用R語言建立學生的學習表現和性格特征數據模型
一����、項目介紹:
方法包括以下步驟
S1:將個體表現數據輸入到數據庫��;
S2:建立學習者的學習表現數據庫和性格特征數據庫�;
S3:建立學習者的學習表現數據模型和性格特征數據模型�;
S4:使用數據算法計算學習表現數據����;
S5:輸出個體性格特征��。
步驟(S1)中的個體表現數據為諸如以下類型且不局限于以下類型的個體表現:
曠課�、請假����、遲到����、早退�;
課堂紀律����、上課說話�����、上課玩手機��、上課吃東西���、上課看與學科內容無關的書����、上課期間隨意進出�、上課手機響鈴�����、上課做其他科作業�����、上課睡覺�、上課坐姿不端正�����;
課堂上搶答舉手����、表達清楚性����、觀點清晰性��、內容正確性����;
小組討論時主題明確性�����、討論氣氛活躍性���、是否組織者�����、是否積極發言����;
實驗前儀器樣品狀況確認與否�、破損儀器數量�����、破損儀器時間�、儀器破損上報情況��、儀器賠償�、儀器整理情況����、實驗完成用時長短���、實驗過程操作規范程度���、實驗過程中的紀律遵守情況��、實驗后衛生打掃情況�、原始實驗數據準確度���、原始實驗數據有無抄襲現象�、實驗報告的質量���;
預習�、作業的完成的時間點����,預習����、作業的完成的時間段�����;
預習�、作業的質量�����,預習��、作業的次數��;
作業誠信��、考試誠信���;
測驗���、考試成績��、考試用時����;
當通過設備交互答題����,使用鼠標��、鍵盤�、體感設備�、觸摸屏���、模擬設備時���;
完成的時間點的早晚�����、完成的時間段的長短�、操作的頻率的多少��、重復的頻率的多少�����、設備位移的長度長短�、設備位移的速度大小���、設備位移的精度大小�、操作的質量高低����;
當通過設備交互答題�,使用語音輸入設備時�����;
響度���、音調���、音品或音色����、語速�����。
步驟(S2)中的學習表現數據庫和性格特征數據庫具有學生通過性格測驗所獲得的性格特征數據以及通過學習系統所獲得學習數據����,這些數據都是所獲得的原始數據���。其中���,性格測驗包含卡特爾16PF人格測驗�、大五人格測驗�����,卡特爾16PF人格測驗包含16個維度的性格特征�,而大五人格測驗包含五個維度的性格特征�����。
步驟(S3)中建立學習者的學習表現數據模型和性格特征數據模型��,主要是通過學習表現與性格特征的原始數據�,通過計算其中的相關系數��,輸出學習者的新的性格特征的穩定模型��。
步驟(S4)中使用的數據數學算法為包含聚類分析算法(S41)��、關聯規則法(S42)���、回歸分析法(S43)�、BP神經網絡模型(S44)��、決策樹(S45)���、支持向量機(S46)的數據挖掘算法�����。
采用聚類分析算法(S41)將學習者的表現數據類型進行相似性比較���,將比較相似的個體性格特征歸為同一組數據庫�����,采用以下步驟:
(1)選取性格特征作為初始的聚類中心����;
(2)輸入學習者的學習表現數據和性格特征的測試結果�;
(3)計算學習表現數據類型與各個性格特征聚類中心之間的距離��,使誤差平方和局部最小��,并將距離用統一量化的手段給出����,把學習表現數據類型與性格特征之間距離小于閾值的分配給相應的性格特征聚類中心�,得到的學習表現數據與性格特征之間的分配關系與距離�;
(4)用新的數據重復(1)��、(2)�����、(3)的操作����,待相關系數穩定后�����,得到穩定的數學模型����;
(5)然后將新的學習者的學習表現數據輸入到性格特征評估系統�����,可得出新學習者的性格特征�。
采用關聯規則法(S42)將不同的性格特征關聯起來��,當個體表現出一種性格特征時�����,則可推斷其他性格特征�����,其方法為:
補充用這種方法的核心步驟
采用回歸分析法(S43)建立數學模型����,用最小二乘法估計確定同類型的學習表現數據與某些性格特征之間的定量關系式��,采用逐步回歸���、向前回歸和向后回歸方法計算某個學習表現數據與某個性格特征的相關性參數來判斷某個學習表現數據與某個性格特征之間的影響是否顯著�。
