使用Python分析紐約出租車搭乘數據
在紐約�����,出租車分為兩類:黃色和綠色�。黃色出租(Yellow TAXI)車可以在紐約五大區(布朗克斯區���、布魯克林區��、曼哈頓����、皇后區��、斯塔滕島)內任何地點搭載乘客�。綠色出租車(Green TAXI)則被規定只允許在上曼哈頓��、布朗克斯區�����、皇后區和斯塔滕島接客�����,這兩類出租車均由私人公司經營并受到紐約市出租車和轎車委員會(NYC Taxi and Limousine Commission)的監管����。本篇文章使用python對綠色出租車2016年1月——6月的數據進行分析����,探究綠色出租車的是使用趨勢��,用戶使用習慣以及天氣因素對出租車使用量的影響����。
開始前的準備工作
開始分析之前先進行導入庫文件和數據的準備工作����,首先導入分析過程中需要使用的庫文件�����,用于對數據進行計算和格式轉換����,這里不再贅述����,請見下面的代碼����。
#導入所需的庫文件
import numpy as np
import pandas as pd
import time,datetime
import matplotlib.pyplot as plt
然后分別導入green_taxi 2016年1月至6月的數據表�,并對數據表進行進行拼接���。組成用于分析的完整數據大表��。
#導入green_taxi2016年1-6月數據
green_taxi1=pd.DataFrame(pd.read_csv(‘green_tripdata_2016-01.csv’))
green_taxi2=pd.DataFrame(pd.read_csv(‘green_tripdata_2016-02.csv’))
green_taxi3=pd.DataFrame(pd.read_csv(‘green_tripdata_2016-03.csv’))
green_taxi4=pd.DataFrame(pd.read_csv(‘green_tripdata_2016-04.csv’))
green_taxi5=pd.DataFrame(pd.read_csv(‘green_tripdata_2016-05.csv’))
green_taxi6=pd.DataFrame(pd.read_csv(‘green_tripdata_2016-06.csv’))
#合并綠色出租車2016年1-6月數據
green_taxi=green_taxi1.append(green_taxi2,ignore_index=False)
green_taxi=green_taxi.append(green_taxi3,ignore_index=False)
green_taxi=green_taxi.append(green_taxi4,ignore_index=False)
green_taxi=green_taxi.append(green_taxi5,ignore_index=False)
green_taxi=green_taxi.append(green_taxi6,ignore_index=False)
通過查看維度�,拼接完的數據大表共有901萬條數據�,20個字段�。
#查看數據表維度
green_taxi.shape
(9018030, 20)
使用columns函數查看數據表中20個字段的列名稱��。通過字段名稱可以發現�����,這張數據表中包括很多信息�����,包括乘客上下車時間�����,和經緯度信息����,乘客數量����,付款方式以及行駛距離和費率等等����。
#查看數據表列名稱
green_taxi.columns
Index([‘VendorID’, ‘Lpep_dropoff_datetime’, ‘Store_and_fwd_flag’, ‘RateCodeID’,
‘Pickup_longitude’, ‘Pickup_latitude’, ‘Dropoff_longitude’,
‘Dropoff_latitude’, ‘Passenger_count’, ‘Trip_distance’, ‘Fare_amount’,
‘Extra’, ‘MTA_tax’, ‘Tip_amount’, ‘Tolls_amount’, ‘Ehail_fee’,
‘improvement_surcharge’, ‘Total_amount’, ‘Payment_type’, ‘Trip_type ‘],
dtype=’object’)
再查看一下數據表中的內容��,使用head函數查看數據表前5行的具體內容����?�?梢园l現上下車時間既包括了日期信息也包括了具體的小時信息����。付款方式則是以類別編碼進行的標識��。
