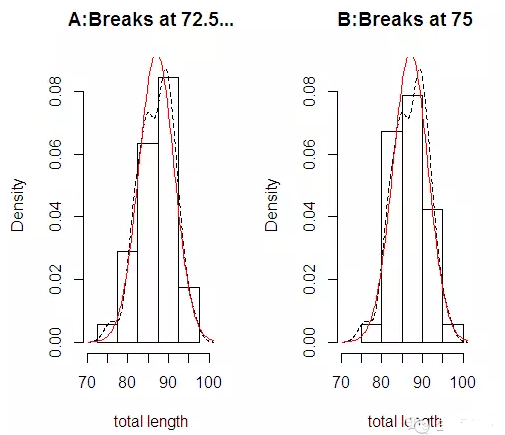
看圖直接看和正態密度函數的差異度��。
(3)使用經驗分布函數�����,直接比較數據的經驗分布函數和正態分布的分布函數對比�。
> library(DAAG)
> data(possum)
> attach(possum)
The following object(s) are masked from 'possum (position 14)':
age, belly, case, chest, earconch, eye, footlgth, hdlngth, Pop,
sex, site, skullw, taill, totlngth
> fpossum <- possum[possum$sex=="f",]
> mean = mean(totlngth)
> sd = sd(totlngth)
> x <- sort(totlngth)
> n <- length(x)
> y <- (1:n)/n
>
> plot(x,y,
+ type = 's',
+ main = "Empirical CDF of ")
> curve(pnorm(x, mean, sd),
+ col = 'red',
+ lwd = 2,
+ add = T)
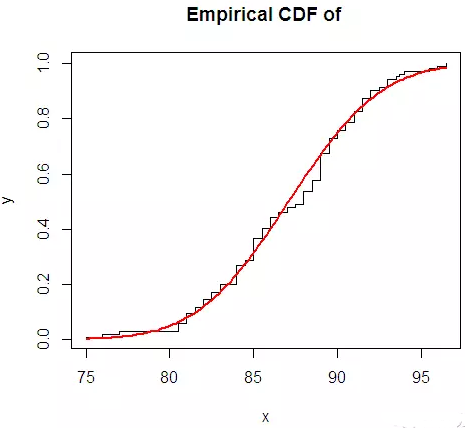
總體來說����,數據并不完全服從正態分布��,需要做進一步檢驗��,看和正態分布的差距多大���,是否在接受范圍之內��?
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