采用BP神經網絡法(S44)對所有的學習表現數據與性格特征綜合分析�,采用最速下降法�,沿距離梯度下降的方向求解極小值�,經過不斷的迭代與修正得出所有的學習表現數據與性格特征之間存在的最短距離����,最端距離代表與學習表現數據相關的性格特征����。
采用決策樹(S45)法對學習表現數據分類����,將不同類型學習表現數據更清楚地表示出來�。
采用步驟(S4)中的支持向量機(S46)算法計算出某一性格特征與其相關的學習表現數據所產生的“最短距離方式”�����,經過不斷的迭代運算�����,得出性格特征相關性較強的學習表現數據����。
有益的效果是:
使用本方法�����,性格特征評估系統可以使用新學習者的學習表現數據來評價其性格特征��,從而對學生日后的發展進行科學指導���,有利于教師把握學生的性格�。
方法包括以下步驟:S1:將個體表現數據輸入到數據庫���;S2:建立學習者的學習表現數據庫和性格特征數據庫��;S3:建立學習者的學習表現數據模型和性格特征數據模型����;S4:使用數據算法計算學習表現數據��;S5:輸出個體性格特征�����。
針對步驟S1���,步驟(S1)中的個體表現數據為諸如以下類型且不局限于以下類型的個體表現:
曠課����、請假��、遲到�����、早退�����;
課堂紀律�、上課說話�、上課玩手機����、上課吃東西����、上課看與學科內容無關的書�����、上課期間隨意進出���、上課手機響鈴���、上課做其他科作業����、上課睡覺�、上課坐姿不端正����;
課堂上搶答舉手���、表達清楚性�、觀點清晰性��、內容正確性���;
小組討論時主題明確性��、討論氣氛活躍性�����、是否組織者���、是否積極發言����;
實驗前儀器樣品狀況確認與否��、破損儀器數量����、破損儀器時間����、儀器破損上報情況��、儀器賠償�����、儀器整理情況����、實驗完成用時長短����、實驗過程操作規范程度�����、實驗過程中的紀律遵守情況���、實驗后衛生打掃情況����、原始實驗數據準確度�、原始實驗數據有無抄襲現象�、實驗報告的質量�;
預習�����、作業的完成的時間點�,預習����、作業的完成的時間段����;
預習���、作業的質量�,預習���、作業的次數���;
作業誠信����、考試誠信��;
測驗�����、考試成績��、考試用時����;
當通過設備交互答題��,使用鼠標���、鍵盤���、體感設備���、觸摸屏�、模擬設備時��;
完成的時間點的早晚��、完成的時間段的長短��、操作的頻率的多少�、重復的頻率的多少����、設備位移的長度長短��、設備位移的速度大小�、設備位移的精度大小�、操作的質量高低�;
當通過設備交互答題����,使用語音輸入設備時����;
響度���、音調�����、音品或音色�����、語速�。
針對步驟S2��,學習表現數據庫和性格特征數據庫的獲得可以通過以下方式實現:在學習開始時���,先對學習者進行常規的性格測驗����,獲得學習者的性格特征����,并將其儲存進入數據庫�,然后讓學習者使用學習系統��,產生學習表現數據�����,也將其儲存進入數據庫�����,建立學習者的學習表現數據和性格特征數據庫�。其中����,性格測驗包含卡特爾16PF人格測驗�、大五人格測驗��,卡特爾16PF人格測驗包含16個維度的性格特征���,分別是因素A-樂群性�、因素B-聰慧性����、因素C-穩定性�、因素E-恃強性�、因素F-興奮性����、因素G-有恒性��、因素H-敢為性�、因素I-敏感性�����、因素L-懷疑性���、因素M-幻想性���、因素N-世故性�、因素O-憂慮性���、因素Q1--實驗性��、因素Q2--獨立性�����、因素Q3--自律性����、因素Q4--緊張性�;而大五人格測驗包含五個維度的性格特征���,分別是外傾性��、神經質或情緒穩定性��、開放性�、隨和性�、盡責性���。
