R語言解讀一元線性回歸模型
R語言作為統計學一門語言��,一直在小眾領域閃耀著光芒�。直到大數據的爆發���,R語言變成了一門炙手可熱的數據分析的利器��。隨著越來越多的工程背景的人的加入���,R語言的社區在迅速擴大成長?,F在已不僅僅是統計領域��,教育�,銀行��,電商�,互聯網….都在使用R語言�����。
要成為有理想的極客���,我們不能停留在語法上��,要掌握牢固的數學�,概率��,統計知識�,同時還要有創新精神�,把R語言發揮到各個領域����。讓我們一起動起來吧��,開始R的極客理想����。
前言
在我們的日常生活中��,存在大量的具有相關性的事件�����,比如大氣壓和海拔高度����,海拔越高大氣壓強越?�?;人的身高和體重���,普遍來看越高的人體重也越重�����。還有一些可能存在相關性的事件����,比如知識水平越高的人���,收入水平越高��;市場化的國家經濟越好��,則貨幣越強勢�,反而全球經濟危機�,黃金等避險資產越走強�。
如果我們要研究這些事件����,找到不同變量之間的關系���,我們就會用到回歸分析����。一元線性回歸分析是處理兩個變量之間關系的最簡單模型��,是兩個變量之間的線性相關關系���。讓我們一起發現生活中的規律吧����。
由于本文為非統計的專業文章�����,所以當出現與教課書不符的描述�����,請以教課書為準���。本文力求用簡化的語言��,來介紹一元線性回歸的知識��,同時配合R語言的實現���。
目錄
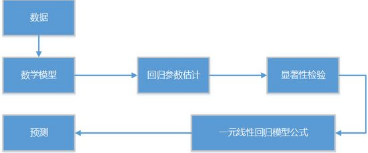
一元線性回歸介紹
數據集和數學模型
回歸參數估計
回歸方程的顯著性檢驗
殘差分析和異常點檢測
模型預測
1. 一元線性回歸介紹
回歸分析(Regression Analysis)是用來確定2個或2個以上變量間關系的一種統計分析方法�����。如果回歸分析中�����,只包括一個自變量X和一個因變量Y時��,且它們的關系是線性的����,那么這種回歸分析稱為一元線性回歸分析�。
回歸分析屬于統計學的基本模型�����,涉及統計學基礎���,就會有一大堆的名詞和知識點需要介紹�����。
在回歸分析中���,變量有2類:因變量 和 自變量����。因變量通常是指實際問題中所關心的指標����,用Y表示����。而自變量是影響因變量取值的一個變量���,用X表示�����,如果有多個自變量則表示為X1, X2, …, Xn�。
回歸分析研究的主要步驟:
確定因變量Y 與 自變量X1, X2, …, Xn 之間的定量關系表達式����,即回歸方程�����。
對回歸方程的置信度檢查����。
判斷自變量Xn(n=1,2,…,m)對因變量的影響�。
利用回歸方程進行預測�����。
本文會根據回歸分析的的主要步驟��,進行結構梳理����,介紹一元線性回歸模型的使用方法��。
2. 數據集和數學模型
先讓我們通過一個例子開始吧����,用一組簡單的數據來說明一元線性回歸分析的數學模型的原理和公式���。找出下面數據集中Y與X的定量關系�。
數據集為2016年3月1日�,白天開盤的交易數據��,為鋅的2個期貨合約的分鐘線的價格數據���。數據集包括有3列���,索引列為時間�����,zn1.Close為ZN1604合約的1分鐘線的報價數據����,zn2.Close為ZN1605合約的1分鐘線的報價數據�。
數據集如下:
zn1.Close zn2.Close
2016-03-01 09:01:00 14075 14145
2016-03-01 09:02:00 14095 14160
2016-03-01 09:03:00 14095 14160
2016-03-01 09:04:00 14095 14165
2016-03-01 09:05:00 14120 14190
2016-03-01 09:06:00 14115 14180
2016-03-01 09:07:00 14110 14170
2016-03-01 09:08:00 14110 14175
2016-03-01 09:09:00 14105 14170
2016-03-01 09:10:00 14105 14170
2016-03-01 09:11:00 14120 14180
2016-03-01 09:12:00 14105 14170
2016-03-01 09:13:00 14105 14170
2016-03-01 09:14:00 14110 14175
2016-03-01 09:15:00 14105 14175
