讀書筆記 | 大數據時代
大數據這個概念在最近這幾年很火�����,大家也大概知道大數據到底是個什么東西�,它是如何運作的?���,F在好多產品上面都會有“猜你喜歡”這一功能���,這就是利用大數據實現的����。我們每天都在利用大數據或被大數據利用�,但是我們當中應該沒有多少人真正知道大數據時代給我們帶來什么改變�。這本書主要從大數據帶來的思維變革�����、商業變革��、管理變革三個方面來寫�。我主要會把這本書中的思維變革和商業變革寫出來(因管理變革目前我們中大部分人還用不到��,所以就先不寫)����,本篇寫思維變革�����、商業變革下篇連載��。
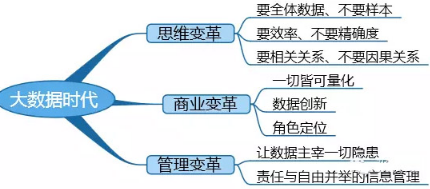
本書框架圖
思維變革
1.要全體數據����、不要樣本
在信息處理能力受限的年代����,世界需要數據分析����,卻缺少用來分析所收集數據的工具����,所以只能用隨機抽樣的方式進行數據分析�。
但是真正的大數據時代是指不用隨機分析法這樣的捷徑��,而采用所有數據的分析方法�。通過觀察所有數據��,來尋找異常值進行分析����。
比如:信用卡詐騙是通過異常情況來識別的�����,只有掌握了所有數據才能做到這一點����,在這種情況下�,異常值是最有用的信息�����,你可以把他與正常交易情況作對比從而發現問題�。
2.要效率�����、不要精確性
在如今的信息時代�。我們掌握的數據庫越來越全面�,她不再只包括我們手頭那一點可憐的數據�����,而是包括了與這些現象相關的大量甚至全部的數據��。數據量的大幅增加會造成結果的不準確��,與此同時��,一些錯誤的數據也會混進數據庫���。但是正因為我們掌握了幾乎所有的數據���,所以我們不再擔心某個數據點對整套分析的不利影響��。我們要做的就是要接受這些紛繁的數據并從中受益��,而不是以高昂的代價消除所有的不確定性���。這就是由“小數據”到“大數據”的改變�����。
有時候當我們掌握了大量新型數據時���,精確性就不那么重要了�,我們同樣可以掌握食物的發展趨勢�����,大數據不僅讓我們不再期待準確性�����,也讓我們無法實現準確性���。
值得注意的是����,錯誤并不是大數據本身固有的����。他只是我們用來衡量�����、記錄和交流數據的工具的一個缺陷���。如果說哪一天技術完美無缺了�����,不精確度的問題就不復存在了���。錯誤不是大數據固有的特性�,而是一個需要我們去處理的實際問題�����,并且可能長期存在����。
混雜性不是竭力避免���,有的時候可以為我們所用����?�;ヂ摼W最火的產品都會表明���,不精確性��、混雜性要更好點����。
比如微信朋友圈:朋友的發動態時間���,在一小時之內的會顯示多少分鐘之前�,在一小時以外的就只顯示幾小時前����。
在微信公眾號閱讀量顯示�,為什么超過十萬以后顯示地是100000+���,而不是具體數據�����,因為超過十萬以后的數據��,我們心中或許就沒啥概念了���,沒有一個參考衡量的標準了����,十萬已經會讓我們覺得這篇文章很厲害了�,能達到目的���,就沒必要精確���。
3.要相關關系���、不要因果關系
知道是很什么就夠了���,沒必要知道為什么�。在大數據時代�����,我們不必非得知道現象背后的原因�����,而是要讓數據自己發聲��。
比如:知道用戶對什么感興趣即可��,沒必要去研究用戶為什么感興趣�。
相關關系的核心是量化兩個數據值之間的數據關系���。相關關系強是指當一個數據值增加時�,其他數據值很有可能也會隨之增加�����。
相關關系是通過識別關聯物來幫助我們分析某一現象���,而不是揭示其內部的運作��。
注意:即使很強的相關關系也不一定能揭示每一種情況����,比如兩個事物看上去行為相似��,很有可能只是巧合�����。相關關系沒有絕對���,只有相似����。
通過給我們找到一個現象良好的關聯物�,相關關系可以幫助我們捕捉現在和預測未來��。
比如:如果A和B經常一起發生����,我們只需要注意到B發生了��,就可以預測A也發生了��。
在小數據時代�,數據分析專家會使用一些建立在理論基礎上的假想來指導自己選擇適當的關聯物����。然后收集與關聯物相關的數據來進行分析���,以證明假設是否正確�����。但是由于這是建立在假設的基礎上��,那么分析結果也是有受偏見影響的可能�。