針對步驟S3��,建立學習者的學習表現數據模型和性格特征數據模型可以通過以下方式實現:將學習者的學習表現數據與性格測評結果作為性格特征評估系統的訓練集����,性格特征評估系統使用訓練集進行學習���,調整各種類型的學習表現數據與不同類型的性格特征的相關系數��,產生新的各種類型的學習表現數據與不同類型的性格特征的相關關系與相關系數���,形成學習表現數據與性格特征相互關系的穩定模型���,并將其儲存進入數據庫�����。當相關系數穩定后���,性格特征評估系統根據新學習者的學習表現數據輸出新學習者的性格特征���。
針對步驟S4�����,的數據數學算法為包含聚類分析算法S41��、關聯規則法S42��、回歸分析法S43���、BP神經網絡模型S44��、支持向量機S46的數據挖掘算法���,實施步驟可以通過以下方式實現:
針對步驟S41����,在進行聚類分析算法運算時�,聚類分析算法將學習者的表現數據類型進行相似性比較���,將比較相似的個體性格特征歸為同一組數據庫�,采用以下步驟:
(1)選取性格特征作為初始的聚類中心�����;
(2)輸入學習者的學習表現數據和性格特征的測試結果��;
(3)計算學習表現數據類型與各個性格特征聚類中心之間的距離��,使誤差平方和局部最小�,并將距離用統一量化的手段給出�,把學習表現數據類型與性格特征之間距離小于閾值的分配給相應的性格特征聚類中心�,得到的學習表現數據與性格特征之間的分配關系與距離�����;
(4)用新的數據重復(1)����、(2)����、(3)的操作�����,待相關系數穩定后�����,得到穩定的數學模型��;
(5)然后將新的學習者的學習表現數據輸入到性格特征評估系統���,可得出新學習者的性格特征����。
比如:首先計算學習表現數據中遲到的次數�,早退的次數����,破損儀器數量多少等與各類性格特征之間的距離��,其中對于“敢為性”這種性格來說只有遲到的次數�,早退的次數��,損儀器數量多少��,作業誠信度��,上課玩手機�,上課睡覺����,儀器賠償及時與否之間的距離小于閾值��,所以認定“敢為性”只與這些學習表現數據存在相關性關聯��,并且根據算出的距離按照比例得到對于“敢為性”遲到次數占25%�����,早退的次數占20%����,作業誠信度占5%�����,上課玩手機占8%�����,損壞儀器數量多少占13%���,儀器賠償及時與否占15%��,上課睡覺12%���,其余學習表現數據均小于2%的閾值��,所以不作為考慮因素�����。
同理�����,對于遲到的次數這一學習表現數據���,計算其與各類性格特征之間的距離�����,其中對于遲到次數這一學習表現數據來說�,只有敢為性��,恃強性���,穩定性���,有恒性�,實驗性���,自律性之間的距離小于閾值�����,所以認為遲到次數只與這些性格特征有關�����,并且根據算出的距離按照比例得到對于遲到次數這一學習表現數據得到敢為性占35%�����,恃強性占25%����,穩定性占15%����,有恒性8%�,實驗性占5%�����,自律性6%�����,其余性格特征均小于2%的閾值�,所以不作為考慮因素���。
以此為例可以找到任意一個學習表現數據與其余性格特征之間的相關性關系��,也可以找到任意一個性格特征與其余學習表現數據之間的相關性關系���。
針對步驟S42���,可以通過以下方式實現:關聯規則法將不同的性格特征關聯起來�����,當個體表現出一種性格特征時���,則可推斷其他性格特征��,關聯規則法數據之間的簡單的聯系規則��,是指數據之間的相互依賴關系�,比如性格特征敢為性與遲到的次數�����,早退的次數�����,損儀器數量多少�,作業誠信度���,上課玩手機�,上課睡覺��,儀器賠償及時與否這些學習表現數據有著很強的關聯特征�����,也就是當這些學習表現數據有著很高的特點是���,則被測者是有著敢為性的性格特征的����。對于遲到的次數這一學習表現數據�����,與其相關聯的性格特征為敢為性���,恃強性����,穩定性���,有恒性����,實驗性���,自律性����。當被測者遲到次數較多時����,我們認為他的性格特征與敢為性����,恃強性�,穩定性�����,有恒性����,實驗性���,自律性有關�。
補充用這種方法的核心步驟