#查看數據表前5行
green_taxi.head()

這里需要從NYC Taxi & Limousine Commission網站上下載一個對照文檔將字符標識還原為類別名稱����。這個在后面會用到�����,下面是文檔中的截圖���。

準備工作完成后�,開始對Green TAXI的數據開始進行分析�。
2016年1-6月使用趨勢
這是一張實時Green TAXI的位置分布圖����。Green TAXI可以從曼哈頓北部(西110街和東96街的北部)�,布朗克斯�����,皇后區(不包括機場)�,布魯克林和史坦頓島的街道上接載乘客�,并且可以在任何地方落客�����。每輛Green TAXI出租車也都可以在曼哈頓北部��,布朗克斯�����,皇后區���,布魯克林和史坦頓島和機場進行預約載客����。我們先來看下2016年1-6月的整體使用趨勢���。
我們對Green TAXI中的數據進行處理�,獲得按月的使用量變化趨勢����。首先將數據表中的載客時間字段轉化為日期格式�,然后把這個字段設置為數據表的索引字段���。并按月的維度對數據表中的數據進行匯總計數�。并提取VendorID列作為每月Green TAXI的載客數量���。
#將載客時間字段更改為時間格式
green_taxi[‘lpep_pickup_datetime’]=pd.to_datetime(green_taxi[‘lpep_pickup_datetime’])
#將載客時間字段設置為數據表的索引字段
green_taxi = green_taxi.set_index(‘lpep_pickup_datetime’)
#按月對數據表中的數據進行匯總計數
monthly=green_taxi.resample(‘M’,how=len)[‘VendorID’]
將按月的Green TAXI數據繪制為柱狀圖�����,來查看整體的變化趨勢情況�,下面是繪制趨勢圖的代碼和結果�����。
#繪制分月載客數量變化趨勢圖
plt.rc(‘font’, family=’STXihei’, size=15)
a=np.array([1,2,3,4,5,6])
plt.bar([1,2,3,4,5,6],monthly,color=’#99CC01′,alpha=0.8,align=’center’,edgecolor=’white’)
plt.xlabel(‘月份’)
plt.ylabel(‘搭乘次數’)
plt.title(‘2016年1-6月Green TAXI搭乘次數’)
plt.legend([‘搭乘次數’], loc=’upper right’)
plt.grid(color=’#95a5a6′,linestyle=’–‘, linewidth=1,axis=’y’,alpha=0.6)
plt.xticks(a,(‘1月’,’2月’,’3月’,’4月’,’5月’,’6月’))
plt.ylim(0,1800000)
plt.show()

從圖表來看���,1月2月和6月的使用量相對較低�����,3月到5月使用量相對較高�。這樣的趨勢與季節和溫度有關系嗎���?紐約冬天一般從11月到次年3月��,冷且風大����。出租車的使用量是否和氣溫有關呢�?我們這里先做一個假設��,在文章的最后再來分析�。
乘客數量分布
Green TAXI 的車型分為四種���,根據用途和載客數量不同從小到大分布為Sedan����,Town car�,Minivan和SUV����。下面我們來看下搭乘Green TAXI的乘客數量分布��。換句話說就是每次搭乘時出租車內的人數���。這里需要說明的是這個數字的采集方式是由出租車駕駛員手動輸入的����。因此可能會有一些不準確性�����。

要獲得每次搭乘出租車乘客的分布情況����,需要對數據表進行處理��。我們首先查看下搭乘人數的范圍�,查看Passenger_count的最大值和最小值�����,范圍是0-9個人���。這里就可以看出問題��。首先0人搭乘這個明顯是有問題的����。莫非是約車的時候打表來接的�����,然后又取消了訂單��?其次9個人乘坐出租車這個應該是SUV車型��,應該是包含兒童或未成年人�。否則即使是7座的SUV也很難坐下9個成年人��。
#查看每次載客的乘客數量范圍
green_taxi[‘Passenger_count’].min(),green_taxi[‘Passenger_count’].max()
(0, 9)
得到乘客數量范圍后��,我們對數據表按Passenger_count字段進行匯總計數��,并繪制乘客人數分布圖�。
