機器學習中的kNN算法及Matlab實例
K最近鄰(k-Nearest Neighbor���,KNN)分類算法���,是一個理論上比較成熟的方法�����,也是最簡單的機器學習算法之一����。該方法的思路是:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別��,則該樣本也屬于這個類別�����。
盡管kNN算法的思想比較簡單�,但它仍然是一種非常重要的機器學習(或數據挖掘)算法�����。在2006年12月召開的 IEEE
International Conference on Data Mining (ICDM)���,與會的各位專家選出了當時的十大數據挖掘算法( top 10 data mining algorithms )���,可以參加文獻【1】�����, K最近鄰算法即位列其中��。
二���、在Matlab中利用kNN進行最近鄰查詢
如果手頭有一些數據點(以及它們的特征向量)構成的數據集�����,對于一個查詢點����,我們該如何高效地從數據集中找到它的最近鄰呢����?最通常的方法是基于k-d-tree進行最近鄰搜索�����。
KNN算法不僅可以用于分類����,還可以用于回歸��,但主要應用于回歸����,所以下面我們就演示在MATLAB中利用KNN算法進行數據挖掘的基本方法�。
首先在Matlab中載入數據����,代碼如下�,其中meas( : , 3:4)相當于取出(之前文章中的)Petal.Length和Petal.Width這兩列數據�����,一共150行�,三類鳶尾花每類各50行�。
[plain] view plain copy
load fisheriris
x = meas(:,3:4);
然后我們可以借助下面的代碼來用圖形化的方式展示一下數據的分布情況:
[plain] view plain copy
gscatter(x(:,1),x(:,2),species)
legend('Location','best')
執行上述代碼�����,結果如下圖所示:
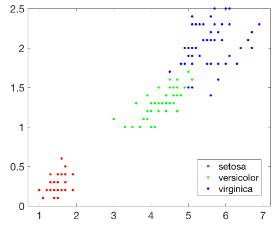
然后我們在引入一個新的查詢點��,并在圖上把該點用×標識出來:
[plain] view plain copy
newpoint = [5 1.45];
line(newpoint(1),newpoint(2),'marker','x','color','k',...
'markersize',10,'linewidth',2)
結果如下圖所示:
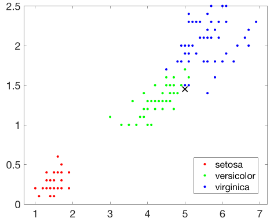
接下來建立一個基于KD-Tree的最近鄰搜索模型�����,查詢目標點附近的10個最近鄰居�,并在圖中用圓圈標識出來�。
[plain] view plain copy
>> Mdl = KDTreeSearcher(x)
Mdl =
KDTreeSearcher with properties:
BucketSize: 50
Distance: 'euclidean'
DistParameter: []
X: [150x2 double]
>> [n,d] = knnsearch(Mdl,newpoint,'k',10);
line(x(n,1),x(n,2),'color',[.5 .5 .5],'marker','o',...
'linestyle','none','markersize',10)
下圖顯示確實找出了查詢點周圍的若干最近鄰居���,但是好像只要8個�,
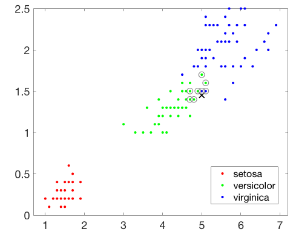
不用著急��,其實系統確實找到了10個最近鄰居����,但是其中有兩對數據點完全重合�����,所以在圖上你只能看到8個�����,不妨把所有數據都輸出來看看���,如下所示����,可知確實是10個�����。
[plain] view plain copy
>> x(n,:)
ans =
5.0000 1.5000
4.9000 1.5000
4.9000 1.5000
5.1000 1.5000
5.1000 1.6000
4.8000 1.4000
5.0000 1.7000
4.7000 1.4000
4.7000 1.4000
4.7000 1.5000
KNN算法中�����,所選擇的鄰居都是已經正確分類的對象�����。該方法在確定分類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別����。例如下面的代碼告訴我們��,待查詢點的鄰接中有80%是versicolor類型的鳶尾花����,所以如果采用KNN來進行分類�,那么待查詢點的預測分類結果就應該是versicolor類型���。
[plain] view plain copy
>> tabulate(species(n))
Value Count Percent
virginica 2 20.00%
versicolor 8 80.00%