2016-03-01 09:16:00 14120 14185
2016-03-01 09:17:00 14125 14190
2016-03-01 09:18:00 14115 14185
2016-03-01 09:19:00 14135 14195
2016-03-01 09:20:00 14125 14190
2016-03-01 09:21:00 14135 14205
2016-03-01 09:22:00 14140 14210
2016-03-01 09:23:00 14140 14200
2016-03-01 09:24:00 14135 14205
2016-03-01 09:25:00 14140 14205
2016-03-01 09:26:00 14135 14205
2016-03-01 09:27:00 14130 14205
我們以zn1.Close列的價格為X�����,zn2.Close列的價格為Y��,那么試試找到自變量X和因變量Y的關系的表達式��。
為了直觀起見�����,我們可以先畫出一張散點圖���,以X為橫坐標���,Y為縱坐標��,每個點對應一個X和一個Y�。
# 數據集已存在df變量中
> head(df)
zn1.Close zn2.Close
2016-03-01 09:01:00 14075 14145
2016-03-01 09:02:00 14095 14160
2016-03-01 09:03:00 14095 14160
2016-03-01 09:04:00 14095 14165
2016-03-01 09:05:00 14120 14190
2016-03-01 09:06:00 14115 14180
# 分別給x,y賦值
> x<-as.numeric(df[,1])
> y<-as.numeric(df[,2])
# 畫圖
> plot(y~x+1)
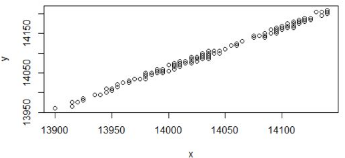
從散點圖上發現 X和Y 的排列基本是在一條直線附近���,那么我們可以假設X和Y的關系是線性��,可以用公式表式為�����。
Y = a + b * X + c
Y�,為因變量
X���,為自變量
a�����,為截距
b����,為自變量系數
a+b*X, 表示Y隨X的變化而線性變化的部分
c, 為殘差或隨機誤差��,是其他一切不確定因素影響的總和��,其值不可觀測�。假定c是符合均值為0方差為σ^2的正態分布 �����,記作c~N(0,σ^2)
對于上面的公式�,稱函數f(X) = a + b * X 為一元線性回歸函數��,a為回歸常數�����,b為回歸系數����,統稱回歸參數�。X 為回歸自變量或回歸因子����,Y 為回歸因變量或響應變量�。如果(X1,Y1)����,(X2,Y2)…(Xn,Yn)是(X,Y)的一組觀測值���,則一元線性回歸模型可表示為
Yi = a + b * X + ci�����, i= 1,2,...n
其中E(ci)=0, var(ci)=σ^2, i=1,2,...n
通過對一元線性回歸模型的數學定義��,接下來讓我們利用數據集做回歸模型的參數估計�����。
3. 回歸參數估計
對于上面的公式���,回歸參數a,b是我們不知道的����,我們需要用參數估計的方法來計算出a,b的值���,而從得到數據集的X和Y的定量關系��。我們的目標是要計算出一條直線���,使直接線上每個點的Y值和實際數據的Y值之差的平方和最小����,即(Y1實際-Y1預測)^2+(Y2實際-Y2預測)^2+ …… +(Yn實際-Yn預測)^2 的值最小�。參數估計時�,我們只考慮Y隨X的線性變化的部分�����,而殘差c是不可觀測的�,參數估計法并不需要考慮殘差�,對于殘差的分析在后文中介紹��。
令公式變形為a和b的函數Q(a,b), 即 (Y實際-Y測試)的平方和�,變成到(Y實際 – (a+b*X))的平方和��。
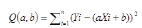
公式一 回歸參數變形公式
通過最小二乘估計推導出a和b的求解公式����,詳細的推導過程請參考文章 一元線性回歸的細節
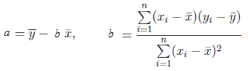
公式二 回歸參數計算公式
其中 x和y的均值����,計算方法如下
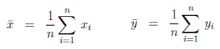
公式三 均值計算公式
有了這個公式����,我們就可以求出a和b兩個的回歸參數的解了��。
