機器學習中的降維算法:ISOMAP & MDS
降維是機器學習中很有意思的一部分����,很多時候它是無監督的�,能夠更好地刻畫數據�����,對模型效果提升也有幫助����,同時在數據可視化中也有著舉足輕重的作用��。
一說到降維���,大家第一反應總是PCA���,基本上每一本講機器學習的書都會提到PCA���,而除此之外其實還有很多很有意思的降維算法�����,其中就包括isomap�����,以及isomap中用到的MDS�。
ISOMAP是‘流形學習’中的一個經典算法���,流形學習貢獻了很多降維算法��,其中一些與很多機器學習算法也有結合�����,但上學的時候還看了蠻多的機器學習的書��,從來沒聽說過流形學習的概念��,還是在最新的周志華版的《機器學習》里才看到,很有意思��,記錄分享一下��。
流形學習
流形學習應該算是個大課題了�,它的基本思想就是在高維空間中發現低維結構����。比如這個圖:
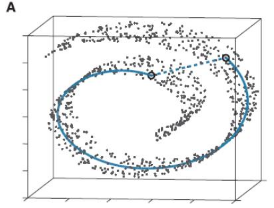
這些點都處于一個三維空間里���,但我們人一看就知道它像一塊卷起來的布���,圖中圈出來的兩個點更合理的距離是A中藍色實線標注的距離��,而不是兩個點之間的歐式距離(A中藍色虛線)�����。
此時如果你要用PCA降維的話����,它 根本無法發現這樣卷曲的結構 (因為PCA是典型的 線性降維 ��,而圖示的結構顯然是非線性的)���,最后的降維結果就會一團亂麻����,沒法很好的反映點之間的關系�。而流形學習在這樣的場景就會有很好的效果��。
我對流形學習本身也不太熟悉��,還是直接說算法吧�。
ISOMAP
在降維算法中���,一種方式是提供點的坐標進行降維�,如PCA�����;另一種方式是提供點之間的距離矩陣�,ISOMAP中用到的MDS(Multidimensional Scaling)就是這樣���。
在計算距離的時候�����,最簡單的方式自然是計算坐標之間的歐氏距離��,但ISOMAP對此進行了改進����,就像上面圖示一樣:
1.通過kNN(k-Nearest Neighbor)找到點的k個最近鄰�,將它們連接起來構造一張圖�����。
2. 通過計算同中各點之間的最短路徑���,作為點之間的距離 i j
放入距離矩陣 D
3. 將 D 傳給經典的MDS算法�,得到降維后的結果�。
ISOMAP本身的 核心就在構造點之間的距離 �����,初看時不由得為其拍案叫絕�����,類似的思想在很多降維算法中都能看到�,比如能將超高維數據進行降維可視化的t-SNE���。
ISOMAP效果����,可以看到選取的最短路徑比較好地還原了期望的藍色實線����,用這個數據進行降維會使流形得以保持:
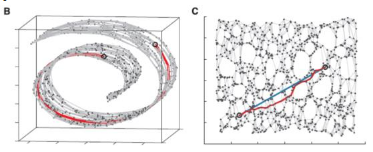
ISOMAP算法步驟可謂清晰明了���,所以本文主要著重講它中間用到的MDS算法��,也是很有意思的����。
經典MDS(Multidimensional Scaling)
如上文所述�,MDS接收的輸入是一個距離矩陣 D
,我們把一些點畫在坐標系里:
如果只告訴一個人這些點之間的距離(假設是歐氏距離)��,他會丟失那些信息呢�?
a. 我們對點做平移�,點之間的距離是不變的��。
b. 我們對點做旋轉�����、翻轉�,點之間的距離是不變的����。
所以想要從 D
還原到原始數據 是不可能的�����,因為只給了距離信息之后本身就丟掉了很多東西����,不過不必擔心�,即使這樣我們也可以對數據進行降維�。
我們不妨假設:
是一個 n × 的矩陣����,n為樣本數���,q是原始的維度
計算一個很重要的矩陣 B :
= ( n × n ) = ( ) ( ) ( 是 一 組 正 交 基 )
可以看到我們通過 對 做正交變換并不會影響 B 的值�,而 正交變換剛好就是對數據做旋轉����、翻轉操作的 ����。
所以如果我們想通過 B 反算出 ��,肯定是沒法得到真正的 , 而是它的任意一種正交變換后的結果�。
B中每個元素的值為:
b i j = ∑ k = 1 x i k x j k
計算距離矩陣 D ���,其中每個元素值為:
= ( x i ? x j ) 2 = ∑ k = 1 ( x i k ? x j k ) 2 = ∑ k = 1 x 2 i k + x 2 j k ? 2 x i k x j k = b i i + b j j ? 2 b i j \tag{dij_square}\label{dij_square}
這時候我們有的只有 D ����,如果能通過 D 計算出 B �,再由 B 計算出 ����,不就達到效果了嗎��。
所以思路是:從D->B->X
此時我們要對X加一些限制�����,前面說過我們平移所有點是不會對距離矩陣造成影響的��,所以我們就把 數據的中心點平移到原點 ���,對X做如下限制(去中心化):
∑ i = 1 n x i k = 0 , o r a l l k = 1..
