7行Python代碼的人臉識別
什么是詞云呢��?詞云又叫文字云���,是對文本數據中出現頻率較高的“關鍵詞”在視覺上的突出呈現��,形成關鍵詞的渲染形成類似云一樣的彩色圖片�����,從而一眼就可以領略文本數據的主要表達意思���。
現在����,可以從網絡上找到各種各樣的詞云���,下面一圖來自沈老師的微博:

從百度圖片中可以看到更多制作好的詞云����,例如

詞云制作有很多工具…..
從技術上來看����,詞云是一種有趣的數據可視化方法����,互聯網上有很多的現成的工具:
Wordle是一個用于從文本生成詞云圖而提供的游戲工具
Tagxedo 可以在線制作個性化詞云
Tagul 是一個 Web 服務����,同樣可以創建華麗的詞云
Tagcrowd 還可以輸入web的url����,直接生成某個網頁的詞云
……
十行代碼
但是作為一個老碼農����,還是喜歡自己用代碼生成自己的詞云�,復雜么�?需要很長時間么�? 很多文字都介紹過各種的方法�,但實際上只需要10行Python代碼即可�。
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
text_from_file_with_apath = open('/Users/hecom/23tips.txt').read()
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all = True)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud = WordCloud().generate(wl_space_split)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
如此而已��,生成的一個詞云是這樣的:

看一下這10行代碼:
1~3 行分別導入了畫圖的庫��,詞云生成庫和jieba的分詞庫�;
4 行是讀取本地的文件,代碼中使用的文本是本公眾號中的《老曹眼中研發管理二三事》�。
5~6 行使用jieba進行分詞�����,并對分詞的結果以空格隔開��;
7行對分詞后的文本生成詞云����;
8~10行用pyplot展示詞云圖�����。
這是我喜歡python的一個原因吧����,簡潔明快��。
執行環境
如果這十行代碼沒有運行起來���,需要檢查自己的執行環境了��。
對于面向python 的數據分析而言���,個人喜歡Anaconda�,可以下載安裝�����,安裝成功后的運行界面如下:
anaconda 是python 數據愛好者的福音�。
安裝wordcloud 和 jieba 兩個庫同樣非常簡單:
pip install wordcloud
pip install jieba
遇到的一個小坑����,剛開始運行這十行代碼的時候���,只顯式了若干彩色的小矩形框�����,中文詞語顯式不出來����,以為是萬惡的UTF8問題����,debug一下���,發現print 結巴分詞的結果是可以顯示中文的���,那就是wordcloud 生成詞語的字體庫問題了����。開源的好處來了���,直接進入wordcloud.py 的源碼�,找字體庫相關的代碼
FONT_PATH = os.environ.get("FONT_PATH", os.path.join(os.path.dirname(__file__), "DroidSansMono.ttf"))
wordcloud 默認使用了DroidSansMono.ttf 字體庫��,改一下換成一個支持中文的ttf 字庫�����, 重新運行一下這十行代碼�,就可以了����。
看一下源碼
既然進入了源碼����,就會忍不住好奇心��,瀏覽一下wordcloud 的實現過程和方式吧����。
wordcloud.py總共不過600行�����,其間有著大量的注釋�����,讀起來很方便���。其中用到了較多的庫���,常見的random��,os�����,sys�,re(正則)和可愛的numpy���,還采用了PIL繪圖����,估計一些人又會遇到安裝PIL的那些坑.
生產詞云的原理其實并不復雜�,大體分成5步:
對文本數據進行分詞�,也是眾多NLP文本處理的第一步��,對于wordcloud中的process_text()方法�����,主要是停詞的處理
計算每個詞在文本中出現的頻率�����,生成一個哈希表��。詞頻計算相當于各種分布式計算平臺的第一案例wordcount����, 和各種語言的hello world 程序具有相同的地位了����,呵呵��。
根據詞頻的數值按比例生成一個圖片的布局��,類IntegralOccupancyMap 是該詞云的算法所在���,是詞云的數據可視化方式的核心����。
將詞按對應的詞頻在詞云布局圖上生成圖片��,核心方法是generate_from_frequencies,不論是generate()還是generate_from_text()都最終到generate_from_frequencies
完成詞云上各詞的著色,默認是隨機著色
詞語的各種增強功能大都可以通過wordcloud的構造函數實現����,里面提供了22個參數���,還可以自行擴展�。
更多的小例子
看看一個準文言文的詞云��,本字來自本公眾號去年的舊文——妻

其中在構造函數中傳入了關于大小的幾個參數
width=800,height=400,max_font_size=84,min_font_size=16
自慚形穢�,根本看不出文言文的色彩和對妻子的感情流露��,不是好文字呀���!
矩形的詞云太簡陋了����,直接在圖片上用詞云來填充就有意思多了��,wordcloud中采用的mask方式來實現的���。換上一張自己的照片�,用在談《全棧架構師》中的文字�,詞云出來的效果是這樣的

較難看出肖像的特點了�����,還好���,可以遮丑�����。其中增加了3行代碼
from PIL import Image
import numpy as np
abel_mask = np.array(Image.open("/Users/hecom/chw.png"))
在構造函數的時候���,將mask傳遞進去即可:
background_color="black", mask=abel_mask
自己做的這些詞云圖片還是太陋�����,這就是原型簡單���,好的產品困難呀�����!做好一個漂亮詞云的圖片�,還是要在諸多細節上下功夫的����。
例如:
分詞的處理�,“就是”這樣沒有意義的詞不應該出現在詞云里呀��?
所展示關鍵詞的目的性選擇���?
如何選擇一個合適的字庫����?
如何更好地自主著色�?
圖片的預處理�����,如何讓圖片和詞云表達原圖片的主要特征��?
……
詞云的背后
詞云的背后實際上是數據集成處理的典型過程���,我們所熟知的6C,如下圖:
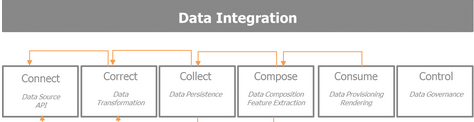
Connect: 目標是從各種各樣數據源選擇數據���,數據源會提供APIs,輸入格式,數據采集的速率,和提供者的限制.
Correct: 聚焦于數據轉移以便于進一步處理�,同時保證維護數據的質量和一致性
Collect: 數據存儲在哪��,用什么格式���,方便后面階段的組裝和消費
Compose: 集中關注如何對已采集的各種數據集的混搭, 豐富這些信息能夠構建一個引入入勝的數據驅動產品�����。
Consume: 關注數據的使用�、渲染以及如何使正確的數據在正確的時間達到正確的效果�����。
Control: 這是隨著數據����、組織�、參與者的增長����,需要的第六個附加步驟���,它保證了數據的管控����。?
這十行代碼構建的詞云���,沒有通過API從公眾號直接獲取,簡化和抽象是工程化的典型方式�,這里至今復制粘貼���,甚至省略了correct的過程��,直接將數據存儲在純文本文件中����,通過jieba分詞進行處理即compose�,使用詞云生成可視化圖片用于消費consume��,把一個個自己生成的詞云組織到不同的文件目錄便于檢索算是初步的管控control吧�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