#按乘客數量對數據進行計數匯總
Passenger=green_taxi.groupby(‘Passenger_count’)[‘Passenger_count’].agg(len)
下面是繪制乘客人數分布圖的代碼��。
#繪制每次搭載乘客人數分布圖
plt.rc(‘font’, family=’STXihei’, size=15)
a=np.array([0,1,2,3,4,5,6,7,8,9])
plt.bar([0,1,2,3,4,5,6,7,8,9],Passenger,color=’#99CC01′,alpha=0.8,align=’center’,edgecolor=’white’)
plt.xlabel(‘乘客數量’)
plt.ylabel(‘搭乘次數’)
plt.title(‘每次搭乘Green TAXI的乘客人數分布’)
plt.legend([‘人數’], loc=’upper right’)
plt.grid(color=’#95a5a6′,linestyle=’–‘, linewidth=1,axis=’y’,alpha=0.4)
plt.xticks(a,(‘0人’,’1人’,’2人’,’3人’,’4人’, ‘5人’,’6人’,’7人’,’8人’,’9人’))
plt.ylim(0,9000000)
plt.show()
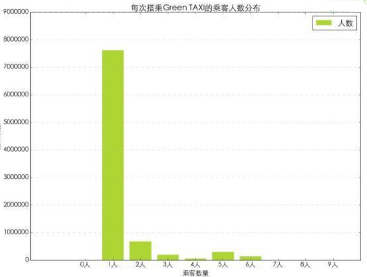
從乘客數量的分布情況來看����,獨自1人搭乘出租車的數量最多����,其次為2人���,5人��,3人和6人���。這里也有可能是出租車司機輸入時的固定選擇造成的?,F有的數據中沒有可以進行交叉驗證的數據��,因此這個乘客人數分布數據僅供參考����。
支付方式分布
Green TAXI數據表中對乘客支付車費的方式分為了6類����,通過對應文檔分別為Credit card,
Cash,No charge,Dispute,Unknown,Voided trip��。但仔細看會發現�,這并不是6種不同的支付方式��。如后面的免費��,爭議和空駛�。甚至還出現了Unknown的情況����。不過我們還是按
Payment_type字段對數據進行了匯總統計�����。下面是支付方式的統計代碼和結果�。

首先將支付方式的編號還原為具體的類別名稱�。下面是具體的代碼�����。
#對數據表中的支付方式進行標注
bins = [0, 1, 2, 3, 4, 5, 6]
group_payment = [‘Credit card’, ‘ Cash’, ‘ No charge’, ‘Dispute’, ‘Unknown’, ‘ Voided trip’]
green_taxi[‘group_payment’] = pd.cut(green_taxi[‘Payment_type’], bins, labels=group_payment)
然后按支付方式的名稱字段對數據表進行計數匯總����。
#按支付方式對數據表中的數據進行匯總計數
payment_type=green_taxi.groupby(‘group_payment’)[‘group_payment’].agg(len)
對匯總后的支付方式數據匯總圖表進行分析��。
#繪制乘客支付方式分布圖
plt.rc(‘font’, family=’STXihei’, size=15)
a=np.array([1,2,3,4,5,6])
plt.bar([1,2,3,4,5,6],payment_type,color=’#99CC01′,alpha=0.8,align=’center’,edgecolor=’white’)
plt.xlabel(‘支付方式’)
plt.ylabel(‘搭乘次數’)
plt.title(‘搭乘Green TAXI的支付方式’)
plt.legend([‘搭乘次數’], loc=’upper right’)
plt.grid(color=’#95a5a6′,linestyle=’–‘, linewidth=1,axis=’y’,alpha=0.4)
plt.xticks(a,(‘Credit card’,’Cash’,’No charge’,’Dispute’, ‘Unknown’,’Voided trip’))
plt.show()
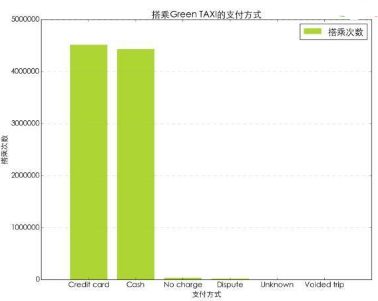
在所有的支付方式中�,現金和信用卡是乘客使用最多的支付方式��。其他的情況都很少見����。其實本來幾個類別就不是支付方式的分類����。
平均距離及里程分布