針對步驟S43�����,可以通過以下方式實現�,首先數學模型�,用最小二乘法估計確定同類型的學習表現數據與某些性格特征之間的定量關系式���,采用逐步回歸����、向前回歸和向后回歸方法計算某個學習表現數據與某個性格特征的相關性參數來判斷某個學習表現數據與某個性格特征之間的影響是否顯著�����。具體地來說��,利用一組同類型學習表現數據�����,確定其與某些性格特征之間的定量關系式���,即建立數學模型用最小二乘法估計其中的相關性參數�����;在許多學習表現數據共同影響著一個性格特征的關系中�����,用逐步回歸���、向前回歸和向后回歸方法判斷哪個(或哪些)學習表現數據的影響是顯著的���,哪些學習表現數據的影響是不顯著的�����,將影響顯著的學習表現數據帶入模型中��,而剔除影響不顯著的變量�;用新的數據對這些關系式的可信程度進行檢驗���,檢驗結果在誤差允許范圍內即可利用所求的關系式對新的學習表現數據得到的性格特征進行預測或控制���。
比如:對于無故曠課�,多次請假�����,遲到��,早退�����,上課說話��,上課玩手機�����,上課吃東西�����,上課看與學科內容無關的書�����,上課睡覺�����,上課坐姿不端正�,預習答題狀況是否良好�����,答題用時長短���,預習答題時間的早晚��,實驗前儀器樣品狀況確認與否��,破損儀器數量多少�����,破損儀器時間�����,儀器破損上報情況�����,儀器賠償及時與否����,儀器歸放情況���,實驗完成用時長短�,實驗過程操作規范程度�����,實驗過程中的紀律遵守情況�����,試驗后衛生打掃情況���,原始實驗數據準確度��,原始實驗數據有無抄襲現象����,實驗報告的質量高低�����,作業成績���,作業用時��,上交時間��,上交次數��,作業誠信�,考試成績�����,考試用時�����,考試誠信等學習表現數據�����,這些共同影響著敢為性這一性格特征����,將這些數據用逐步回歸�����、向前回歸和向后回歸方法計算這些學習表現數據與敢為性這一性格特征的相關性參數�,從而判斷這些學習表現數據與敢為性這一性格特征之間的影響是否顯著���,經計算相關性參數����,發現只有遲到的次數�����,早退的次數����,損儀器數量多少�����,作業誠信度��,上課玩手機�,上課睡覺����,儀器賠償及時與否存在明顯的相關關系�����,其余學習表現數據并未有顯著相關關系���,所以僅考慮遲到的次數�����,早退的次數����,損儀器數量多少���,作業誠信度��,上課玩手機�����,上課睡覺�����,儀器賠償及時與否與敢為性這一性格特征之間的相關性����。同理����,我們可以做出任意一個性格特征所對應的與其顯著的學習表現數據���。
針對步驟S44����,BP神經網絡法對所有的學習表現數據與性格特征綜合分析�����,采用最速下降法�����,沿距離梯度下降的方向求解極小值�����,經過不斷的迭代與修正得出所有的學習表現數據與性格特征之間存在的最短距離���,最端距離代表與學習表現數據相關的性格特征�。具體地來說�����,將所有的學習表現數據與性格特征綜合分析��,由之前算法可以得到所有的數據與特征之間存在的距離�,并且相關性越近��,距離越短��,所以在綜合分析時����,我們采用最速下降法���,沿距離梯度下降的方向求解極小值��,經過不斷的迭代與修正得到對于某一性格特征與其相關的學習表現數據所產生的“最短距離方式”���,也可以求出對與某一學習表現數據與其對應的性格特征產生的“最短距離方式”�����,比如對于敢為性����,所產生的最短距離代表的學習表現數據為遲到的次數�����,早退的次數�,損儀器數量多少�����,作業誠信度�����,上課玩手機��,上課睡覺��,儀器賠償及時與否����。對于遲到的次數這一學習表現數據��,所產生的最短距離代表的性格特征為敢為性����,恃強性�����,穩定性�����,有恒性��,實驗性�,自律性�。