接下來�,我們用R語言來實現對上面數據的回歸模型的參數估計�,R語言中可以用lm()函數來實現一元線性回歸的建模過程�。
# 建立線性回歸模型
> lm.ab<-lm(y ~ 1+x)
# 打印參數估計的結果
> lm.ab
Call:
lm(formula = y ~ 1 + x)
Coefficients:
(Intercept) x
-349.493 1.029
如果你想動手來計算也可以自己實現公式���。
# x均值
> Xm<-mean(x);Xm
[1] 14034.82
# y均值
> Ym<-mean(y);Ym
[1] 14096.76
# 計算回歸系數
> b <- sum((x-Xm)*(y-Ym)) / sum((x-Xm)^2) ;b
[1] 1.029315
# 計算回歸常數
> a <- Ym - b * Xm;a
[1] -349.493
回歸參數a和b的計算結果�����,與lm()函數的計算結果是相同的�����。有了a和b的值�����,我們就可以畫出這條近似的直接線�。
計算公式為:
Y= a + b * X = -349.493 + 1.029315 * X
畫出回歸線��。
> plot(y~x+1)
> abline(lm.ab)
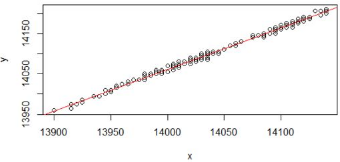
這條直線是我們用數據擬合出來的����,是一個近似的值��。我們看到有些點在線上��,有些點不在線上���。那么要評價這條回歸線擬合的好壞���,我們就需要對回歸模型進行顯著性檢驗����。
4. 回歸方程的顯著性檢驗
從回歸參數的公式二可知���,在計算過程中并不一定要知道Y和X是否有線性相關的關系�。如果不存相關關系�,那么回歸方程就沒有任何意義了���,如果Y和X是有相關關系的�����,即Y會隨著X的變化而線性變化�����,這個時候一元線性回歸方程才有意義�����。所以�,我們需要用假設檢驗的方法����,來驗證相關性的有效性�����。
通常會采用三種顯著性檢驗的方法�����。
T檢驗法:T檢驗是檢驗模型某個自變量Xi對于Y的顯著性�,通常用P-value判斷顯著性����,小于0.01更小時說明這個自變量Xi與Y相關關系顯著�。
F檢驗法:F檢驗用于對所有的自變量X在整體上看對于Y的線性顯著性�����,也是用P-value判斷顯著性���,小于0.01更小時說明整體上自變量與Y相關關系顯著�。
R^2(R平方)相關系統檢驗法:用來判斷回歸方程的擬合程度�,R^2的取值在0��,1之間���,越接近1說明擬合程度越好�。
在R語言中�,上面列出的三種檢驗的方法都已被實現���,我們只需要把結果解讀�����。上文中�����,我們已經通過lm()函數構建一元線性回歸模型�,然后可以summary()函數來提取模型的計算結果��。
> summary(lm.ab) # 計算結果
Call:
lm(formula = y ~ 1 + x)
Residuals:
Min 1Q Median 3Q Max
-11.9385 -2.2317 -0.1797 3.3546 10.2766
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.495e+02 7.173e+01 -4.872 2.09e-06 ***
x 1.029e+00 5.111e-03 201.390 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.232 on 223 degrees of freedom
Multiple R-squared: 0.9945, Adjusted R-squared: 0.9945
F-statistic: 4.056e+04 on 1 and 223 DF, p-value: < 2.2e-16
模型解讀:
Call�����,列出了回歸模型的公式�。
Residuals��,列出了殘差的最小值點�,1/4分位點����,中位數點���,3/4分位點��,最大值點����。
Coefficients�,表示參數估計的計算結果����。
Estimate����,為參數估計列���。Intercept行表示常數參數a的估計值 ���,x行表示自變量x的參數b的估計值�����。
Std. Error�,為參數的標準差�����,sd(a), sd(b)
t value��,為t值�,為T檢驗的值