在大數據時代�����,我們擁有如此多的數據�����,如此好的計算機能力�,所以不再需要人工選擇一個關聯物或者一小部分相似數據來逐一分析�����。通過去探求“是什么”而不是“為什么”����,相關關系幫助我們更好的了解這個世界����。
商業變革
1.數據化—量化一切
首先我們需要明確兩個概念就是數字化和數據化
數據化��、是指一種把現象轉變為可制表分析的量化形式的過程��。
數字化��、是指把模擬數據轉換成0和1表示的二進制碼��。
計算機的出現帶來了數字測量和存儲設備��,數字化帶來了數據化���,但是數字化無法取代數據化��。
數據化的核心是量化一切��,常見的被量化的有文字���、方位和溝通��。
當文字變成圖書����,拿電子書為例��,未數據化的電子書只能夠被展示出來�,讀者并不能通過搜索關鍵詞被查找到��,也不能被分析����。
當方位變成數據���,就是將地理信息進行��,比如百度地圖�����、各種網站的獲取位置都是將方位變成數據��。
當溝通變成數據��,一些社交平臺通過添加各種心情表情���,來收集我們的心情狀態��,還有人們的喜好�,年齡什么的都可以變成數據�����。
2.價值—數據創新
不同于物質性的東西�����,數據的價值不會隨著它的使用而減少����。數據就像一個神奇的磚石礦����,當他的首要價值被發掘后仍能不斷給予����。它的真實價值就像漂浮在海洋中的冰山�,第一眼只能看到冰山的一角�����,而絕大部分隱藏在表面之下�����。他可以為了同一目標被多次使用���,也用于其他目的��。這就需要我們選擇性的對數據進行創新�����,下面主要介紹幾點數據創新
數據再利用
就是數據在實現了基本用途以后的進一步利用��。
比如搜索關鍵詞�����,基本用途是可以通過消費搜索關鍵詞來定向推送廣告����,就是我們在淘寶里面搜索關鍵詞以后����,會收到猜你喜歡的物品提醒�����。
而他的再利用:根據客戶搜索關鍵詞的流量��,來判斷哪款產品或哪種顏色會成為爆款��。
重組數據
有的時候可能從某一組數據上看不出什么價值��,我們需要把他和其他數據進行組合以后��,才能利用其價值��。
比如����,美國房地產網站Zillow.com將房地產信息和價格添加在美國社區地圖上��,同時還壓縮了大量的信息����,如社區近期的交易和物業價格����,以此來預測區域內具體每套住宅的價值�����。
可擴展數據
促成數據再利用的方法之一是從一開始就設計它的可擴展性��。收集多個數據流或每個數據流中更多數據點的額外成本往往較低�����,因此����,收集盡可能多的數據并在一開始的時候就考慮到其各種潛在的二次用途����,使其具有擴展性是非常有意義的��。
比如:超市的攝像頭在一開始的時候只是為了防止小偷���,但事實上還可以跟蹤商店的客戶流和她們停留的位置���?��?梢愿鶕@些信息來設計店面的最佳布局����。
數據的折舊值
隨著時間的推移����,可能一些比較久遠的數據就會失去其原有的價值�����,在這種情況下�,繼續依賴于舊的數據不僅不能增加價值����,實際上還會破壞新數據的價值����。
比如���,十年前你在亞馬遜上買了一本書����,而現在你已經完全對他不感興趣了��,如果亞馬遜繼續使用這個數據來向你推薦其他書籍就會有些不合理���。
數據廢氣
就是收集數據中的一些錯誤值來進行利用���。
比如:搜索引擎的輸入法���,有的時候你會發現你輸入的關鍵詞時錯誤的�,但是系統會彈出你想要的正確的結果����。這就是數據廢氣所起的作用����。搜素引擎后臺會收集每天后臺收到的錯誤關鍵詞和用戶最終查找的正確關鍵詞的內容��。這樣以后一旦出現類似的錯誤�����,系統就可以推送正確的內容給用戶��,匹配度很高�。
3.角色定位—數據�����、技術��、思維
根據所提供價值的不同來源���,分別出現了三種大數據公司�����。這三種來源是指:數據本身���、技能與思維�。
第一種是基于數據本身的公司�。這些公司擁有大量數據或至少可以收集到大量數據�����,卻不一定有從數據中提取價值或用數據催生創新思想的技能��。
第二種是基于技能的公司����。他們通常是咨詢公司���、技術創新或分析公司���。他們掌握了專業技能但并不一定擁有數據或提出數據創新性用途的才能���。
第三種是基于思維的公司����。通過利用大數據思維提出一些創新性指導意見�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