針對步驟S45�����,可以通過以下方式實現��,比如�,我們已經得到各個學習表現數據與性格特征之間的概率��,判斷取哪些學習表現數據與其中某一個性格特征合適�。我們想得到獨立性相關的學習表現數據����,則獨立性為決策點�,這些學習表現數據為狀態節點���,并標明每一數據特征與其之間的概率����,用遞歸式對數進行修剪��,得到最優的路徑��。我們得到與獨立性相關的學習表現數據為早退��,上課看與學科內容無關的書����,上課睡覺��,上課坐姿不端正�,預習答題時間的早晚����,儀器歸放情況�,實驗過程操作規范程度這些學習表現數據有著最優的關系�����,其將學習表現數據分類����,將不同類型學習表現數據更清楚地表示出來���。
比如這樣的:
針對步驟S46��,可以通過以下方式實現��,其能夠建立起與相關的學習算法有關的監督學習模型�����,可以根據有限的樣本信息在模型的復雜性(即對特定訓練樣本的學習精度)和學習能力(即無錯誤地識別任意樣本的能力)之間尋求最佳折中���,以求獲得最好的推廣能力�����。比如:我們有很多學習表現數據�����,以及提煉出的性格特征�,確定他們之間的映射關系���,與神經網絡類似����,計算某一性格特征與其相關的學習表現數據所產生的“最短距離方式”��,經過不斷的迭代運算���,最終得到比如對于獨立性這一性格特征來說�����,與其相關性較強的學習表現數據為早退���,上課看與學科內容無關的書�����,上課睡覺����,上課坐姿不端正�,預習答題時間的早晚����,儀器歸放情況���,實驗過程操作規范程度�。
二�����、非負矩陣分解
把一個學期10名同學的請假����、曠課��、遲到�、上課說話和上課睡覺的數據匯總為一個訓練集���,統計數據如表1所示:
表1訓練集
問題描述:就是建立100個不同類型的定量參數和10個另外類型的定量參數的相關關系和強度��。那100個參數之間和那10個參數是多對多關系����。但是不知道具體的相關關系和強度�����。有數據集用來學習和驗證��,相關關系和強度穩定后進行應用����。
前五列數據屬于100個不同類型的定量參數�����,后四列數據屬于10個另外類型的定量參數����,找前五列數據和后四列數據的相關關系和強度��。
要求:進行一個聚類分析�。只需要寫清過程���,不需要具體計算�。
問題分析:根據問題描述����,可以使用非負矩陣分解算法來解決這個問題�。
具體分析過程:
1.非負矩陣分解算法發展歷史
它是一種新的矩陣分解算法����,最早是1994年由Paatero和Tapper等人提出的,當時這個算法叫正矩陣分解,直到1999年, Lee和Seung在Nature上發表了他們對矩陣分解的研究�����,才逐漸引起廣大研究學者的興趣��,發展到現在���,矩陣分解方法已經應用到很多領域��。
2.矩陣分解理論
假定給定一個原數據���,用非負的數據矩陣(差異矩陣)進行表示�,將其分解為兩個非負矩陣(基矩陣)和(系數矩陣)的乘積�,并且乘積要盡可能的逼近原來的矩陣�,即(k << m, n)�。非負矩陣分解模型可以表示為以下的優化問題:
需要使用一下迭代公式來求得W和H
3.非負矩陣分解算法應用到以上問題中
(1)首先是原始矩陣的構造:在這個問題中���,我們構建矩陣數據矩陣(屬性-對象矩陣)�,10行5列的數據矩陣��。如下所示:
其中��,一行代表一名學生(對象)�����,一列代表一個屬性(是否請假��、無故曠課���、遲到��、上課說話���、上課睡覺)��。
(2)對這個矩陣進行矩陣分解���,其中k值選擇為4�����,W和H用隨機初始化���,其中每個值都在0-1之間����。W和H按照上面的迭代公式進行求解�,迭代次數設置為1000����。
(3)矩陣分解之后����,用矩陣W和H進行聚類分析�����。
迭代1000次之后���,得到基矩陣和系數矩陣
基矩陣:
由系數矩陣可得到前五列和后四列關系�����,權重可以看作是強度�����。
三�、來源于創青春比賽
1�����、apriori關聯:
>library(arules)
>xingge=read.csv("guanlian.csv",header=T)
#值得注意的是�,"guanlian.csv"從一個數值矩陣轉 #換為0-1矩陣����,再從0-1矩陣轉為邏輯型矩陣���,即 #0:FALSE���,1:TRUE��。
[1]"QJ" "KK" "CD" "SH" "SJ""Q1"