Green TAXI起步價2.5美元(0.2英里以內)�����,之后每0.2英里(約320米)或者等候2分鐘加收40美分�����。從晚間8點到早上6點期間���,加收夜行附加費0.50美元��。高峰時刻(周一到周五下午4點到8點)附加費1美元��。此外����,乘客還需承擔乘車期間產生的任何費用并另付小費(15%以上)��。這里搭乘距離是影響金額的主要因素����,我們來看下乘客在搭乘出租車時的距離分布情況���。

首先來看下乘客搭乘出租車的距離范圍���,查看Trip_distance的最大值和最小值�����。最短距離為0���,最大距離為832.2英里���。這里的0英里不知道是什么情況���。
#查看乘客搭載距離范圍
green_taxi[‘Trip_distance’].min(),green_taxi[‘Trip_distance’].max()
(0.0, 832.2)
用總的搭乘里程除以乘客搭乘次數計算出每次搭乘的平均行駛距離為2.81英里��。
#計算每位乘客平均搭載的距離
green_taxi[‘Trip_distance’].sum()/green_taxi[‘Trip_distance’].count()
2.8170580049080391
對乘客搭乘距離進行分組��,以5公里為一組進行劃分���。
#對乘客搭載距離進行分組
bins = [0, 5, 10, 50, 100, 200, 840]
group_distance = [‘0-5公里’, ‘5-10公里’, ’10-50公里’, ’50-100公里’, ‘100-200公里’, ‘200公里以上’]
green_taxi[‘group_distance’] = pd.cut(green_taxi[‘Trip_distance’], bins, labels=group_distance)
按劃分后的距離分組字段對數據表進行計數匯總�����,查看乘客搭乘的距離分布情況����。
#按分組距離對數據表進行計數匯總
group_trip_distance=green_taxi.groupby(‘group_distance’)[‘Trip_distance’].agg(len)
將乘客搭乘的距離分布數據繪制成圖表����。
#繪制乘客搭乘距離分布圖
plt.rc(‘font’, family=’STXihei’, size=15)
a=np.array([1,2,3,4,5,6])
plt.bar([1,2,3,4,5,6],group_trip_distance,color=’#99CC01′,alpha=0.8,align=’center’,edgecolor=’white’)
plt.xlabel(‘搭乘距離’)
plt.ylabel(‘搭乘次數’)
plt.title(‘乘客搭乘Green TAXI的距離分布’)
plt.legend([‘搭乘次數’], loc=’upper right’)
plt.grid(color=’#95a5a6′,linestyle=’–‘, linewidth=1,axis=’y’,alpha=0.4)
plt.xticks(a,(‘0-5公里’, ‘5-10公里’, ’10-50公里’, ’50-100公里’, ‘100-200公里’, ‘200公里以上’))
plt.show()
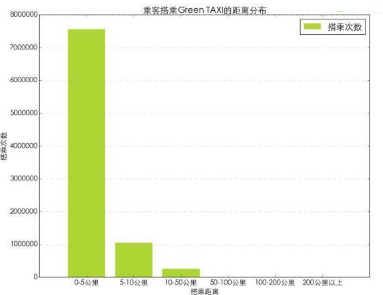
從乘客搭乘距離分布圖上來看��,0-5公里短途的數量最多����,隨著距離的增加搭乘次數明顯減少��。很明顯長途出行搭乘出租車不是一個經濟的選擇�。
乘客叫車方式偏好
Green TAXI的定位是Yellow TAXI的補充��,因此對于Green TAXI的運營區域也有嚴格的限制�,再來看下Green TAXI的載客區域��。Green TAXI可以從曼哈頓北部(西110街和東96街的北部)�,布朗克斯�,皇后區(不包括機場)�����,布魯克林和史坦頓島的街道上接載乘客��,并且可以在任何地方落客���。但在曼哈頓北部��,布朗克斯�,皇后區���,布魯克林和史坦頓島和機場這些區域����,Green TAXI只能進行預約載客��。也就是說�����,如果乘客沒有預約�����,Green TAXI就不能去這些區域載客��。下面我們來看下Green TAXI的數據中乘客叫車的方式�����。
數據表中的Trip_type字段代表了乘客召喚出租車的方式�����,1= Street-hail�,2= Dispatch�����。我們按Trip_type字段對數據進行匯總����。
#按乘客叫車方式對數據表進行計數匯總
Trip_type=green_taxi.groupby(‘Trip_type ‘)[‘Trip_type ‘].agg(len)