Pr(>|t|) ��,表示P-value值���,用于T檢驗判定���,匹配顯著性標記
顯著性標記���,***為非常顯著�,**為高度顯著, **為顯著��,·為不太顯著�,沒有記號為不顯著����。
Residual standard error�����,表示殘差的標準差�,自由度為n-2�����。
Multiple R-squared�����,為相關系數R^2的檢驗�,越接近1則越顯著��。
Adjusted R-squared�,為相關系數的修正系數�����,解決多元回歸自變量越多��,判定系數R^2越大的問題�����。
F-statistic����,表示F統計量�����,自由度為(1,n-2)�����,p-value:用于F檢驗判定���,匹配顯著性標記�����。
通過查看模型的結果數據����,我們可以發現通過T檢驗的截距和自變量x都是非常顯著���,通過F檢驗判斷出整個模型的自變量是非常顯著����,同時R^2的相關系數檢驗可以判斷自變量和因變量是高度相關的���。
最后���,我們通過的回歸參數的檢驗與回歸方程的檢驗����,得到最后一元線性回歸方程為:
Y = -349.493 + 1.029315 * X
5. 殘差分析和異常點檢測
在得到的回歸模型進行顯著性檢驗后��,還要在做殘差分析(預測值和實際值之間的差)���,檢驗模型的正確性����,殘差必須服從正態分布N(0,σ^2)��。
我們可以自己計算數據殘差��,并進行正態分布檢驗�。
# 殘差
> y.res<-residuals(lm.ab)
# 打印前6條數據
> head(y.res)
1 2 3 4 5 6
6.8888680 1.3025744 1.3025744 6.3025744 5.5697074 0.7162808
# 正態分布檢驗
> shapiro.test(y.res)
Shapiro-Wilk normality test
data: y.res
W = 0.98987, p-value = 0.1164
# 畫出殘差散點圖
> plot(y.res)
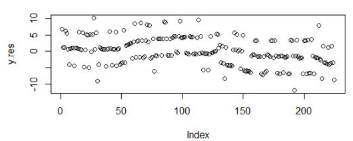
對殘差進行Shapiro-Wilk正態分布檢驗�,W接近1�����,p-value>0.05���,證明數據集符合正態分布���!關于正態分布的介紹�����,請參考文章 常用連續型分布介紹及R語言實現 ��。
同時�,我們也可以用R語言的工具生成4種用于模型診斷的圖形����,簡化自己寫代碼計算的操作�。
# 畫圖�����,回車展示下一張
> plot(lm.ab)
Hit
to see next plot: # 殘差擬合圖
Hit
to see next plot: # 殘差QQ圖
Hit
to see next plot: # 標準化的殘差對擬合值
Hit
to see next plot: # 標準化殘差對杠桿值
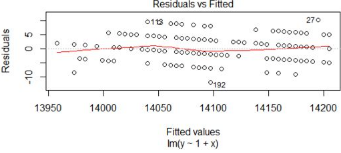
圖1����,殘差和擬合值對比圖
對殘差和擬合值作圖���,橫坐標是擬合值��,縱坐標是殘差�。殘差和擬合值之間����,數據點均勻分布在y=0兩側����,呈現出隨機的分布�,紅色線呈現出一條平穩的曲線并沒有明顯的形狀特征����,說明殘差數據表現非常好�����。
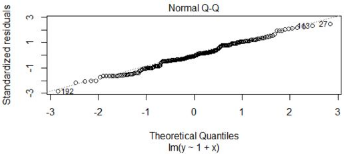
圖2���,殘差QQ圖
殘差QQ圖�����,用來描述殘差是否符合正態分布���。圖中的數據點按對角直線排列��,趨于一條直線�,并被對角直接穿過�,直觀上符合正態分布����。對于近似服從正態分布的標準化殘差�����,應該有 95% 的樣本點落在 [-2,2] 區間內���。
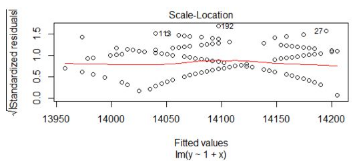
圖3��,標準化殘差平方根和擬合值對比圖
對標準化殘差平方根和擬合值作圖�,橫坐標是擬合值�����,縱坐標是標準化后的殘差平方根���。與殘差和擬合值對比圖(圖1)的判斷方法類似���,數據隨機分布����,紅色線呈現出一條平穩的曲線��,無明顯的形狀特征��。
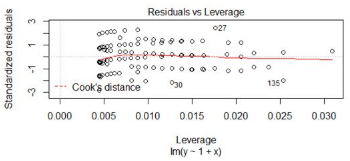
圖4�,標準殘差和杠桿值對比圖
對標準化殘差和杠桿值作圖��,虛線表示的cooks距離等高線�����,通常用Cook距離度量的回歸影響點���。本圖中沒有出現紅色的等高線����,則說明數據中沒有特別影響回歸結果的異常點�����。
如果想把把4張圖畫在一起進行展示��,可以改變畫布布局����。