>data(list=xingge)
Therewere 30 warnings (use warnings() to see them)
>mode(xingge)
[1]"list"
>rules=apriori(xingge,parameter=list(support=0.3,confidence=0.4))
Apriori
Parameterspecification:
confidence minval smax aremaval originalSupport maxtime support minlen
0.40.11 none FALSETRUE50.31
maxlen targetext
10rules FALSE
Algorithmiccontrol:
filter tree heap memopt load sort verbose
0.1 TRUE TRUEFALSE TRUE2TRUE
Absoluteminimum support count: 3
set itemappearances ...[0 item(s)] done [0.00s].
settransactions ...[9 item(s), 10 transaction(s)] done [0.00s].
sortingand recoding items ... [9 item(s)] done [0.00s].
creatingtransaction tree ... done [0.00s].
checkingsubsets of size 1 2 3 4 5 6 done [0.00s].
writing... [320 rule(s)] done [0.00s].
creatingS4 object... done [0.00s].
>summary(rules)
set of320 rules
rulelength distribution (lhs + rhs):sizes
123456
748108 106456
Min. 1st Qu.MedianMean 3rd Qu.Max.
1.0003.0003.0003.4754.0006.000
summaryof quality measures:
supportconfidencelift
Min.:0.3000Min.:0.4000Min.:0.8163
1st Qu.:0.30001st Qu.:0.69171st Qu.:1.0000
Median :0.4000Median :1.0000Median :1.0000
Mean:0.4363Mean:0.8366Mean:1.0489
3rd Qu.:0.50003rd Qu.:1.00003rd Qu.:1.0179
Max.:1.0000Max.:1.0000Max.:1.4286
mininginfo:
data ntransactions support confidence
xingge100.30.4
>frequentsets=eclat(xingge,parameter=list(support=0.3,maxlen=10))
Eclat
parameterspecification:
tidLists support minlen maxlentargetext
FALSE0.3110 frequent itemsets FALSE
algorithmiccontrol:
sparse sort verbose
7-2TRUE
Absoluteminimum support count: 3
createitemset ...
settransactions ...[9 item(s), 10 transaction(s)] done [0.00s].
sortingand recoding items ... [9 item(s)] done [0.00s].
creatingbit matrix ... [9 row(s), 10 column(s)] done [0.00s].
writing... [111 set(s)] done [0.00s].