然后匯總乘客叫車方式的分布圖�����。以下為代碼和結果�。
#繪制乘客叫車方式分布圖
plt.rc(‘font’, family=’STXihei’, size=15)
a=np.array([1,2])
plt.bar([1,2],Trip_type,color=’#99CC01′,alpha=0.8,align=’center’,edgecolor=’white’)
plt.xlabel(‘叫車方式’)
plt.ylabel(‘搭乘次數’)
plt.title(‘乘客搭乘Green TAXI的方式’)
plt.legend([‘次數’], loc=’upper right’)
plt.grid(color=’#95a5a6′,linestyle=’–‘, linewidth=1,axis=’y’,alpha=0.4)
plt.xticks(a,(‘Street-hail’,’Dispatch’))
plt.show()
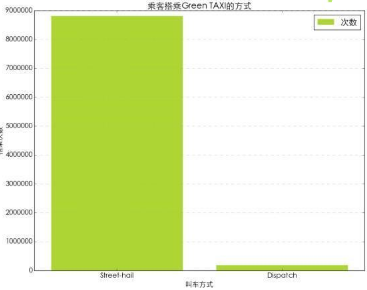
從圖表中看到���,Street-hail即乘客在路邊召喚出租車的方式是最主要的叫車方式���。Dispatch這類通過調度方式叫車的數量非常少�����。這里有一點需要說明����,2016年1月-6月除了Green TAXI和Yellow TAXI外����,還有Uber存在��。因此乘客在預約時可能更多的選擇了Uber�����,而非傳統的出租車��。這里沒有Uber同期的數據�����,僅僅是猜測���。
24小時使用趨勢(1月數據)
我們再來看下乘客在一天24小時中使用Green TAXI的情況����。這里我們只使用了2016年1月的單月數據進行分析�����。

重新導入2016年1月的數據�����,并提取出每次搭乘的小時數據��,將數據表按小時數據進行匯總����。繪制24小時Green TAXI的使用變化趨勢圖�����。
#重新導入2016年1月的數據
green_taxi1=pd.DataFrame(pd.read_csv(‘green_tripdata_2016-01.csv’))
#對載客時間進行分列���,提取載客的小時數據
time_split = pd.DataFrame((x.split(‘ ‘) for x in green_taxi1.lpep_pickup_datetime),index=green_taxi1.index,columns=[‘pickup_date’,’pickup_time’])
#將分列后的時間字段與原始數據表合并
green_taxi1=pd.merge(green_taxi1,time_split,right_index=True, left_index=True)
#對合并后的數據表中的時間字段更改為時間格式
green_taxi1[‘pickup_time’]=pd.to_datetime(green_taxi1[‘pickup_time’])
#將時間字段設置為數據表的索引字段
green_taxi1 = green_taxi1.set_index(‘pickup_time’)
#按小時對數據表進行計算匯總
pickup_time=green_taxi1.resample(‘H’,how=len)
#提取按小時匯總后的VendorID字段
group_pickup_time=pickup_time[‘VendorID’]
前面完成了24小時數據搭乘數據的匯總�����,下面的代碼繪制24小時搭乘趨勢圖���。
#繪制24小時載客趨勢圖
plt.rc(‘font’, family=’STXihei’, size=9)
plt.plot(group_pickup_time,’g8′,group_pickup_time,’g-‘,color=’#99CC01′,linewidth=3,markeredgewidth=3,markeredgecolor=’#99CC01′,alpha=0.8)
plt.xlabel(’24小時’)
plt.ylabel(‘搭乘次數’)
plt.title(‘Green TAXI 24小時搭乘次數’)
plt.ylim(0,100000)
plt.grid( color=’#95a5a6′,linestyle=’–‘, linewidth=1 ,axis=’y’,alpha=0.4)
plt.show()
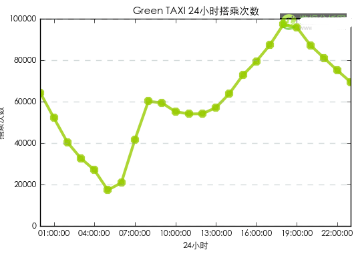