在利用 KNN方法進行類別決策時�,只與極少量的相鄰樣本有關�����。由于KNN方法主要靠周圍有限的鄰近的樣本���,而不是靠判別類域的方法來確定所屬類別的�,因此對于類域的交叉或重疊較多的待分樣本集來說��,KNN方法較其他方法更為適合�。
我們還要說明在Matlab中使用KDTreeSearcher進行最近鄰搜索時�,距離度量的類型可以是歐拉距離('euclidean')����、曼哈頓距離('cityblock')��、閔可夫斯基距離('minkowski')�����、切比雪夫距離('chebychev')�,缺省情況下系統使用歐拉距離����。你甚至還可以自定義距離函數��,然后使用knnsearch()函數來進行最近鄰搜索�,具體可以查看MATLAB的幫助文檔��,我們不具體展開�。
三����、利用kNN進行數據挖掘的實例
下面我們來演示在MATLAB構建kNN分類器�,并以此為基礎進行數據挖掘的具體步驟�����。首先還是載入鳶尾花數據����,不同的是這次我們使用全部四個特征來訓練模型����。
[plain] view plain copy
load fisheriris
X = meas; % Use all data for fitting
Y = species; % Response data
然后使用fitcknn()函數來訓練分類器模型�。
[plain] view plain copy
>> Mdl = fitcknn(X,Y)
Mdl =
ClassificationKNN
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
Distance: 'euclidean'
NumNeighbors: 1
你可以看到默認情況下��,最近鄰的數量為1���,下面我們把它調整為4��。
[plain] view plain copy
Mdl.NumNeighbors = 4;
或者你可以使用下面的代碼來完成上面同樣的任務:
[plain] view plain copy
Mdl = fitcknn(X,Y,'NumNeighbors',4);
既然有了模型�����,我們能否利用它來執行以下預測分類呢��,具體來說此時我們需要使用predict()函數����,例如
[plain] view plain copy
>> flwr = [5.0 3.0 5.0 1.45];
>> flwrClass = predict(Mdl,flwr)
flwrClass =
'versicolor'
最后����,我們還可以來評估一下建立的kNN分類模型的情況��。例如你可以從已經建好的模型中建立一個cross-validated 分類器:
[plain] view plain copy
CVMdl = crossval(Mdl);
然后再來看看cross-validation loss�����,它給出了在對那些沒有用來訓練的數據進行預測時每一個交叉檢驗模型的平均損失
[plain] view plain copy
>> kloss = kfoldLoss(CVMdl)
kloss =
0.0333
再來檢驗一下resubstitution loss, which�����,默認情況下����,它給出的是模型Mdl預測結果中被錯誤分類的數據占比��。
[plain] view plain copy
>> rloss = resubLoss(Mdl)
rloss =
0.0400
如你所見���,cross-validated 分類準確度與 resubstitution 準確度大致相近�����。所以你可以認為你的模型在面對新數據時(假設新數據同訓練數據具有相同分布的話)�,分類錯誤的可能性大約是 4% ��。
四���、關于k值的選擇
kNN算法在分類時的主要不足在于�����,當樣本不平衡時��,如一個類的樣本容量很大����,而其他類樣本容量很小時�,有可能導致當輸入一個新樣本時����,該樣本的K個鄰居中大容量類的樣本占多數�。因此可以采用權值的方法(和該樣本距離小的鄰居權值大)來改進�。
從另外一個角度來說��,算法中k值的選擇對模型本身及其對數據分類的判定結果都會產生重要影響�����。如果選擇較小的k值���,就相當于用較小的領域中的訓練實例來進行預測�,學習的近似誤差會減小�����,只有與輸入實例較為接近(相似的)訓練實例才會對預測結果起作用�。但缺點是“學習”的估計誤差會增大��。預測結果會對近鄰的實例點非常敏感��。如果臨近的實例點恰巧是噪聲�,預測就會出現錯誤����。換言之�����,k值的減小意味著整體模型變得復雜��,容易發成過擬合�。數據分析師培訓
如果選擇較大的k值����,就相當于用較大的鄰域中的訓練實例進行預測����,其優點是可以減少學習的估計誤差�����,但缺點是學習的近似誤差會增大����。這時與輸入實例較遠的(不相似的)訓練實例也會對預測起作用���,使預測發生錯誤����。k值的增大就意味著整體的模型變得簡單�����。
在應用中�����,k值一般推薦取一個相對比較小的數值�����。并可以通過交叉驗證法來幫助選取最優k值��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