CreatingS4 object... done [0.00s].
>inspect(frequentsets[1:10])
itemssupport
[1]{QJ=TURE,KK=TURE,CD=TURE,SH=TURE,Q1=TURE} 0.3
[2]{QJ=TURE,KK=TURE,SH=TURE,Q1=TURE}0.3
[3]{KK=TURE,CD=TURE,SH=TURE,Q1=TURE}0.3
[4]{QJ=TURE,KK=TURE,CD=TURE,Q1=TURE}0.3
[5]{QJ=TURE,KK=TURE,Q1=TURE}0.3
[6]{KK=TURE,CD=TURE,Q1=TURE}0.3
[7]{KK=TURE,SH=TURE,Q1=TURE}0.3
[8]{QJ=TURE,CD=TURE,SH=TURE,Q1=TURE}0.3
[9]{QJ=TURE,SH=TURE,Q1=TURE}0.3
[10] {CD=TURE,SH=TURE,Q1=TURE}0.3
2���、Bayes
>data<-matrix(c("A1","B2","B3","B4","B5","no",
+"B1","A2","B3","B4","B5","no",
+"B1","B2","B3","B4","A5","no",
+"B1","B2","B3","A4","B5","no"),byrow=TRUE,
+nrow=4,ncol=6)
> data
[,1] [,2] [,3] [,4] [,5][,6]
[1,] "A1" "B2" "B3" "B4""B5" "no"
[2,] "B1" "A2" "B3" "B4""B5" "no"
[3,] "B1" "B2" "B3" "B4""A5" "no"
[4,] "B1" "B2" "B3" "A4""B5" "no"
> library("e1071")
> library("foreign")
>prior.yes=sum(data[,6]=="yes")/length(data[,6])
> prior.yes
[1] 0
>prior.no=sum(data[,6]=="no")/length(data[,6])
> prior.no
[1] 1
(第一種函數)
> naive.bayes.prediction<-function(condition.vec){
+G.yes<-sum((data[,1]==condition.vec[1])&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+sum((data[,1]==condition.vec[2])&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+sum((data[,1]==condition.vec[3])&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+sum((data[,1]==condition.vec[4])&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+sum((data[,1]==condition.vec[5])&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+prior.yes
+G.no<-sum((data[,1]==condition.vec[1])&(data[,5]=="no"))/sum(data[,5]=="no")*
+sum((data[,1]==condition.vec[2])&(data[,5]=="no"))/sum(data[,5]=="no")*
+sum((data[,1]==condition.vec[3])&(data[,5]=="no"))/sum(data[,5]=="no")*
+sum((data[,1]==condition.vec[4])&(data[,5]=="no"))/sum(data[,5]=="no")*
+sum((data[,1]==condition.vec[5])&(data[,5]=="no"))/sum(data[,5]=="no")*
+prior.no
+return(list(post.pr.yes=G.yes,post.pr.no=G.no,prediction=ifelse(G.yes>=G.yes,"yes","no")))
+}
>naive.bayes.prediction(c("A1","B2","B3","B4","B5"))
$post.pr.yes
[1] NaN
$post.pr.no
[1] NaN
$prediction
[1] NA
>naive.bayes.prediction(c("A1","A2","A3","A4","A5"))
$post.pr.yes
[1] NaN
$post.pr.no
[1] NaN
$prediction
[1] NA
(第二種函數)
>naive.bayes.prediction<-function(condition.vec){
+ + +G.yes<-sum((data[,1]=="A1")&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+ + +sum((data[,1]=="A2")&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+ + +sum((data[,1]=="A3")&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+ + +sum((data[,1]=="A4")&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+ + +sum((data[,1]=="A5")&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+ + +prior.yes