所以有
∑ j = 1 n b i j = ∑ j = 1 n ∑ k = 1 x i k x j k = ∑ k = 1 x i k ∑ j = 1 n x j k = 0
類似的
∑ i = 1 n b i j = ∑ i = 1 n ∑ k = 1 x i k x j k = ∑ k = 1 x j k ( ∑ i = 1 n x i k ) = 0
可以看到即 B 的任意行(row)之和以及任意列(column)之和都為0了��。
設T為 B
的trace���,則有:
∑ i = 1 n 2 i j = ∑ i = 1 n b i i + b j j ? 2 b i j = + n b j j + 0
∑ j = 1 n 2 i j = ∑ j = 1 n b i i + b j j ? 2 b i j = n b i i + + 0
∑ i = 1 n ∑ j = 1 n 2 i j = 2 n
得到B:根據公式 我們有:
b i j = ? 1 2 ( 2 i j ? b i i ? b j j )
而(根據前面算 ∑ n i = 1 2 i j , ∑ n j = 1 2 i j 和 ∑ n i = 1 ∑ n j = 1 2 i j 的公式可以得到)
b i i b j j 2 n = + 1 n ∑ j = 1 n 2 i j = + 1 n ∑ i = 1 n 2 i j = 1 n 2 ∑ i = 1 n ∑ j = 1 n 2 i j
所以
= ? 1 2 ( 2 i j ? b i i ? b j j ) = ? 1 2 ( 2 i j ? 1 n ∑ j = 1 n 2 i j ? 1 n ∑ i = 1 n 2 i j + 2 n ) = ? 1 2 ( 2 i j ? 1 n ∑ j = 1 n 2 i j ? 1 n ∑ i = 1 n 2 i j + 1 n 2 ∑ i = 1 n ∑ j = 1 n 2 i j ) = ? 1 2 ( 2 i j ? 2 i ? ? 2 ? j + 2 ? ? )
可以看到 2 i ? 是 D 2 行均值��; 2 ? j 是列均值����; 2 ? ? 是矩陣的均值��。
這樣我們就可以通過矩陣 D
得到矩陣 B 了
因為B是對稱的矩陣�,所以可以通過特征分解得到:
B = Λ ? 1 = Λ
在最開始我們其實做了一個假設�����, 即 D 是由一個 n × 的數據生成的�,如果事實是這樣的�, D 會是一個對稱實矩陣��,此時得到的 B 剛好會有 個非0的特征值��,也就是說 B 的秩等于 �����,如果我們想還原 ��,就選擇前 個特征值和特征向量����;如果想要達到降維的目的�,就選擇制定的 p 個( p < )����。
此時我們選擇前 p
個特征值和特征向量���,(這一步和PCA里面很類似):
B ? = ? Λ ? ? ? ( n × p ) , Λ ? ( p × p )
所以有( Λ 是特征值組成的對角矩陣):
B ? = ? Λ ? 1 2 ? Λ ? 1 2 ? = ? ?
因此
? = ? Λ ? 1 2
如果選擇 p = 的話����,此時得到的 ? 就是原數據去中心化并做了某種正交變換后的值了�。
MDS的例子
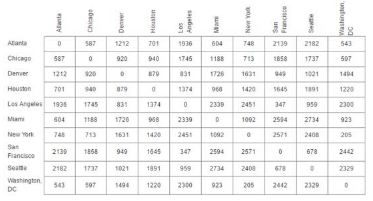
舉個例子:拿美國一些大城市之間的距離作為矩陣傳進去��,簡單寫一寫代碼:
import numpy as np
import matplotlib.pyplot as plt
def mds(D,q):
D = np.asarray(D)
DSquare = D**2
totalMean = np.mean(DSquare)
columnMean = np.mean(DSquare, axis = 0)
rowMean = np.mean(DSquare, axis = 1)
B = np.zeros(DSquare.shape)
for i in range(B.shape[0]):
for j in range(B.shape[1]):
B[i][j] = -0.5*(DSquare[i][j] - rowMean[i] - columnMean[j]+totalMean)
eigVal,eigVec = np.linalg.eig(B)
X = np.dot(eigVec[:,:q],np.sqrt(np.diag(eigVal[:q])))
return X
D = [[0,587,1212,701,1936,604,748,2139,2182,543],
[587,0,920,940,1745,1188,713,1858,1737,597],
[1212,920,0,879,831,1726,1631,949,1021,1494],
[701,940,879,0,1374,968,1420,1645,1891,1220],
[1936,1745,831,1374,0,2339,2451,347,959,2300],
[604,1188,1726,968,2339,0,1092,2594,2734,923],
[748,713,1631,1420,2451,1092,0,2571,2408,205],
[2139,1858,949,1645,347,2594,2571,0,678,2442],
[2182,1737,1021,1891,959,2734,2408,678,0,2329],
[543,597,1494,1220,2300,923,205,2442,2329,0]]
label = ['Atlanta','Chicago','Denver','Houston','Los Angeles','Miami','New York','San Francisco','Seattle','Washington, DC']
X = mds(D,2)
plt.plot(X[:,0],X[:,1],'o')
for i in range(X.shape[0]):
plt.text(X[i,0]+25,X[i,1]-15,label[i])
plt.show()
最后畫出來的圖中�,各個城市的位置和真實世界中的相對位置都差不多:

注意���,這個例子中其實也有‘流形’在里面��,因為我們的地球其實是一個三維�,而城市間距離刻畫的是在球面上的距離��,所以最后如果你去看求出來的特征值���,并不像前面說的那樣只有q個非0的值�。數據分析師培訓
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