從24小時搭乘趨勢圖來看�,每日晚間是Green TAXI的使用高峰��。晚間的出租車使用量明顯高于早間�����,并且延續時間較長�,從晚間19點的用車高峰一直持續到凌晨����。
氣溫與出租車使用情況的關系
本文開始時��,我們在分析1-6月Green TAXI使用趨勢時曾假設出租車的使用與氣溫有關�����,冬季由于氣溫較低造成出租車的使用量也較低����。下面我們使用2016年1月-6月的天氣數據與出租車的搭乘數據進行相關分析��,來看下這兩者間是否有關聯�����。
首先對出租車搭乘數據進行預處理���,包括更改字段格式以及對數據進行按天匯總和提取工資���。下面是每個步驟的代碼及說明����。
#將2016年1-6月數據表中載客時間字段更改為時間格式
green_taxi[‘lpep_pickup_datetime’]=pd.to_datetime(green_taxi[‘lpep_pickup_datetime’])
#將載客時間字段設置為數據表索引列
green_taxi = green_taxi.set_index(‘lpep_pickup_datetime’)
#數據表按天匯總計數
taxi_day=green_taxi.resample(‘D’,how=len)
#提取按天匯總后的VendorID字段值
group_taxi_day=taxi_day[‘VendorID’]
導入2016年1-6月的天氣數據�����,然后從中提取最低氣溫數據����,也就是TMIN字段中的值��。用于和出租車搭乘數據進行相關分析����。
#導入天氣數據
weather_data=pd.DataFrame(pd.read_csv(‘822632.csv’))
#提取天氣數據表中最低低溫列數據
group_weather_day=weather_data[‘TMIN’]
準備好兩組數據后���,對數據進行標準化預處理���。
#導入數據預處理庫
from sklearn import preprocessing
#對天氣數據進行標準化處理
scaler = preprocessing.StandardScaler().fit(group_weather_day)
X_Standard=scaler.transform(group_weather_day)
#對出租車載客數據進行標準化處理
scaler = preprocessing.StandardScaler().fit(group_taxi_day)
Y_Standard=scaler.transform(group_taxi_day)
將預處理后的數據繪制散點圖��,下面是具體的代碼和圖表��。
#繪制出租車載客量與最低氣溫散點圖
plt.rc(‘font’, family=’STXihei’, size=15)
plt.scatter(X_Standard,Y_Standard,80,color=’white’,marker=’+’,edgecolors=’#052B6C’,linewidth=2,alpha=0.8)
plt.xlabel(‘最低氣溫’)
plt.ylabel(‘搭乘數量’)
plt.title(‘最低氣溫與Green TAXI搭乘數量’)
plt.grid(color=’#95a5a6′,linestyle=’–‘, linewidth=1,axis=’both’,alpha=0.4)
plt.show()
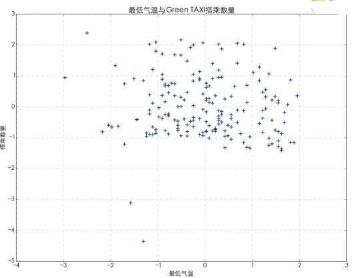
從散點圖中來看��,最低氣溫與出租車的搭乘數量間并沒有明顯的聯系�����。出租車的搭乘數量一致維持固定的區間內����,并沒有因為最低氣溫的變化有顯著的變化����。下面我們使用回歸分析計算兩者的相關性�。
將每日的最低氣溫設置為自變量X��,每日出租車的載客量設置為因變量Y����。然后使用線性回歸模型來計算判定系數R方��。
#將每日最低氣溫設置為自變量X
X = np.array(weather_data[[‘TMIN’]])
#將每日出租車載客量設置為因變量Y
Y = np.array(taxi_day[[‘VendorID’]])
#導入線性回歸模型
from sklearn import linear_model
clf = linear_model.LinearRegression()
clf.fit (X,Y)
#計算判斷系數R方
clf.score(X,Y)
0.0093570505543095761
判斷系數為0.0009��,說明自變量對因變量的解釋度較低����,換句話說最低氣溫的變化與出租車載客量間沒有聯系�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