+ + +G.no<-sum((data[,1]=="B1")&(data[,5]=="no"))/sum(data[,5]=="no")*
+ + +sum((data[,1]=="B2")&(data[,5]=="no"))/sum(data[,5]=="no")*
+ + +sum((data[,1]=="B3")&(data[,5]=="no"))/sum(data[,5]=="no")*
+ + +sum((data[,1]=="B4")&(data[,5]=="no"))/sum(data[,5]=="no")*
+ + +sum((data[,1]=="B5")&(data[,5]=="no"))/sum(data[,5]=="no")*
+ + +prior.no
+ + +return(list(post.pr.yes=G.yes,post.pr.no=G.no,prediction=ifelse(G.yes>=G.yes,"yes","no")))
+}
>naive.bayes.prediction(c("A1","A2","A3","A4","A5"))
Error in ++G.yes <- sum((data[, 1] == "A1") &(data[, 5] == "yes"))/sum(data[,:
找不到對象'G.yes'
>naive.bayes.prediction(c("A1","B2","B3","B4","B5"))
Error in ++G.yes <- sum((data[, 1] == "A1") &(data[, 5] == "yes"))/sum(data[,:
找不到對象'G.yes'
3��、K-means:
> data(iris)
> head(iris,n=6)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
15.13.51.40.2setosa
24.93.01.40.2setosa
34.73.21.30.2setosa
44.63.11.50.2setosa
55.03.61.40.2setosa
65.43.91.70.4setosa
> install.packages("fpc")
> library(fpc)#估計輪廓系數
>norm<-function(x){(x-mean(x))/(sqry(var(x)))}
>norm<-function(x){(x-mean(x))/(sqrt(var(x)))}
> raw.data<-iris[,1:4]
>norm.data<-data.frame(sl=norm(raw.data[,1]),sw=(raw.data[,2]),pl=(raw.data[,3]),pw=(raw.data[,4]))
>k<-2:10
> round<-40
> rst<-sapply(k,function(i)#輪廓系數
+ {
+ print(paste("k=",i))
+ mean(sapply(1:round,function(r){
+ print(paste("Round",r))
+ result<-kmeans(norm.data,i)
+stats<-cluster.stats(dist(norm.data),result$cluster)
+ stats$avg.silwidth
+ }))
+ })
[1] "k= 2"
[1] "Round 1"
[1] "Round 2"
[1] "Round 3"
[1] "Round 4"
[1] "Round 5"
[1] "Round 6"
[1] "Round 7"
[1] "Round 8"
[1] "Round 9"
[1] "Round 10"
[1] "Round 11"
[1] "Round 12"
[1] "Round 13"
[1] "Round 14"
[1] "Round 15"
[1] "Round 16"
[1] "Round 17"
[1] "Round 18"
[1] "Round 19"
[1] "Round 20"
[1] "Round 21"
[1] "Round 22"
[1] "Round 23"
[1] "Round 24"
[1] "Round 25"
[1] "Round 26"
[1] "Round 27"
[1] "Round 28"
[1] "Round 29"
[1] "Round 30"
[1] "Round 31"
…….
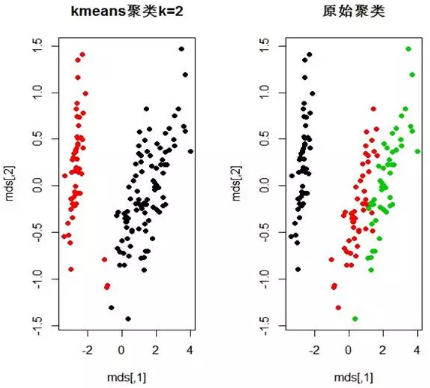
> plot(k,rst,type='l',main='輪廓系數與k的關系'����,ylab='輪廓系數')
> plot(k,rst)
> old.par<-par(mfrow=c(1,2))
> k=2
> clu<-kmeans(norm.data,k)
>mds=cmdscale(dist(norm.data,method="euclidean"))
> plot(mds,col=clu$cluster,main='kmeans聚類k=2',pch=19)
> plot(mds,col=iris$Species,main='原始聚類',pch=19)
> par(old.par)
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