> par(mfrow=c(2,2))
> plot(lm.ab)
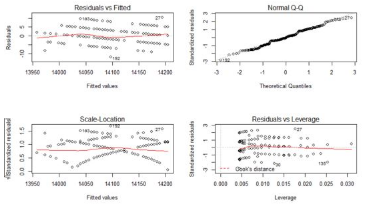
看到上面4幅中���,每幅圖上都有一些點被特別的標記出來了�����,這些點是可能存在的異常值點���,如果要對模型進行優化��,我們可以從這些來入手�。但終于本次殘差分析的結果已經很好了�����,所以對于異常點的優化�����,可能并不能明顯的提升模型的效果�。
從圖中發現����,索引編號為27和192的2個點在多幅圖中出現��。我們假設這2個點為異常點���,從數據中去掉這2個點���,再進行顯著性檢驗和殘差分析���。
# 查看27和192
> df[c(27,192),]
zn1.Close zn2.Close
2016-03-01 09:27:00 14130 14205
2016-03-01 14:27:00 14035 14085
# 新建數據集���,去掉27和192
> df2<-df[-c(27,192),]
回歸建模和顯著性檢驗�。
> x2<-as.numeric(df2[,1])
> y2<-as.numeric(df2[,2])
> lm.ab2<-lm(y2 ~ 1+x2)
> summary(lm.ab2)
Call:
lm(formula = y2 ~ 1 + x2)
Residuals:
Min 1Q Median 3Q Max
-9.0356 -2.1542 -0.2727 3.3336 9.5879
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.293e+02 7.024e+01 -4.688 4.83e-06 ***
x2 1.028e+00 5.004e-03 205.391 < 2e-16 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.117 on 221 degrees of freedom
Multiple R-squared: 0.9948, Adjusted R-squared: 0.9948
F-statistic: 4.219e+04 on 1 and 221 DF, p-value: < 2.2e-16
對比這次的顯著性檢驗結果和之前結果���,T檢驗���,F檢驗 和 R^2檢驗�,并沒有明顯的效果提升�,結果和我預想的是一樣的����。所以�,通過殘差分析和異常點分析��,我認為模型是有效的���。
6. 模型預測
最后���,我們獲得了一元線性回歸方程的公式��,就可以對數據進行預測了����。比如����,對給定X=x0時�����,計算出y0=a+b*x0的值�,并計算出置信度為1-α的預測區間�。
當X=x0,Y=y0時����,置信度為1-α的預測區間為
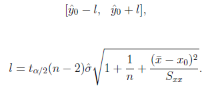
即

我們可以用R語言的predict()函數來計算預測值y0����,和相應的預測區間���。程序算法如下���。
> new<-data.frame(x=14040)
> lm.pred<-predict(lm.sol,new,interval="prediction",level=0.95)
# 預測結果
> lm.pred
fit lwr upr
1 14102.09 14093.73 14110.44
當x0=14040時����,在預測區間為0.95的概率時���,y0的值為 14102�,預測區間為[14093.73,14110.44]�����。
我們通過圖形來表示�。
> plot(y~x+1)
> abline(lm.ab,col='red')
> points(rep(newX$x,3),y=lm.pred,pch=19,col=c('red','blue','green'))
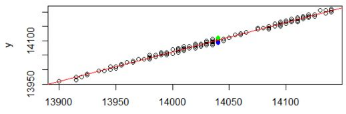
其中�����,紅色點為y0的值�,藍色點為預測區間最小值��,綠色點為預測區間最大值�����。
對于統計模型中最核心部分就在結果解讀����,本文介紹了一元回歸模型的基本的建模過程和模型的詳細解讀方法���。在我們掌握了這種方法以后��,就可以更容易地理解和學習 多元回歸�,非線性回歸 等更多的模型����,并把這些模型應用到實際的工作中了�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
